1. Utwórz bazę o nazwie „test 2. Zaimportuj strukturę i...
29
1. Utwórz bazę o nazwie „test” 2. Zaimportuj strukturę i dane z pliku baza_test.txt 3. Powyższy zbiór poleceo SQL utworzony w bazie tablice i wpiszę ich zawartości wg poniżeszego schematu: Pobieranie danych z pojedynczych tabel W tym odcinku po raz pierwszy spojrzymy na tabele jako na zbiory danych, poznamy język SQL i nauczymy się odczytywać, wybierać i sortować dane zapisane w pojedynczych tabelach. Wprowadzenie Podstawowe obiekty relacyjnych baz danych — tabele — i główny język programowania tych baz — SQL — wymagają krótkiego przedstawienia. Tabele jako zbiory danych
Transcript of 1. Utwórz bazę o nazwie „test 2. Zaimportuj strukturę i...
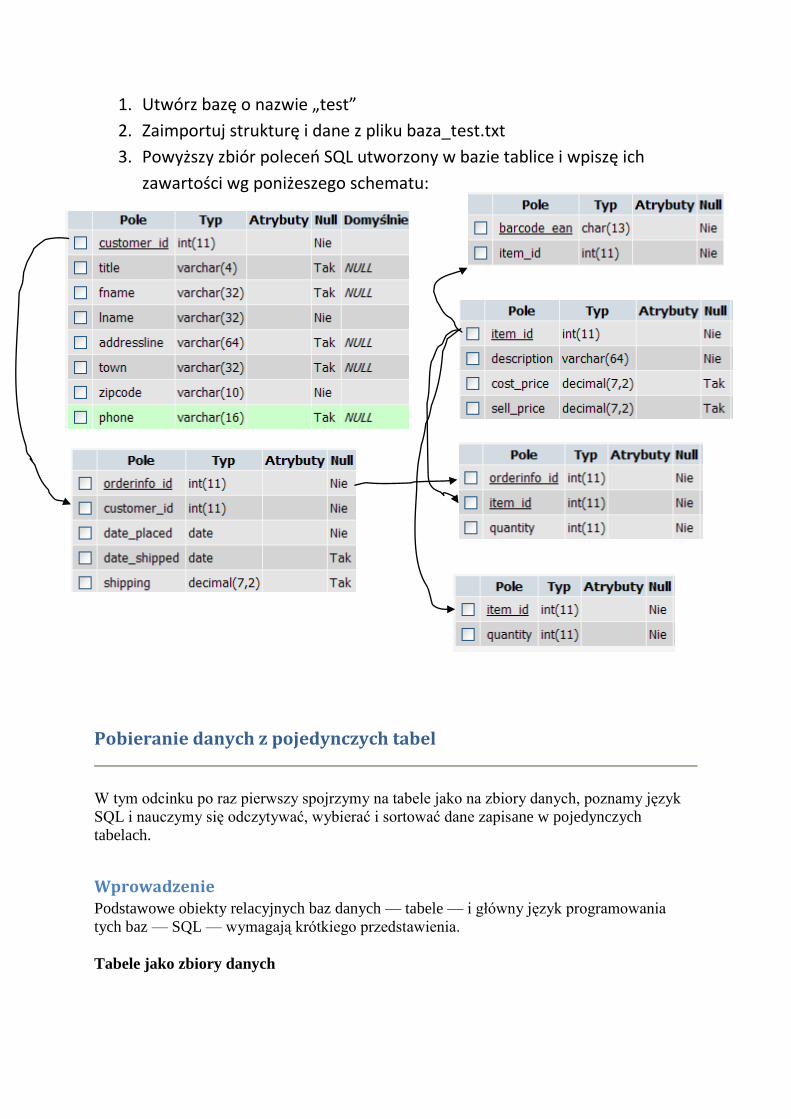
1. Utwórz bazę o nazwie „test”
2. Zaimportuj strukturę i dane z pliku baza_test.txt
3. Powyższy zbiór poleceo SQL utworzony w bazie tablice i wpiszę ich
zawartości wg poniżeszego schematu:
Pobieranie danych z pojedynczych tabel
W tym odcinku po raz pierwszy spojrzymy na tabele jako na zbiory danych, poznamy język
SQL i nauczymy się odczytywać, wybierać i sortować dane zapisane w pojedynczych
tabelach.
Wprowadzenie Podstawowe obiekty relacyjnych baz danych — tabele — i główny język programowania
tych baz — SQL — wymagają krótkiego przedstawienia.
Tabele jako zbiory danych

Podstawową cechą relacyjnych baz danych jest to, że przechowywane informacje są dostępne
jako zbiór dwuwymiarowych tabel. Czyli niezależnie od tego, w jakiej postaci (z reguły jest
to postać binarna) serwer baz danych przechowuje na dysku i w pamięci dane, użytkownicy
„widzą” je w postaci tabelarycznej.
Każda tabela musi mieć unikatową w skali schematu (w przypadku MySQL-a schemat i
baza są tym samym) nazwę. Nazwę obiektu bazodanowego można poprzedzić nazwą
schematu, w którym ten obiekt się znajduje, tak więc pełną nazwą tabeli customer będzie
test.customer.
Każda tabela składa się z kolumn i wierszy. Poszczególne kolumny muszą mieć określoną
nazwę, a w każdej z nich można przechowywać dane określonego typu. Na przykład, w
kolumnie fname tabeli customer można zapisać do 32 znaków, w kolumnie title
przechowywane są ciągi znaków o długości dokładnie 4 znaków — jeżeli tytuł jakiegoś
klienta jest krótszy, zostanie uzupełniony spacjami. Natomiast poszczególne wiersze
zawierają dane opisujące dany obiekt. Na przykład, jeden wiersz tabeli customer przechowuje
imię, nazwisko, tytuł, adres, numer telefonu i identyfikator klienta.
Tabele w relacyjnej bazie danych mają następujące właściwości:
Nazwa kolumn musi być unikatowa w skali tabeli — próba utworzenia tabeli z kilkoma
tak samo nazywającymi się kolumnami zakończy się błędem.
Kolejność wierszy jest nieokreślona i nieistotna — to, że informacje o kliencie Jenny
Stones znajdują się w pierwszym, a nie, na przykład, trzecim wierszu, nie ma żadnego
znaczenia.
Kolejność kolumn jest nieokreślona, ale ma wpływ na sposób prezentowania danych —
gdyby dane o numerze telefonu znajdowały się w pierwszej, a nie ostatniej kolumnie,
dalej byłyby to te same dane, ale zapytania mogłyby uwzględnić zmienioną kolejność
kolumn.
Wiersze w tabeli muszą być różne — na przykład, gdybyśmy chcieli wprowadzić drugi
raz informację o tym samym kliencie, musielibyśmy dodać kolejny wiersz. W
matematycznym modelu relacyjnych baz danych przyjmuje się, że dwa identyczne
elementy zbioru są tak naprawdę jednym elementem, natomiast w tabeli identyczne dane
przechowywane są w różnych wierszach.
Pobieranie danych Informacje przechowywane w bazach danych mogą zostać pobrane za pomocą instrukcji
języka SQL SELECT. Instrukcja SELECT (zapytanie) określa, jakie dane mają zostać
zwrócone w wyniku jej wykonania, natomiast to, w jaki sposób instrukcja zostanie
wykonana, zależy od serwera baz danych.
Język SQL jest językiem
strukturalnym, a nie
proceduralnym. W tym języku nie
określamy sposobu wykonania
zadania (tak jak np. w C), ale jego
wynik (a właściwie wymagane do

jego otrzymania operacje na
pewnych strukturach — zbiorach).
Z założenia instrukcje języka SQL
przypominają potoczny język
angielski. Na przykład, żeby
odczytać nazwę i cenę produktu,
nie napiszemy programu za
pomocą jakiegoś algorytmu
wyszukiwania znajdującego
odpowiednie informacje, ale po
prostu powiemy: Odczytaj nazwę i
cenę produktu o podanym
identyfikatorze.
Instrukcja SELECT służy do pobierania danych z bazy. Instrukcja musi zawierać (z
wyjątkiem polecenia SELECT odwołującego się wyłącznie do stałych, zmiennych lub
wyrażeń arytmetycznych) co najmniej jedną klauzulę: za pomocą polecenia SELECT
określamy interesujące nas kolumny (dokonujemy operacji selekcji pionowej, projekcji),
za pomocą klauzuli FROM wskazujemy tabelę, z której pobieramy dane. Z reguły ogranicza
się również, za pomocą klauzuli WHERE, liczbę zwracanych wierszy do rekordów
spełniających określone kryteria (operacja selekcji poziomej, selekcji).
Odczytujemy wszystkie dane z tabeli
Najprostszy przykład użycia instrukcji SELECT to odczytanie całej zawartości wskazanej
tabeli. W SQL-u możemy posługiwać się kilkoma znakami specjalnymi, jednym z nich
jest * oznaczająca „wszystko”. Czyli żeby odczytać wszystko z tabeli customer, należy
wykonać instrukcję:
SELECT * FROM customer;
albo:
SELECT * FROM test.customer;
Wszystkie instrukcje SQL należy
wykonywać w wyniku łączenia się
jako administrator testowej bazy
za pomocą programu MySQL
Query Browser albo tekstowego
programu mysql. W drugim
przypadku po połączeniu z
serwerem trzeba określić bazę
danych przez wpisanie USE test;.
Kolejność kolumn wyniku zawsze odpowiada kolejności kolumn tabeli. Natomiast nie

należy zakładać, że ponowne wykonanie tej samej instrukcji zwróci wiersze w tej samej
kolejności.
Porządkowanie danych
Instrukcja SELECT zwraca wiersze w tej kolejności, w jakiej dane są przechowywane w tabeli.
Z reguły jest to kolejność, w jakiej były dopisywane następne wiersze z danymi. Do zmiany
kolejności, w jakiej zwracane będą wyniki zapytania służy klauzula ORDER BY. ORDER BY
(uporządkuj według) jest opcjonalnym składnikiem instrukcji SELECT. Jeżeli jednak ta
klauzula wystąpi, musi być ostatnią.
Kolejność klauzul instrukcji SELECT nie jest dowolna.
Obowiązkowym parametrem klauzuli ORDER BY jest wyrażenie lub nazwa kolumny, według
wartości których należy posortować dane wynikowe. Wykonanie poniższej instrukcji
spowoduje wyświetlenie opisów towarów i cen ich zakupu uszeregowanych według cen
zakupu (listing 3.14).
Listing 3.14. Posortowana lista towarów
SELECT description, cost_price
FROM item
ORDER BY cost_price;
+--++
| description | cost_price |
+--++
| SQL Server 2005 | NULL |
| Carrier Bag | 0.01 |
| Toothbrush | 0.75 |
| Linux CD | 1.99 |
| Tissues | 2.11 |
| Roman Coin | 2.34 |
| Rubik Cube | 7.45 |
| Picture Frame | 7.54 |
| Fan Small | 9.23 |
| Fan Large | 13.36 |
| Wood Puzzle | 15.23 |
| Speakers | 19.73 |
+--++
Domyślnie dane szeregowane są w porządku rosnącym, czyli od wartości najmniejszych do
największych w przypadku danych liczbowych, od najwcześniejszych do najpóźniejszych w
przypadku dat oraz w porządku alfabetycznym w przypadku ciągów znakowych. Aby
odwrócić kolejność sortowania, należy bezpośrednio po nazwie kolumny użyć słowa
kluczowego DESC (ang. Descending) (listing 3.15).
Listing 3.15. Lista towarów posortowana od najdroższego do najtańszego
SELECT description, cost_price
FROM item
ORDER BY cost_price
DESC;
+--++
| description | cost_price |

+--++
| Speakers | 19.73 |
| Wood Puzzle | 15.23 |
| Fan Large | 13.36 |
| Fan Small | 9.23 |
| Picture Frame | 7.54 |
| Rubik Cube | 7.45 |
| Roman Coin | 2.34 |
| Tissues | 2.11 |
| Linux CD | 1.99 |
| Toothbrush | 0.75 |
| Carrier Bag | 0.01 |
| SQL Server 2005 | NULL |
+--++
Poszczególne klauzule instrukcji SELECT są od siebie niezależne. To znaczy, że w klauzuli
ORDER BY możemy użyć wyrażenia lub nazwy kolumny, która nie występuje w klauzuli
SELECT (listing 3.16).
Listing 3.16. Lista nazw towarów posortowana według cen ich zakupu
SELECT description FROM item ORDER BY cost_price;
+--+
| description |
+--+
| SQL Server 2005 |
| Carrier Bag |
| Toothbrush |
| Linux CD |
| Tissues |
| Roman Coin |
| Rubik Cube |
| Picture Frame |
| Fan Small |
| Fan Large |
| Wood Puzzle |
| Speakers |
+--+
Oczywiście możemy sortować dane według więcej niż jednego kryterium. Instrukcja z
listingu 3.17 zawiera alfabetycznie uporządkowaną listę adresów klientów — najpierw dane
sortowane są według nazw miast, a następnie według nazw ulic.
Listing 3.17. Jeżeli kilku klientów mieszka w tym samym mieście, o ich kolejności na liście
zadecyduje nazwa i numer ulicy
SELECT town, addressline
FROM customer
ORDER BY town, addressline;
+--+-+
| town | addressline |
+--+-+
| | |
| Bingham | 34 Holly Way |
| Bingham | 34 Holly Way |
| Bingham | 54 Vale Rise |

| Hightown | 27 Rowan Avenue |
| Histon | 36 Queen Street |
| Lowtown | 52 The Willows |
| Milltown | 4 The Square |
| Nicetown | 4 The Street |
| Nicetown | 5 Pasture Lane |
| Oahenham | 7 Shady Lane |
| Oxbridge | 73 Margeritta Way |
| Tibsville | 86 Dysart Street |
| Welltown | 2 Beamer Street |
| Winersby | 42 Thached way |
| Yuleville | The Barn |
+--+-+
Wybieranie wierszy
Instrukcje SELECT w tej postaci, której używaliśmy do tej pory, zwracały wszystkie wiersze z
danej tabeli. Do ograniczenia (wybrania) wierszy w wyniku należy użyć klauzuli WHERE. Ta
klauzula odpowiada teoriomnogościowemu operatorowi selekcji, czyli wybierania wierszy.
Operacja ta najczęściej polega na wyborze, na podstawie pewnych kryteriów, grupy wierszy z
tabeli. Serwer baz danych dla każdego wiersza sprawdzi, czy spełnia on kryteria wyboru, i
jeżeli tak — zostanie on dodany do wyniku zapytania.
Klauzula WHERE, o ile została użyta, musi wystąpić bezpośrednio po klauzuli FROM. Kryterium
wyboru może zostać sformułowane za pomocą typowych operatorów porównania lub
operatorów charakterystycznych dla języka SQL.
Typowe operatory porównania Operatory logiczne porównują, czy dany warunek jest spełniony, czyli czy w wyniku
porównania argumentów otrzymamy wartość logiczną True (Prawda). Na przykład,
wszystkie poniższe warunki są prawdziwe: 1<4, 2=2, 5>=5, 'mama'='mama' itd.
Zwróćmy uwagę, że ciągi znaków muszą być umieszczone wewnątrz apostrofów. Domyślnie
MySQL przy porównywaniu ciągów znaków nie rozróżnia wielkich i małych liter (listing
3.18).
Listing 3.18. Wynikiem porównania wyrazów kot i KOT jest wartość prawda
SELECT 'kot' = 'KOT';
++
| 'kot' = 'KOT' |
++
| 1 |
++
Na przykład, aby wybrać tylko te towary, których cena zakupu nie przekracza 5 zł, należy
wykonać instrukcję z listingu 3.19.
Listing 3.19. Prosty test logiczny wybierający towary o określonej cenie zakupu
SELECT * FROM item WHERE cost_price <=5;
++-+++
| item_id | description | cost_price | sell_price |
++-+++
| 3 | Linux CD | 1.99 | 2.49 |

| 4 | Tissues | 2.11 | 3.99 |
| 8 | Toothbrush | 0.75 | 1.45 |
| 9 | Roman Coin | 2.34 | 2.45 |
| 10 | Carrier Bag | 0.01 | 0.00 |
++-+++
Zwróć uwagę, że w wyniku nie znalazł się towar o
nieokreślonej nazwie. Pamiętaj że wartość Null ma
specjalne znaczenie i nie można jej sensownie używać z
operatorami mniejszy czy równy.
Aby ograniczyć liczbę informacji o interesujących nas towarach (towarach kupionych za nie
więcej niż 5 zł) do ich nazwy i obu cen (zakupu i sprzedaży), należy połączyć w jednej
instrukcji operacje projekcji i selekcji. Dodatkowo, wykorzystując klauzulę ORDER BY,
możemy posortować wynik zapytania w kolejności od towarów kupionych najtaniej do
kupionych najdrożej. Zmodyfikowane polecenie SELECT powinno wyglądać następująco
(listing 3.20).
Listing 3.20. Przykład wykorzystania poznanych do tej pory wiadomości o instrukcji SELECT
SELECT description, cost_price, sell_price
FROM item
WHERE cost_price <=5 ORDER BY cost_price;
+-+++
| description | cost_price | sell_price |
+-+++
| Carrier Bag | 0.01 | 0.00 |
| Toothbrush | 0.75 | 1.45 |
| Linux CD | 1.99 | 2.49 |
| Tissues | 2.11 | 3.99 |
| Roman Coin | 2.34 | 2.45 |
+-+++
Język SQL pozwala również na użycie nazw kolumn po obu stronach operatora porównania.
Na przykład, aby wyświetlić informacje o tych towarach, które sprzedajemy poniżej ceny
zakupu, napiszemy (listing 3.21).
Listing 3.21. Porównanie danych odczytanych z tabeli. Serwer baz danych sprawdzi ten
warunek dla każdego wiersza tabeli
SELECT * FROM item WHERE cost_price > sell_price;
++-+++
| item_id | description | cost_price | sell_price |
++-+++
| 10 | Carrier Bag | 0.01 | 0.00 |
++-+++
Dopuszcza również tworzenie bardziej skomplikowanych, wykorzystujących operatory AND
(logiczne i, koniunkcja), OR (logiczne lub, alternatywa) oraz NOT (logiczne nie, negacja),
warunków logicznych. Wynik operacji porównania obliczany jest na podstawie tabel

prawdziwości danego operatora. Tabele prawdziwości dla operatorów NOT, AND i OR
przedstawione są na rysunku 3.1. Wartość 1 odpowiada prawdzie, 0 — fałszowi.
Rysunek 3.1. Tabele prawdziwości operatorów logicznych
Listing 3.22 pokazuje przykład użycia złożonego warunku logicznego — w wyniku zapytania
znajdą się tylko te zamówienia, które zostały złożone przed końcem czerwca 2000 roku przez
klienta o identyfikatorze 8.
Listing 3.22. Koniunkcja ogranicza wiersze wyniku
SELECT * FROM orderinfo WHERE customer_id=8 AND date_placed <'2000-06-30';
+--+-+-+--+-+
| orderinfo_id | customer_id | date_placed | date_shipped | shipping |
+--+-+-+--+-+
| 2 | 8 | 2000-06-23 | 2000-06-23 | 0.00 |
+--+-+-+--+-+
Specjalne znaczenie wśród operatorów logicznych ma operator negacji. W przeciwieństwie
do pozostałych operatorów logicznych, jest operatorem jednoargumentowym, to znaczy, że
do obliczenia wyniku wystarczy podać jeden argument. Jak wynika z tabeli prawdziwości,
wynik operacji NOT a jest prawdą wtedy i tylko wtedy, gdy argument a był fałszywy.
Operator negacji służy do zaprzeczania warunkom podanym w klauzuli WHERE (listing
3.23).
Listing 3.23. Zapytanie zwracające informacje o mężczyznach spoza Lowtown
SELECT title, fname, lname, town
FROM customer
WHERE title = 'Mr' AND town !='Lowtown';
+-+++--+
| title | fname | lname | town |
+-+++--+
| Mr | Adrian | Matthew | Yuleville |
| Mr | Simon | Cozens | Oahenham |
| Mr | Neil | Matthew | Nicetown |
| Mr | Richard | Stones | Bingham |
| Mr | Mike | Howard | Tibsville |
| Mr | Dave | Jones | Bingham |
| Mr | Richard | Neill | Winersby |
| Mr | Bill | Neill | Welltown |
| Mr | David | Hudson | Milltown |
+-+++--+

Oczywiście, w klauzuli WHERE, tak jak w klauzulach SELECT czy ORDER BY, możemy używać
wyrażeń. W efekcie możemy łatwo wybrać na przykład informacje o tych towarach, które
sprzedajemy z ponad 50% marżą (listing 3.24).
Listing 3.24. Przykład wykorzystania wyrażenia w klauzuli WHERE
SELECT * FROM item WHERE sell_price>=1.5*cost_price;
++-+++
| item_id | description | cost_price | sell_price |
++-+++
| 2 | Rubik Cube | 7.45 | 11.49 |
| 4 | Tissues | 2.11 | 3.99 |
| 6 | Fan Small | 9.23 | 15.75 |
| 8 | Toothbrush | 0.75 | 1.45 |
++-+++
Pobieranie danych z wielu tabel
W tym odcinku nauczymy się odczytywać dane zapisane w różnych tabelach, poznamy
różnice pomiędzy złączeniem wewnętrznym a złączeniami zewnętrznymi i dowiemy się, jak
przeprowadzać na tabelach operacje na zbiorach, znane z lekcji matematyki.
Wprowadzenie
Cechą charakterystyczną relacyjnych baz danych jest przechowywanie informacji
podzielonych między wiele tabel. W wielu wypadkach, w trakcie wyszukiwania informacji
w bazie danych, okazuje się, że potrzebne dane przechowywane są w kilku tabelach. Aby
sensownie połączyć w jednym zapytaniu dane z wielu tabel, wymagane jest ich złączenie
(ang. Join). O złączeniu tabel możemy myśleć jako o następującej operacji (w rzeczywistości
serwery baz danych optymalizują łączenie tabel):
Pierwszym etapem jest obliczenie wyniku iloczynu kartezjańskiego łączonych tabel —
kombinacji wszystkich wierszy z pierwszej tabeli z wszystkimi wierszami z drugiej tabeli.
Jeśli każda tabela zawiera tylko jeden wiersz, to wynik iloczynu kartezjańskiego też będzie
miał jeden wiersz. W przypadku tabel o 5 wierszach, wynik iloczynu kartezjańskiego wynosi
25 wierszy. Iloczyn kartezjański trzech tabel o, odpowiednio, 30, 100 i 10 wierszach daje
w wyniku tabelę z 30 000 wierszy. Ten ogromny zbiór stanowi podstawę dla dalszego
wykonywania zapytania. Przede wszystkim usuwane są z niego wiersze niespełniające
warunku złączenia. Dzięki temu pozbywamy się ogromnej liczby powtórzonych i
bezsensownych kombinacji danych. Kolejny krok polega na wykonaniu ograniczeń
wynikających z klauzul WHERE i HAVING. Wszystkie wiersze, które nie spełniają określonych
w nich warunków są odrzucane. Końcowym etapem jest wybranie z tabeli kolumn zawartych
w klauzuli SELECT i wykonanie odpowiedniej projekcji.
Z reguły łączy się tabele na podstawie wartości wspólnego atrybutu, na przykład wartości
pary klucz podstawowy-klucz obcy. W takim przypadku musimy użyć jednoznacznego
identyfikatora obiektu (kolumny). Ponieważ nazwy kolumn zawierających klucz podstawowy

i obcy najczęściej są takie same, musimy poprzedzać nazwy kolumn nazwami tabel. Możemy
poprawić czytelność zapytania, stosując aliasy dla nazw tabel.
Łącząc tabele, stosujemy się do następujących wskazówek:
1. Staramy się łączyć tabele za pomocą kolumn przechowujących parę kluczy
podstawowy-obcy.
2. Do złączenia używamy całych kluczy podstawowych tabel. Jeżeli dla jakiejś tabeli
zdefiniowano złożony (składający się z kilku atrybutów) klucz podstawowy, łącząc
taką tabelę, odwołujemy się do całego klucza;
3. Łączymy obiekty za pomocą kolumn tego samego typu.
4. Poprzedzamy nazwy kolumn aliasem nazwy obiektu źródłowego, nawet jeżeli ich
nazwy są unikatowe — w ten sposób poprawimy czytelność zapytania.
5. Ograniczamy liczbę łączonych obiektów do niezbędnego minimum.
Złączenie naturalne Wynikiem złączenia naturalnego jest zbiór wierszy łączonych tabel, dla których wartości
kolumn określonych jako warunek złączenia są takie same. Ponieważ w relacyjnych
bazach danych informacje są podzielone pomiędzy tabele zawierające dane o obiektach
jednego typu, złączenie naturalne jest najczęściej wykorzystywanym (i domyślnym)
złączeniem obiektów.
W przykładowej bazie danych informacje o klientach, zamówieniach, towarach i stanach
magazynowych przechowywane są w powiązanych ze sobą tabelach. Dlatego, żeby
odczytać na przykład daty składania przez poszczególnych klientów zamówień, musimy
odwołać się do dwóch tabel — nazwę klienta odczytamy z tabeli customer, a datę złożenia
zamówienia — z tabeli orderinfo. Przy czym z reguły nie chodzi nam o uzyskanie
poniższego wyniku (listing 4.1).
Listing 4.1. Odwołując się do wielu tabel, powinniśmy określić warunek złączenia,
inaczej wynik będzie zawierał wszystkie kombinacje wierszy wymienionych tabel
(iloczyn kartezjański). W tym przypadku tabela customer liczy 16, a tabela orderinfo 5
wierszy
SELECT lname, date_placed
FROM customer, orderinfo;
++-+
| lname | date_placed |
++-+
| Stones | 2000-03-13 |
| Stones | 2000-06-23 |
| Stones | 2000-09-02 |
| Stones | 2000-09-03 |
| Stones | 2000-07-21 |
| Stones | 2000-03-13 |
| Stones | 2000-06-23 |
| Stones | 2000-09-02 |
| Stones | 2000-09-03 |
| Stones | 2000-07-21 |
| Matthew | 2000-03-13 |
…
| Wolski | 2000-07-21 |
++-+
80 rows in set

Poprawnie napisana instrukcja powinna zwrócić nam tylko daty zamówień złożonych
przez danego klienta. Żeby to osiągnąć, musimy określić warunek złączenia, czyli
poinformować serwer baz danych, co łączy zapisane w obu tabelach dane. W tym
przypadku jest to identyfikator klienta — zwróć uwagę, że kolumna customer_id
występuje w obu tabelach, czyli na podstawie tego identyfikatora jesteśmy w stanie
sensownie połączyć informacje o klientach z informacjami o zamówieniach (listing 4.2).
Listing 4.2. Poprawne zapytanie zwracające nazwiska klientów i daty złożenia przez nich
zamówień
SELECT lname, date_placed
FROM customer INNER JOIN orderinfo
ON customer.customer_id = orderinfo.customer_id;
++-+
| lname | date_placed |
++-+
| Matthew | 2000-03-13 |
| Stones | 2000-06-23 |
| Hudson | 2000-09-02 |
| Hendy | 2000-09-03 |
| Stones | 2000-07-21 |
++-+
Złączenie naturalne pozwoli nam również odczytać kody poszczególnych towarów.
Jednak tym razem użyjemy nieco innej składni — zamiast dość „rozwlekłej” klauzuli ON,
skorzystamy z jej bardziej zwięzłego odpowiednika — klauzuli USING (listing 4.3).
Listing 4.3. Złączenie naturalne za pomocą klauzuli USING
SELECT description, barcode_ean
FROM barcode INNER JOIN item
USING (item_id);
+++
| description | barcode_ean |
+++
| Wood Puzzle | 6241527836173 |
| Rubik Cube | 6241574635234 |
| Linux CD | 6241527746363 |
| Linux CD | 6264537836173 |
| Tissues | 7465743843764 |
| Picture Frame | 3453458677628 |
| Fan Small | 6434564564544 |
| Fan Large | 8476736836876 |
| Toothbrush | 6241234586487 |
| Toothbrush | 9473625532534 |
| Toothbrush | 9473627464543 |
| Roman Coin | 4587263646878 |
| Speakers | 2239872376872 |
| Speakers | 9879879837489 |
+++

Klauzule ON i USING są różnymi sposobami na
podanie warunku złączenia, czyli wskazania
wspólnych kolumn łączonych tabel.
Złączenia zewnętrzne Złączenie naturalne eliminuje z wyniku niepasujące (niespełniające warunku złączenia)
wiersze. To dobrze, bo w innym przypadku otrzymalibyśmy zawierający mnóstwo powtórzeń
i niepotrzebnych danych iloczyn kartezjański. Ale z drugiej strony, ten sam warunek
złączenia usunął z wyniku rekordy niemające odpowiedników w łączonej tabeli. Czyli wynik
poniższej instrukcji wcale nie musi zawierać danych wszystkich naszych klientów (listing
4.6).
Listing 4.6. W wyniku złączenia naturalnego nie znajdziemy nazwisk klientów, którzy nie
złożyli przynajmniej jednego zamówienia
SELECT lname, date_placed
FROM customer INNER JOIN orderinfo
ON customer.customer_id = orderinfo.customer_id;
++-+
| lname | date_placed |
++-+
| Matthew | 2000-03-13 |
| Stones | 2000-06-23 |
| Hudson | 2000-09-02 |
| Hendy | 2000-09-03 |
| Stones | 2000-07-21 |
++-+
Czasami chcielibyśmy uzyskać komplet danych z jednej tabeli, nawet jeżeli nie są one
powiązane z danymi w innych tabelach. Umożliwia nam to złączenie zewnętrzne. Wynikiem
lewo- lub prawostronnego złączenia zewnętrznego jest zbiór wierszy łączonych tabel, dla
których wartości kolumn określonych jako warunek złączenia są takie same; zbiór ten
uzupełniony jest pozostałymi wierszami z lewej lub prawej łączonej tabeli. Nieistniejące
wartości reprezentowane są w wyniku złączenia przez wartość NULL (listing 4.7).
Listing 4.7. Kompletna, ale zawierająca powtórzenia lista nazwisk klientów i dat złożenia
przez nich zamówień
SELECT lname, date_placed
FROM customer LEFT OUTER JOIN orderinfo
ON customer.customer_id = orderinfo.customer_id;
++-+
| lname | date_placed |
++-+
| Stones | |
| Stones | |
| Matthew | 2000-03-13 |
| Matthew | |
| Cozens | |
| Matthew | |
| Stones | |
| Stones | 2000-06-23 |

| Stones | 2000-07-21 |
| Hickman | |
| Howard | |
| Jones | |
| Neill | |
| Hendy | 2000-09-03 |
| Neill | |
| Hudson | 2000-09-02 |
| Wolski | |
++-+
Złączenia zewnętrzne wykorzystywane są do
wyświetlania kompletnych informacji o wszystkich
obiektach danego typu, nawet jeżeli nie istnieją
powiązane z nimi obiekty innego typu.
Wykorzystując wiadomości z poprzedniego odcinka kursu, możemy uporządkować tę listę
(listing 4.8).
Listing 4.8. Finalna wersja instrukcji zwracającej nazwiska wszystkich klientów i daty
składania przez nich zamówień
SELECT DISTINCT lname, date_placed
FROM customer LEFT JOIN orderinfo
USING (customer_id)
ORDER BY lname;
++-+
| lname | date_placed |
++-+
| Cozens | |
| Hendy | 2000-09-03 |
| Hickman | |
| Howard | |
| Hudson | 2000-09-02 |
| Jones | |
| Matthew | |
| Matthew | 2000-03-13 |
| Neill | |
| Stones | |
| Stones | 2000-07-21 |
| Stones | 2000-06-23 |
| Wolski | |
++-+
Złączenie krzyżowe Wynikiem złączenia krzyżowego jest iloczyn kartezjański łączonych obiektów. W
przeciwieństwie do innych typów złączeń, w tym wypadku łączone tabele nie muszą mieć
wspólnych kolumn. Złączenia tego typu są rzadko stosowane w znormalizowanych bazach
danych i służą raczej do generowania danych testowych niż do wybierania danych (listing
4.9).
Listing 4.9. Wynikiem złączenia krzyżowego jest iloczyn kartezjański
SELECT * FROM barcode CROSS JOIN stock;
++++-+

| barcode_ean | item_id | item_id | quantity |
++++-+
| 2239872376872 | 11 | 1 | 12 |
| 2239872376872 | 11 | 2 | 2 |
| 2239872376872 | 11 | 4 | 8 |
| 2239872376872 | 11 | 5 | 3 |
...
| 9879879837489 | 11 | 10 | 1 |
++++-+
98 rows in set (0.00 sec)
Złączenie nierównościowe Powiązania tabel wykorzystujące dowolny, inny niż równość, operator nazywane są
nierównościowymi (ang. Non-equi join). Tego typu złączenia z reguły są używane przy
łączeniu tabeli z nią samą albo jako dodatkowe złączenie, obok złączenia równościowego.
Samodzielne złączenie nierównościowe zwraca mało intuicyjne wyniki (listing 4.10).
Listing 4.10. Przykład złączenia nierównościowego
SELECT lname, date_placed
FROM customer INNER JOIN orderinfo
ON customer.customer_id > orderinfo.customer_id
WHERE date_placed BETWEEN '2000=03-01' AND '2000-03-30';
++-+
| lname | date_placed |
++-+
| Matthew | 2000-03-13 |
| Cozens | 2000-03-13 |
| Matthew | 2000-03-13 |
| Stones | 2000-03-13 |
| Stones | 2000-03-13 |
| Hickman | 2000-03-13 |
| Howard | 2000-03-13 |
| Jones | 2000-03-13 |
| Neill | 2000-03-13 |
| Hendy | 2000-03-13 |
| Neill | 2000-03-13 |
| Hudson | 2000-03-13 |
| Wolski | 2000-03-13 |
++-+
Zwróć uwagę na warunek w klauzuli WHERE. Żeby
wybrać zamówienia z marca 2000 roku, należało
określić przedział czasu
Złączenie tabeli z nią samą
Złączenie tabeli z nią samą stosujemy, kiedy chcemy wybrać rekordy z tabeli na podstawie
wspólnych wartości atrybutów rekordów tej samej tabeli.

Złączenie tabeli z nią samą jest jedną z technik
języka SQL, odpowiadającą użyciu zmiennych w
proceduralnych językach programowania.
Przy łączeniu w ten sposób, należy pamiętać o następujących zasadach:
1. Trzeba utworzyć różne aliasy dla łączonej tabeli i w ramach zapytania konsekwentnie
odwoływać się do aliasów, a nie do nazwy tabeli.
2. Każdy rekord, w którym wartości atrybutu złączenia będą sobie równe, zostanie
dodany do wyniku złączenia, co spowoduje powstanie duplikatów rekordów.
Złączenia tabeli z samą sobą są często wykorzystywane do rekurencyjnego odczytania
danych, na przykład informacji o podwładnych (podwładny osoby X może być przełożonym
osoby Y, która z kolei może być przełożonym osoby Z). W testowej bazie danych nie ma
zapisanych takich zależności. Przykład z listingu 4.11. jest czysto szkoleniowy.
Listing 4.11. Złączenie tabeli z nią samą. Zwróć uwagę na liczbę powtórzonych wierszy
SELECT l.customer_id, r.customer_id, l.lname, r.lname
FROM customer l INNER JOIN customer r
ON l.customer_id = r.customer_id;
+-+-+++
| customer_id | customer_id | lname | lname |
+-+-+++
| 1 | 1 | Stones | Stones |
| 2 | 2 | Stones | Stones |
| 3 | 3 | Matthew | Matthew |
| 4 | 4 | Matthew | Matthew |
| 5 | 5 | Cozens | Cozens |
| 6 | 6 | Matthew | Matthew |
| 7 | 7 | Stones | Stones |
| 8 | 8 | Stones | Stones |
| 9 | 9 | Hickman | Hickman |
| 10 | 10 | Howard | Howard |
| 11 | 11 | Jones | Jones |
| 12 | 12 | Neill | Neill |
| 13 | 13 | Hendy | Hendy |
| 14 | 14 | Neill | Neill |
| 15 | 15 | Hudson | Hudson |
| 16 | 16 | Wolski | Wolski |
+-+-+++
Jak wyeliminować te powtórzenia? Na pewno nie pomoże w tym słowo kluczowe DISTINCT
— przecież każdy wiersz zawiera niepowtarzalną kombinację danych. Rozwiązanie polega na
dodaniu niesymetrycznego warunku (np. WHERE l.lname > r.lname), ale MySQL przy
łączeniu tabeli z nią samą nie rozróżnia kolumn pochodzących z lewostronnie i prawostronnie
złączonej tabeli, traktując je (niezgodnie ze standardem języka) jako te same. W efekcie
dodanie takiego warunku wyeliminuje wszystkie wiersze.
Złączenie wyników (operator UNION) Skoro tabele są specjalnymi zbiorami, to, tak jak zbiory, można je dodawać, odejmować i
wyznaczać ich część wspólną. W wersji 5. MySQL obsługuje tylko jeden operator
teoriomnogościowy — sumę.

Do zsumowania wierszy z dowolnej liczby tabel służy operator UNION. Załóżmy, że A i B są
zbiorami — wtedy suma zbiorów A i B składa się z elementów obu zbiorów: AEB={x: xÎA
lub xÎB} (rysunek 4.1).
Rysunek 4.1. Na sumę dwóch tabel składają się wszystkie wiersze jednej tabeli i wszystkie
wiersze drugiej tabeli
Za pomocą operatora UNION możemy dodać wyniki poszczególnych zapytań (czyli zwiększyć
liczbę wierszy wyniku. Złączenia JOIN zwiększały liczbę kolumn, złączenie UNION zwiększa
liczbę wierszy). Łączone wyniki muszą składać się z takiej samej liczby kolumn, a
poszczególne kolumny muszą być tego samego typu, poza tym konieczne jest, aby
występowały one w tej samej kolejności w obu wynikach (listing 4.12).
Listing 4.12. Złączenie wyników dwóch prostych zapytań
SELECT fname FROM customer
UNION
SELECT description FROM item;
+--+
| fname |
+--+
| Jenny |
| Andrew |
| Alex |
| Adrian |
| Simon |
| Neil |
| Richard |
| Ann |
| Christine |
| Mike |
| Dave |
| Laura |
| Bill |
| David |
| |
| Wood Puzzle |
| Rubik Cube |
| Linux CD |
| Tissues |
| Picture Frame |
| Fan Small |

| Fan Large |
| Toothbrush |
| Roman Coin |
| Carrier Bag |
| Speakers |
| SQL Server 2005 |
+--+
Operatory teoriomnogościowe (takie jak UNION) automatycznie eliminują z wyniku
powtarzające się wiersze, co odpowiada użyciu opcji DISTINCT w klauzuli SELECT. Jeżeli
chcemy otrzymać listę zawierającą wszystkie wiersze z łączonych tabel, należy użyć słowa
kluczowego ALL (listing 4.13).
Listing 4.13. Przykład pokazujący domyślne usuwanie duplikatów z wyników złączenia
UNION
SELECT item_id FROM item UNION SELECT item_id FROM stock;
++
| item_id |
++
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
++
SELECT item_id FROM item UNION ALL SELECT item_id FROM stock;
++
| item_id |
++
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 1 |
| 2 |
| 4 |
| 5 |
| 7 |
| 8 |
| 10 |
++

Wybrane funkcje serwera MySQL
Tak jak we wszystkich innych językach programowania, w języku SQL funkcje stanowią
potężne narzędzie w pracy programisty — zamiast samodzielnie pisać skomplikowane
programy, wystarczy wywołać odpowiednią funkcję. W tym odcinku nauczymy się
wywoływać funkcje systemowe i poznamy niektóre funkcje serwera MySQL.
Wprowadzenie
Wbudowane funkcje serwerów baz danych można podzielić na trzy kategorie:
1. Funkcje skalarne, które zwracają pojedynczą wartość obliczoną na podstawie zera
lub większej liczby prostych argumentów.
2. Funkcje grupujące, które zwracają pojedynczą wartość dla zbioru argumentów
wywołania.
3. Funkcje typu RowSet, zwracające dane w postaci tabelarycznej, do których
odwołujemy się tak jak do tabel.
Na podstawie typu parametrów wywołania funkcje skalarne można podzielić na:
1. Funkcje tekstowe operujące na ciągach znaków.
2. Funkcje liczbowe operujące na liczbach.
3. Funkcje daty i czasu operujące na danych typu data/godzina.
4. Funkcje konwersji służące do zmiany typu danych.
Na specjalne wyróżnienie zasługują funkcje kryptologiczne, które pozwalają zaszyfrować,
odszyfrować, podpisać i sprawdzić autentyczność wiadomości.
W języku SQL funkcje można zagnieżdżać do
dowolnego poziomu. Funkcje najbardziej
wewnętrzne obliczane są w pierwszej kolejności, a na
podstawie ich wyników obliczane są funkcje
zewnętrzne.
Funkcje tekstowe Argumentem funkcji tekstowych są ciągi znaków (dane typów char, varchar lub text). Typ
danych zwracanych przez funkcje tekstowe jest podstawą do ich dalszego podziału:
wyróżniamy funkcje tekstowe zwracające wartość znakową i funkcje tekstowe zwracające
liczbę.
Funkcje tekstowe zawierajace tekst
CONCAT()

Funkcja łączy (konkatenuje) przekazane jako parametr i oddzielone przecinakami ciągi
znaków. Używaliśmy już tej funkcji, a w następnych listingach użyjemy jej jeszcze kilka
razy.
LOWER()
Wynikiem działania funkcji LOWER() jest ciąg znaków podany jako argument, ale składający
się wyłącznie z małych liter. Za pomocą tej funkcji wszystkie wielkie litery argumentu
zostaną zamienione na małe. Na przykład, aby wyświetlić nazwiska wszystkich
współpracowników za pomocą małych liter, napiszemy (listing 5.1).
Listing 5.1. Funkcji skalarnych można używać m.in. w klauzulach SELECT, WHERE i ORDER BY
SELECT title, LOWER(title)
FROM customer
WHERE customer_id<3;
+-+--+
| title | lower(title) |
+-+--+
| Miss | miss |
| Mr | mr |
+-+--+
UPPER()
Wynikiem działania funkcji UPPER() jest ciąg znaków podany jako argument, ale składający
się wyłącznie z wielkich liter. Za pomocą tej funkcji wszystkie małe litery argumentu zostaną
zamienione na wielkie. Na przykład, aby uszeregować nazwy wszystkich towarów
alfabetycznie według ich nazw, bez względu na wielkość użytych w nazwie liter, napiszemy
(listing 5.2).
Listing 5.2. Poszczególne klauzule instrukcji są od siebie niezależne — na przykład, dane
mogą być sortowane według wyrażenia niewymienionego w klauzuli SELECT
SELECT * FROM item ORDER BY UPPER(description);
++--+++
| item_id | description | cost_price | sell_price |
++--+++
| 10 | Carrier Bag | 0.01 | 0.00 |
| 7 | Fan Large | 13.36 | 19.95 |
| 6 | Fan Small | 9.23 | 15.75 |
| 3 | Linux CD | 1.99 | 2.49 |
| 5 | Picture Frame | 7.54 | 9.95 |
| 9 | Roman Coin | 2.34 | 2.45 |
| 2 | Rubik Cube | 7.45 | 11.49 |
| 11 | Speakers | 19.73 | 25.32 |
| 12 | SQL Server 2005 | NULL | NULL |
| 4 | Tissues | 2.11 | 3.99 |
| 8 | Toothbrush | 0.75 | 1.45 |
| 1 | Wood Puzzle | 15.23 | 21.95 |
++--+++
Funkcje liczbowe
ROUND()

Działanie funkcji ROUND() polega na zaokrągleniu liczby do określonej liczby cyfr po
przecinku. Pierwszy parametr jest liczbą do zaokrąglenia, drugi wskazuje, do ilu pozycji
chcemy zaokrąglić. Ujemna liczba powoduje zaokrąglenie liczby z lewej strony przecinka; 0
spowoduje zaokrąglenie do najbliższej liczby całkowitej. Jeżeli drugi parametr nie jest
podany, SZBD przyjmuje domyślnie jego wartość jako równą 0 (listing 5.12).
Listing 5.12. Przykład użycia funkcji ROUND()
SELECT Round(3.1415926535897,4) , Round(3.1415926535897,0),
Round(3.1415926535897);
+--+--++
| Round(3.1415926535897,4) | Round(3.1415926535897,0) |
Round(3.1415926535897) |
+--+--++
| 3.1416 | 3 |
3 |
+--+--++
TRUNCATE()
Funkcja TRUNCATE() powoduje obcięcie liczby do określonej liczby cyfr po przecinku.
Pierwszy parametr jest liczbą do obcięcia, drugi wskazuje, do ilu pozycji chcemy liczbę
skrócić. Ujemna liczba powoduje dodanie określonej liczby zer z lewej strony przecinka.
Jeżeli drugi parametr nie jest podany, MySQL przyjmuje domyślnie jego wartość jako równą
0 (listing 5.13).
Listing 5.13. Obcięcie miejsc po przecinku i zaokrąglenie do iluś miejsc po przecinku to dwie
operacje
SELECT Truncate(3.1415926535897,4);
+--+
| Truncate(3.1415926535897,4) |
+--+
| 3.1415 |
+--+
ABS()
Wynikiem działania funkcji ABS() jest wartość bezwzględna liczby (liczba bez znaku). Jako
parametr podaje się liczbę, której wartość bezwzględną należy obliczyć (listing 5.14).
Listing 5.14. Funkcja ABS() użyta do sprawdzenia, czy dana liczba jest dodatnia
SELECT *
FROM item
WHERE sell_price != ABS(sell_price);
Empty set
CEILING(), FLOOR()
Za pomocą funkcji CEILING() zwrócona zostanie najmniejsza liczba całkowita równa liczbie
podanej jako argument funkcji lub większa. Funkcja FLOOR() zwraca największą liczbę
całkowitą równą liczbie podanej jako argument funkcji lub mniejszą (listing 5.15).
Listing 5.15. Zwróć uwagę na wynik wywołania funkcji z argumentem Null
SELECT sell_price, CEILING(sell_price), FLOOR(sell_price)

FROM item;
+++-+
| sell_price | CEILING(sell_price) | FLOOR(sell_price) |
+++-+
| 21.95 | 22 | 21 |
| 11.49 | 12 | 11 |
| 2.49 | 3 | 2 |
| 3.99 | 4 | 3 |
| 9.95 | 10 | 9 |
| 15.75 | 16 | 15 |
| 19.95 | 20 | 19 |
| 1.45 | 2 | 1 |
| 2.45 | 3 | 2 |
| 0.00 | 0 | 0 |
| 25.32 | 26 | 25 |
| NULL | NULL
Funkcje daty i czasu Kolejna często używana grupa funkcji, to funkcje operujące na argumentach będących
zapisem daty lub czasu. W prawie każdej bazie danych część przechowywanych w niej
informacji musi mieć jakiś znacznik czasu — atrybut pozwalający na sprawdzenie, kiedy
rekord został dodany lub zmodyfikowany. Ponadto część informacji, na przykład dane o
poszczególnych transakcjach finansowych, po wyeliminowaniu dat ich zawarcia, staje się
bezwartościowa. Dlatego MySQL posiada predefiniowane funkcje pozwalające wykonywać
podstawowe operacje na danych tego typu.
CURDATE(), CURTIME()
Wynikiem działania funkcji CURDATE() jest bieżąca data, a funkcji CURTIME() — bieżący
czas. Częstym zastosowaniem funkcji jest automatyczne wstawianie informacji o czasie
utworzenia lub zmodyfikowania danych (listing 5.22).
Listing 5.22. Odczytanie bieżącej daty i czasu systemowego
SELECT CURDATE(),CURTIME();
++--+
| CURDATE() | CURTIME() |
++--+
| 2006-04-20 | 09:33:10 |
++--+
NOW()
Funkcja NOW() zwraca zarówno datę, jak i czas systemowy (listing 5.23).
Listing 5.23. Przykład wywołania funkcji NOW(). Należy zwrócić uwagę, że nawet jeżeli
funkcja wywoływana jest bez parametrów, trzeba użyć nawiasów
SELECT NOW();
++
| NOW() |
++
| 2006-04-20 09:37:08 |
++
DAYOFMONTH(), DAYOFWEEK(), DAYOFYEAR()

Funkcje DAYOFMONTH(), DAYOFWEEK(), DAYOFYEAR() zwracają numer dnia odpowiednio:
miesiąca (liczba z zakresu od 1 do 31), tygodnia (liczba z zakresu od 1 do 7, gdzie 1 oznacza
niedzielę — pierwszy dzień tygodnia, a 7 sobotę — siódmy dzień tygodnia) i roku (liczba z
zakresu od 1 do 365) (listing 5.24).
Listing 5.24. Lista zamówień złożonych w piątek
SELECT * FROM orderinfo WHERE DAYOFWEEK(date_placed) = 6;
+--+-+-+--+-+
| orderinfo_id | customer_id | date_placed | date_shipped | shipping |
+--+-+-+--+-+
| 2 | 8 | 2000-06-23 | 2000-06-23 | 0.00 |
| 5 | 8 | 2000-07-21 | 2000-07-24 | 0.00 |
+--+-+-+--+-+
Funkcje konwersji
Piąta wersja serwera MySQL umożliwia definiowanie kolumn lub deklarowanie zmiennych
różnych typów:
1. Dane tekstowe (typy char, varchar, text) — mogą zawierać tekst lub kombinacje
tekstu i liczb, na przykład adres; mogą zawierać również liczby, na których nie są
przeprowadzane obliczenia, takie jak numery telefonów, numery katalogowe i kody
pocztowe.
2. Dane binarne (typy binary, varbinary, BLOB) — mogą zawierać dowolne dane. Mogą
to być zarówno długie teksty, jak i grafika czy pliki multimedialne.
3. Dane liczbowe (typy tinyint, smallint, mediumint, int, bigint, decimal, float, double) —
zawierają dane liczbowe, na których są przeprowadzane obliczenia, przy czym dwa
ostatnie typy są zmiennoprzecinkowe, czyli takie dane przechowywane są z określoną
dokładnością.
4. Daty (typy datetime, date, timestamp, time i year) — przechowują dane dotyczące
daty i czasu.
5. Dane logiczne (typy bool, boolean) — w mySQL-u są to synonimy typu tinyint, przy
czym 0 oznacza fałsz a 1 — prawdę.
Prędzej czy później każdy administrator i programista
baz danych będzie zmuszony porównać ze sobą dane
różnych typów. Wynik porównania np. imienia Anna z
liczbą 712 czy datą 2001-1-1 jest trudny do
przewidzenia. Aby takie porównanie było możliwe,
trzeba najpierw przekonwertować porównywane dane.
ASCII()
W wyniku działania funkcji ASCII() zostaje zwrócony kod ASCII znaku podanego jako
parametr wywołania. Jeżeli jako parametr podamy ciąg znaków, za pomocą tej funkcji
zostanie obliczony i zwrócony kod ASCII pierwszego znaku w ciągu (listing 5.29).
Listing 5.29. Konwersja znaków na liczby
SELECT ASCII(lname), lname FROM customer;

+--++
| ASCII(lname) | lname |
+--++
| 83 | Stones |
| 83 | Stones |
| 77 | Matthew |
| 77 | Matthew |
| 67 | Cozens |
| 77 | Matthew |
| 83 | Stones |
| 83 | Stones |
| 72 | Hickman |
| 72 | Howard |
| 74 | Jones |
| 78 | Neill |
| 72 | Hendy |
| 78 | Neill |
| 72 | Hudson |
| 87 | Wolski |
+--++
CHR()
Działanie funkcji CHR() jest przeciwieństwem działania funkcji ASCII() — zamiast zamiany
tekstu na liczbę przeprowadza konwersję liczby na odpowiadające jej znaki kodu ASCII
(listing 5.30).
Listing 5.30. Funkcję CHR() często stosuje się w celu oszukania prostych zabezpieczeń przed
iniekcją kodu
SELECT CHAR(77,121,83,81,'76');
+-+
| CHAR(77,121,83,81,'76') |
+-+
| MySQL |
+-+
BIN()
Funkcja BIN() zwraca binarną reprezentację podanej liczby dziesiętnej (listing 5.31).
Listing 5.31. Zmiana podstawy liczb
SELECT item_id, BIN(item_id) FROM item;
++--+
| item_id | BIN(item_id) |
++--+
| 1 | 1 |
| 2 | 10 |
| 3 | 11 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
| 8 | 1000 |
| 9 | 1001 |
| 10 | 1010 |
| 11 | 1011 |
| 12 | 1100 |
++--+

CAST()
Funkcja CAST() pozwala przekonwertować (rzutować) dane przekazane jako pierwszy
parametr wywołania na typ podany jako drugi parametr funkcji (listing 5.32).
Listing 5.32. CAST() jest najbardziej uniwersalną funkcją konwersji
SELECT CAST('2001-1-1' AS date);
+--+
| CAST('2001-1-1' AS date) |
+--+
| 2001-01-01 |
+--+
Grupowanie danych i funkcje grupujące
W tym odcinku poznamy funkcje grupujące i dwie nowe klauzule instrukcji SELECT — GROUP
BY i HAVING. Nauczymy się też grupować dane, czyli łączyć wiele wierszy w jeden.
Funkcje grupujące Funkcje, które zwracają jedną wartość obliczoną na podstawie przekazanego zbioru
parametrów nazywamy funkcjami grupującymi. W każdym serwerze baz danych, w tym w
MySQL-u, zaimplementowano najważniejsze i najczęściej używane funkcje tego typu —
minimum, maksimum, średnią, sumę itd.
Specyfika języka SQL powoduje, że łatwiej jest
najpierw wytłumaczyć, jak korzystać z funkcji
grupujących, a dopiero później — jak grupować
dane.
Wiemy już, że parametrem wywołania funkcji grupujących nie są pojedyncze wartości, ale
grupy (zbiory) wartości i że dzięki tym funkcjom uzyskujemy pojedynczy wynik obliczony na
podstawie wielu argumentów. Na przykład możemy w tabeli policzyć wiersze spełniające
określone kryteria lub możemy wyliczyć wartość średnią dla wszystkich wartości z wybranej
kolumny. Użycie tych funkcji zwykle związane jest z operacją na wskazanych kolumnach (na
których wykonywane są obliczenia), a jako wynik zwracany jest tylko jeden wiersz.
Funkcja COUNT()
Pierwszą funkcją agregującą, którą chcę dokładnie omówić, jest funkcja COUNT(). Funkcja
zlicza w przekazanym zbiorze wartości wystąpienia różne od NULL, chyba że jako argumentu
użyto znaku * (gwiazdka) — takie wywołanie funkcji spowoduje zliczenie wszystkich
wierszy, łącznie z duplikatami i wartościami NULL. Argumentem funkcji mogą być liczby,
daty, znaki i ciągi znaków (listing 6.1).

Jeśli chcemy znać liczbę wierszy zwróconych przez
zapytanie, najprościej jest użyć funkcji COUNT(*). Są
dwa powody, dla których warto tak wywołać funkcję
COUNT() do tego celu. Po pierwsze, pozwalamy
optymalizatorowi bazy danych wybrać kolumnę do
wykonywania obliczeń, co czasem nieznacznie
podnosi wydajność zapytania, po drugie, nie musimy
się martwić o wartości Null zawarte w kolumnie oraz
o to, czy kolumna o podanej nazwie w ogóle istnieje.
Listing 6.1. Zapytanie zwracające liczbę klientów
SELECT COUNT(*) as 'Liczba klientów'
FROM customer;
+--+
| Liczba klientów |
+--+
| 16 |
+--+
Jak widać, zapytanie zwróciło jedną wartość wyliczoną przez funkcję grupującą COUNT() na
zbiorze równym zawartości tabeli item. Gdybyśmy chcieli policzyć imiona i nazwiska
klientów, otrzymamy nieco inny wynik. Wywołanie funkcji w postaci COUNT(nazwa kolumny)
nie uwzględnia pól z wartościami Null. Fakt, że wiersze z wartością Null nie są zliczane,
może być przydatny, gdy wartość Null oznacza coś szczególnego, lub gdy chcemy
sprawdzić, czy w bazie nie brakuje istotnych informacji (listing 6.2).
Listing 6.2. Funkcja COUNT() wywołana dla dwóch różnych zbiorów — raz dla nazwisk, raz
dla imion klientów. Jak widać, jedna osoba nie podała nam imienia.
SELECT COUNT(fname), COUNT(lname)
FROM customer;
+--+--+
| COUNT(fname) | COUNT(lname) |
+--+--+
| 15 | 16 |
+--+--+
Jeżeli chcemy policzyć unikatowe wystąpienia wartości, wystarczy wykorzystać wiedzę z
wcześniejszych odcinków kursu i właściwie użyć słowa kluczowego DISTINCT (listing 6.3).
Listing 6.3. Zapytanie zwracające liczbę miast, w których mieszkają nasi klienci — w
pierwszej kolumnie to samo miasto liczone jest tyle razy, ilu mieszka w nim klientów, w
drugiej kolumnie każde miasto policzone jest tylko raz
SELECT COUNT(town), COUNT(DISTINCT(town))
FROM customer;
+-+--+
| COUNT(town) | COUNT(DISTINCT(town)) |
+-+--+

| 15 | 12 |
+-+--+
Domyślnie funkcje grupujące nie eliminują
powtarzających się wierszy, co odpowiada użyciu
kwalifikatora All jako pierwszego argumentu
wywołania. Jeżeli chcemy ograniczyć dziedzinę
funkcji do unikatowych wartości wierszy, należy
użyć kwalifikatora DISTINCT.
Grupowanie danych Do tej pory wywoływaliśmy funkcje grupujące raz dla całych tabel lub ich fragmentów.
Klauzula GROUP BY umożliwia grupowanie wyników względem zawartości wybranych
kolumn. W wyniku jej działania uzyskujemy podział wierszy tablicy na dowolne grupy. W
pewnym sensie jej działanie jest podobne do operatora DISTINCT, ponieważ po jej
zastosowaniu zwracany jest pojedynczy wynik dla każdej grupy (listing 6.14).
Listing 6.14. Klauzula GROUP BY użyta do wyeliminowania duplikatów — skoro dane są
grupowane według identyfikatorów osób, czyli zamówienia złożone przez tę samą osobę
dodawane są do jednej grupy, to w wyniku nie może pojawić się kilka razy ten sam
identyfikator klienta
SELECT customer_id FROM orderinfo GROUP BY customer_id;
+-+
| customer_id |
+-+
| 3 |
| 8 |
| 13 |
| 15 |
+-+
Jeżeli jednak w zapytaniu użyjemy jednocześnie funkcji grupującej, to ta funkcja zostanie
wywołana niezależnie dla każdej grupy zdefiniowanej w klauzuli GROUP BY. W bazie test
informacje o zamówieniach przechowywane są w tabeli orderinfo, a poszczególne pozycje
zamówienia — w tabeli orderline (dzięki temu w ramach każdego zamówienia klient może
kupić dowolną liczbę najróżniejszych towarów). Pierwsze zapytanie (listing 6.15) zwraca
liczbę wszystkich sprzedanych towarów, drugie (listing 6.16) rozbija tę liczbę na
poszczególne zamówienia.
Listing 6.15. Ogólna liczba sprzedanych towarów
SELECT SUM(quantity) FROM orderline;
++
| SUM(quantity) |
++
| 15 |
++

Listing 6.16. Liczba towarów sprzedanych w ramach poszczególnych zamówień
SELECT SUM(quantity) FROM orderline
GROUP BY orderinfo_id;
++
| SUM(quantity) |
++
| 3 |
| 6 |
| 2 |
| 2 |
| 2 |
++
Świetnie, ale w drugim wyniku wyraźnie brakuje informacji o tym, w ramach którego z
zamówień sprzedano tyle a tyle towarów. Wcześniej próbowaliśmy dodać tego typu dane do
klauzuli SELECT i skończyło się to błędem. Czy klauzula GROUP BY coś zmieniła? (listing
6.17).
Listing 6.17. Ta instrukcja SELECT jest jak najbardziej poprawna — przecież dane zostały
pogrupowane według wartości orderinfo_id, a następnie dla każdej grupy została wywołana
funkcja grupująca
SELECT orderinfo_id, SUM(quantity)
FROM orderline
GROUP BY orderinfo_id;
+--++
| orderinfo_id | SUM(quantity) |
+--++
| 1 | 3 |
| 2 | 6 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
+--++
Zapamiętaj — jeżeli w klauzuli SELECT występują
dowolne funkcje grupujące, to wszystkie nazwy
kolumn i wyrażenia, które NIE SĄ argumentami tych
funkcji muszą zostać wymienione w klauzuli GROUP
BY. Innymi słowy, w takich zapytaniach w klauzuli
SELECT mogą występować tylko i wyłącznie wyrażenia,
które są wymienione w klauzuli GROUP BY, chyba że są
one argumentami dowolnej funkcji agregującej.
Jak wiemy, język SQL umożliwia, poprzez zastosowanie klauzuli ORDER BY, porządkowanie
wyników zapytania. Możliwe jest też sortowanie wyników na podstawie wyniku funkcji
grupujących (listing 6.18).

Listing 6.18. Uporządkowany wynik poprzedniego zapytania
SELECT orderinfo_id, SUM(quantity)
FROM orderline
GROUP BY orderinfo_id
ORDER BY SUM(quantity) DESC;
+--++
| orderinfo_id | SUM(quantity) |
+--++
| 2 | 6 |
| 1 | 3 |
| 3 | 2 |
| 4 | 2 |
| 5 | 2 |
+--++
W zapytaniach grupujących dane możemy używać, tak samo jak klauzuli ORDER BY, klauzuli
WHERE. W ten sposób ograniczymy liczbę wierszy jeszcze zanim będą one dzielone na grupy i
podgrupy. Przy używaniu klauzuli WHERE łącznie z GROUP BY najpierw realizowane jest
ograniczenie wynikające z kryteriów w klauzuli WHERE. Następnie wybrane rekordy są
grupowane i powstaje ostateczny wynik zapytania (listing 6.19).
Listing 6.19. Wynik poprzedniego zapytania ograniczony do zamówień z pierwszej połowy
2000 roku
SELECT orderinfo_id, SUM(quantity)
FROM orderline
JOIN orderinfo USING (orderinfo_id)
WHERE date_placed BETWEEN '2000-01-01' AND '2000-06-31'
GROUP BY orderinfo_id
ORDER BY SUM(quantity) DESC;
+--++
| orderinfo_id | SUM(quantity) |
+--++
| 2 | 6 |
| 1 | 3 |
+--++
Otrzymane w ten sposób grupy wierszy możemy dalej dzielić na podgrupy. Wymieniając w
klauzuli GROUP BY wiele wyrażeń, podzielimy zbiór wierszy na grupy wyznaczone pierwszym
wyrażeniem, te grupy podzielimy na podgrupy na podstawie wartości drugiego wyrażenia itd.
(listing 6.20).
Listing 6.20. Liczba towarów kupionych przez poszczególnych klientów w ramach
poszczególnych zamówień
SELECT fname, orderinfo_id, SUM(quantity)
FROM orderline
JOIN orderinfo USING (orderinfo_id)
JOIN customer USING (customer_id)
GROUP BY fname, orderinfo_id
ORDER BY fname;
+-+--++

| fname | orderinfo_id | SUM(quantity) |
+-+--++
| Alex | 1 | 3 |
| Anna | 2 | 6 |
| Anna | 5 | 2 |
| David | 3 | 2 |
| Laura | 4 | 2 |
+-+--++