1subieta/prace doktorskie/PhD Andr… · Web viewdoc. dr.hab.inż. Kazimierz Subieta. ... (Common...
192
Polska Akademia Nauk Instytut Podstaw Informatyki ROZSZERZONE ARCHITEKTURY WIELOWARSTWOWE W ŚRODOWISKU KOMUNIKACYJNYM APLIKACJI ROZPROSZONYCH (rozprawa doktorska) Andrzej Sikorski Promotor: doc. dr.hab.inż. Kazimierz Subieta
Transcript of 1subieta/prace doktorskie/PhD Andr… · Web viewdoc. dr.hab.inż. Kazimierz Subieta. ... (Common...

Polska Akademia Nauk
Instytut Podstaw Informatyki
ROZSZERZONE ARCHITEKTURY WIELOWARSTWOWE W ŚRODOWISKU KOMUNIKACYJNYM
APLIKACJI ROZPROSZONYCH
(rozprawa doktorska)
Andrzej Sikorski
Promotor:
doc. dr.hab.inż. Kazimierz Subieta
Warszawa, grudzień 2002

Spis treści
1. Wstęp................................................................................................................4
1.1. Architektury wielowarstwowe..........................................................................41.2. Cel i zakres pracy............................................................................................10
2. Obiektowe protokoły komunikacyjne............................................................26
2.1. Protokół obiektowy DCOM............................................................................282.2. Eksperymentalne warianty architektur wielowarstwowych...........................302.3. DCOM i architektury oprogramowania..........................................................37
3. Przetwarzanie asynchroniczne........................................................................40
3.1. Tryby wywołania funkcji................................................................................413.2. Przetwarzanie asynchroniczne - RAW...........................................................433.3. Asynchroniczne przetwarzanie na poziomie DCOM.....................................463.4. Uogólniona modalność...................................................................................513.5. Autonomiczność agentów...............................................................................54
4. Migracja obiektów..........................................................................................57
4.1. Marshaling – reprezentacja strumieniowa......................................................584.2. Blind Delegator (BD)–posłuszny przekaźnik.................................................624.3. Osadzanie obiektu OE (object embedding)....................................................654.4. Migracja obiektu na poziomie aplikacyjnym – RAW....................................684.5. Mobilność agentów.........................................................................................72
5. Dynamiczny polimorfizm...............................................................................77
5.1. Biblioteki typów.............................................................................................805.2. Refleksja w systemach kooperacyjnych.........................................................835.3. Dynamiczny interfejs IDispatch - RAW.........................................................865.4. Dokumenty elektroniczne w architekturach wielowarstwowych...................895.5. Obiektowy model dokumentu.........................................................................93
6. Identyfikacja komponentów...........................................................................96
6.1. Specyfikacja reguł przetwarzania DFD, UML...............................................996.2. Funkcje charakterystyczne, multizbiory.......................................................1026.3. Multizbiór klas abstrakcji wierzchołków grafu............................................1056.4. Grupy automorfizmów grafu........................................................................1076.5. Liczba fasetowa............................................................................................111
7. Eksperymenty implementacyjne..................................................................114
2

7.1. System dystrybucji danych analitycznych....................................................1157.2. Relacyjne bazy danych w aplikacjach RAW................................................1217.3. Elastyczna reprezentacja obiektów sterujących dla systemów automatyki przemysłowej - (studium wykonalności)...................................................................127
8. Zakończenie..................................................................................................131
8.1. Wnioski ogólne.............................................................................................1318.2. Omówienie wyników....................................................................................1328.3. Obecny stan techniki (nowe standardy)........................................................1348.4. Planowane badania i implementacje.............................................................136
3

1. Wstęp
1.1. Architektury wielowarstwowe
Jednym z wyzwań, przed którym stoją obecnie twórcy systemów informatycznych, jest integracja istniejących rozwiązań sprzętowych i programowych w jedno otwarte i rozproszone środowisko kooperacyjnego systemu informatycznego [Face], [Scheb], [Manola], [Brodie]. Istniejące obecnie rozwiązania, rozumiane jako realizacja pewnych wycinkowych funkcji są zaimplementowane w postaci aplikacji realizowanych w oparciu o klasyczne architektury: monolityczne oraz, bardziej nowoczesne, klient serwer [Papaz]. Wynikiem takiego stanu rzeczy jest rozwój architektur aplikacji, środowisk czasu wykonania, systemów operacyjnych oraz narzędzi [Michel], które wspierałyby integrację istniejących rozwiązań (legacy IS), oraz prace mające na celu formalne określenie standardów komunikacji [Bernd] oraz metody pół-formalnej specyfikacji [Rumb] oparte o modelowanie wizyjne. Innym czynnikiem wymuszającym rozwój architektur aplikacji są rosnące wymaganie będące wynikiem coraz większej konkurencji na rynku oprogramowania i zastosowań informatyki.
Architektury wielowarstwowe, będące odpowiedzią na nowe wymagania pojawiające się w obszarze zastosowań informatyki są elementem pewnego ewolucyjnego procesu (rys. .1), w ramach którego miejsce aplikacji monolitycznych zajęła architektura klient serwer [Scheb]. Architekturę klient serwer można określić też mianem dwuwarstwowej. Dwoma warstwami są odpowiednio: warstwa serwera odpowiedzialna za przetwarzanie transakcji, przechowywanie (pesistency) i wyszukiwanie danych, oraz warstwa klienta, której zadaniem jest obsługa interakcji z użytkownikiem oraz realizacja reguł przetwarzania (business rules). W ramach współpracy między obydwoma warstwami warstwa serwera jest odpowiedzialna za wspieranie realizacji reguł poprzez dostarczanie pewnych standardowych usług takich jak por.[Bernstein]:
- sterowanie współbieżnością- przekazywania komunikatów między klientami- przechowywanie danych- wyszukiwanie danych.
Z punktu widzenia oprogramowania aplikacyjnego (rozumianego tutaj w przeciwieństwie do systemowego) środowisko warstwy serwera jest tożsame z oprogramowaniem SQL-owych baz danych.
Następnym etapem było pojawienie się architektur trójwarstwowych [Fey], [Reed], [Manola], w których wydzielono warstwę realizującą reguły przetwarzania. Pojawienie się nowej warstwy było wynikiem realizacji zasady rozdzielania funkcji między
4

składowe systemu informacyjnego, która uprzednio doprowadziła do powstania architektur klient-serwer. Warstwy i własności architektury trójwarstwowej można scharakteryzować następująco [Manola]:
1. Warstwa trzecia jest warstwą klienta. W postaci ortodoksyjnej architektury trójwarstwowej powinna ona realizować wyłącznie funkcje prezentacji, komunikacji z użytkownikiem – stając się tzw. chudym klientem (thin client). Klient tego rodzaju wywołuje współdzielone funkcje poprzez wysyłanie żądań do warstwy drugiej. W bardziej swobodnym podejściu klient obsługuje również pewne zadania aplikacyjne (przykładowo przetwarzanie tekstów, funkcje arkusza kalkulacyjnego, wstępną weryfikację danych). W skrajnym przypadku tzw. gruby klient (fat client) może przypominać drugą warstwę z konwencjonalnej architektury klient serwer.
2. Warstwa druga realizuje funkcje obiektów aplikacyjnych (business object) modelujących reguły przetwarzania. Te funkcje tworzą współdzieloną aplikację korporacyjną. Same korzystają z funkcji udostępnianych przez warstwę pierwszą uzyskując w ten sposób dostęp do danych lub pewnych istniejących w systemie aplikacji (legacy applications)
3. Warstwa trzecia to serwer baz danych, realizujący funkcje wymienione w charakterystyce z poprzedniego akapitu. Można jednakże zauważyć, że już w konwencjonalnych architekturach trójwarstwowych klasa oprogramowania realizująca funkcje tej warstwy jest nieco szersza. Można bowiem do niej zaliczyć również serwery webowe, pocztowe czy plikowe. Również serwery transakcyjne (MTS,IAS czy Jaguar) pojawiły się już w kontekście architektury trójwarstwowej.
4. Warstwy komunikują się z sobą za pomocą protokołu pośredniczącego takiego jak CORBA, DCOM czy DCE. Protokoły te tworzą środowisko komunikacyjne, które jest następnie rozszerzone o usługi transakcyjne i synchronizacyjne.
5. Warstwy mają naturę logiczną a nie fizyczną. Oznacza to, że mogą być implementowane na stacjach roboczych i serwerach. Nie ma jednak takiego wymogu. Cała aplikacja trójwarstwowa może być wykonywana na jednym urządzeniu. Kwestia fizycznego ulokowania poszczególnych składowych powinna być przeźroczysta dla logiki przetwarzania. Zapewniają to usługi protokołów komunikacyjnych.
Najprostszym, ale też najbardziej rozpowszechnionych przykładem aplikacji zrealizowanej w oparciu o architekturę trójwarstwową mogą być systemy oparte o dynamiczne generatory stron HTML [Weng]. Realizowane są one w oparciu o różne mutacje techniki CGI (BGI, TGI, JSP czy ASP) i stały się niemalże oddzielną klasą oprogramowania. Pierwotnie ich celem było jedynie zapewnienie dostępu do baz danych poprzez przeglądarkę. Obecnie technika CGI stała się pełnoprawną metodą realizacji zaawansowanych systemów realizujących złożone reguły przetwarzania, mającą na celu obniżenie kosztów związanych z administrowaniem i instalacją oraz niezależność sprzętową. Ujmując rzecz bardziej ogólnie, widoczne jest dążenie do
5

posługiwania się aplikacjami biurowymi (edytory tekstów, arkusze kalkulacyjne) i standardowym oprogramowaniem w charakterze końcówki użytkownika. Jednocześnie widoczna jest tendencja mająca na celu zmniejszanie znaczenia oprogramowania aplikacyjnego w tejże roli.
Monolit
Klient
Serwer
Klient
Serwer
Warstwa pośrednicząca(middleware)
Klient
Serwer
a) b) c) d)
.1 Ewolucja architektur aplikacji
Pojawienie się, wymienionych w punkcie 3 charakterystyki architektur trójwarstwowych, serwerów transakcyjnych było początkiem nowej fazy rozwoju architektur oprogramowania. Od tego momentu można już mówić o architekturach wielowarstwowych. Serwer transakcyjny (zwany też komponentowym) stanowi środowisko operacyjne dla komponentów programowych – obiektów implementujących (obok charakterystycznych dla siebie reguł przetwarzania) pewne funkcje czy interfejsy określone przez standard. Przykładami standardów tego typu są COM, SOM czy DOM (odpowiednio Compound, Structured i Document Object Model). Tak więc komponent jest pewnym szczególnym obiektem zdefiniowanym w kontekście określonego standardu. Przedstawiając rzecz w pewnym uproszczeniu, można powiedzieć, że serwer transakcyjny umożliwia załadowanie kodu wykonywalnego komponentu oraz wywołanie jego funkcji za pośrednictwem protokołu komunikacyjnego – pełniąc w ten sposób rolę „systemu operacyjnego” dla komponentów. Oprócz tego serwer realizuje pewne administracyjne funkcje związane z bezpieczeństwem, obsługą transakcji czy zarządzaniem przestrzenią nazw [Reed].
Nazwa architektury wielowarstwowe nie oddaje w pełni jej istoty, gdyż sugeruje jakoby w miejsce warstwy drugiej pojawił się szereg warstw pośredniczących pomiędzy klientem a serwerem. Struktura w tej postaci przypominałaby warstwy protokołów sieciowych (model ISO-OSI), gdzie każda z warstw sama udostępniałaby swoje usługi warstwie wyższej, korzystając jednocześnie z usług warstwy niższej. W rzeczywistości aplikacje zrealizowane w oparciu architektury wielowarstwowe stanowią zestaw komponentów, które to komponenty udostępniają jedne funkcje a korzystają z innych ewentualnie z zasobów. Nie ma żadnych ograniczeń co do topografii połączeń między komponentami. W skrajnym przypadku mogą tworzyć one dowolny graf, w którym wierzchołkom odpowiadają reguły przetwarzania, krawędzie natomiast modelują
6

wzajemne zależności. Miejsce powiązania klient serwer zajmuje relacja dostawca – konsument zdefiniowana w kontekście jednej konkretnej funkcji. Nic nie stoi na przeszkodzie, aby w jednej sytuacji komponent A konsumował informacje czy usługi komponentu B, w innej zaś było odwrotnie. Takie elastyczne możliwości komunikowania się pomiędzy składowymi aplikacji odpowiadają zależnościom występującym w organizacjach i firmach nowego typu.
Zalety architektury wielowarstwowej [Sikor00a]:
1. Oddzielenie funkcji: prezentacji danych, interfejsu użytkownika, składowania danych i synchronizacji ich współdzielenia oraz logiki przetwarzania. Dostosowanie struktury systemu informatycznego do struktury modelowanej organizacji czy firmy. Struktura systemu wynika z wymogów reguł przetwarzania i przepływu informacji w modelowanej organizacji, a nie odwrotnie.
2. Możliwość wyodrębnienia składowych realizujących zadania krytyczne pod względem czasu wykonania, bezpieczeństwa i niezawodności oraz implementacja i instalacja ich w stosownych środowiskach.
3. Wykorzystanie standardowych protokołów komunikacyjnych, które zapewniają przenośność i kompatybilność pomiędzy różnymi platformami sprzętowymi i systemowymi.
4. Równomierne wykorzystanie mocy obliczeniowych wszystkich komponentów sieci.5. Integracja ze standardowymi bibliotekami komponentów i obiektów (np. VCL,
MFC).6. Zmniejszenie obciążenia stacji roboczych, łatwiejsza administracja systemem
bardziej wydajny mechanizm bezpieczeństwa.7. Ujednolicony dostęp do rozproszonych baz danych i innych zasobów sieciowych.
Przedstawione wyżej zalety architektury wielowarstwowej obejmują również częściowo architektury klient-serwer oraz trójwarstwową. Przy czym punkty 1, 2, 4 i 5 stanowią o istotnej przewadze architektur wielowarstwowych nad konwencjonalnymi trójwarstwowymi. Architektury wielowarstwowe zbliżają się stopniowo do możliwości oferowanych przez systemy agentowe. Podobnie jak komponent jest pewnym specjalizowanym obiektem, tak samo agent może być zrealizowany jako komponent – implementujący dodatkowo funkcje komunikacji asynchronicznej oraz mechanizm przekazywania przez wartość,
Przekonanie autora o istotnym znaczeniu architektur wielowarstwowych wynika z doświadczeń zebranych podczas prac nad projektami prowadzonymi na rynku niemieckim. Jest to rynek, na którym panuje wyjątkowo silna konkurencja, gdzie dostawca rozwiązań musi w bezkompromisowy sposób realizować żądania klienta. Szczególnie dotyczy to systemów wdrażanych w średniej wielkości (ok. 50 stacji roboczych i adekwatna do realizowanych zadań i funkcji liczba serwerów) firmach i organizacjach, gdzie decyzje o wyborze oferty i zakupie podejmują również przyszli
7

użytkownicy. Systemy informatyczne w mniejszej skali są na ogół prostsze. Z kolei w dużych organizacjach mechanizm funkcjonowania tychże wyklucza na ogół pracowników niższego szczebla z wpływu na procesy decyzyjne, których przebieg nosi wyraźne znamiona oddziaływania czynników natury „politycznej”. Niemniej, wymuszane przez rynek i rosnącą konkurencję, przemiany w dużych firmach czy organizacjach (uwaga dotyczy Niemiec [Weng], [Fey], [CTR1]) już zmieniają ten stan rzeczy, otwierając nowe obszary dla niezależnych dostawców oprogramowania.
Przejście od architektur trój- do wielowarstwowych stanowi zmianę jakościową, a nie jak mogłoby się wydawać jedynie ilościową, w której dochodzą dodatkowe warstwy realizujące logikę przetwarzania. Zależności w ramach logiki przetwarzania w architekturze trójwarstwowej odpowiadały strukturze fizycznej implementacji. Obiekty aplikacyjne stanowiły w niej warstwę pośredniczącą pomiędzy interfejsem użytkownika a zasobami danych. Obiekt aplikacyjny występował jako klient w stosunku do obiektów warstwy pierwszej (serwera danych), będąc jednocześnie serwerem w stosunku do obiektów realizujących interakcję z użytkownikiem.
Inaczej jest w architekturze wielowarstwowej. Warstwa druga może zostać poddana dekompozycji na obiekty aplikacji pozostające między sobą w złożonych relacjach. Dekompozycja warstwy drugiej pozwala na bardziej elastyczne odwzorowanie reguł przetwarzania konkretnej dziedziny. Modelem opisującym reguły jest najczęściej zaetykietowany graf. Wszystkie wchodzące w skład języka UML typy diagramów oraz diagram przepływu danych DFD mają naturę grafu, prezentując obiekty i ich wzajemne powiązania [Erik]. Obecne w diagramach definicje: atrybuty obiektów i relacji, są w istocie etykietami odpowiednio: wierzchołków i krawędzi. Zwłaszcza DFD jest wygodną metodą specyfikacji wzajemnych zależności między reguła przetwarzania – zrozumiałą zarówno dla informatyka jak i klienta.
Architektura wielowarstwowa stawia nowe zadania zarówno w obszarze techniki jak technologii. Z jednej strony możliwości protokołów obiektowych są niewystarczające dla implementacji złożonych reguł przetwarzania. Dotyczy to własności poza-funkcjonalnych (operacyjnych) [Nierstrasz]. Z drugiej zaś konieczne jest wsparcie procesu projektowania systemu wielowarstwowego przez mechanizmy automatycznej analizy złożonych modeli. W prezentowanej rozprawie proponuje się rozszerzenia protokołów obiektowych oraz algorytm identyfikacji komponentów.
Ogół środków służących do integracji zestawu składowych w jeden spójny system informatyczny określany jest mianem warstwy pośredniczącej – middleware. W szczególności przyjmuje się, że warstwa ta powinna realizować zadania takie jak [Coulson,Schmidt]:
- integracja składowych w jedną spójną aplikację;
8

- obsługa zarządzania i administrowania systemem w nowoczesnym środowisku systemu operacyjnego;
- obsługa niejednorodności środowiska: systemy osadzone (embedded), PDA, stacje robocze (różne platformy), komputery przenośne;
- uwzględnienie ewolucji oprogramowania, szybkiego rozwoju, mobilności użytkowników i dynamicznego pojawiania się węzłów sieci;
- wyodrębnienie cech poza-funkcjonalnych (non-functional) – innymi słowy: operacyjnych.
W związku z tym określa się dwa cele badań w obszarze architektur aplikacji wielowarstwowych [Nierstrasz],[Kiczales]:
- określenie funkcji warstwy pośredniczącej (middleware) realizującej powyższe postulaty;
- metodyka, narzędzia syntezy aplikacji, automatyczna identyfikacja składowych aplikacji oraz własności operacyjnych tychże, optymalizacja rozmieszczenia w systemie rozproszonym.
Pierwszy z wymienionych kierunków badań w dziedzinie architektur wielowarstwowych sprowadza się do pytania o postać warstwy pośredniczącej. Może ona być: środowiskiem czasu wykonania, językiem programowania, specyfikacją modelu programowego czy też pewnym zestawem konwencji i algorytmów. Przykładem tychże postaci mogą być odpowiednio:
- protokół DCOM, będący oprogramowaniem wchodzącym w skład systemu operacyjnego;
- mechanizmy warstwy pośredniczącej osadzone w językach Java i ADA;- specyfikacja MAF – określająca wytyczne dot. programowania agentów
mobilnych w środowisku protokołu CORBA;- zestawy mniej lub bardziej formalnych technik programowych umożliwiających
integrację rozproszonych – tworzonych ad-hoc dla konkretnej pojedynczej aplikacji lub pewnej ich klasy.
Należy zauważyć, że wszyscy autorzy zajmujący się dziedziną architektur oprogramowania preferują warstwę pośredniczącą w postaci pewnej prefabrykowanej infrastruktury. Dominujące podejście, chociaż uzasadnione, nie jest jedynym, bowiem warstwa pośrednicząca może być również tworzona każdorazowo w zależności od konkretnych wymagań aplikacyjnych. Można wymienić następujące argumenty na rzecz infrastruktury zorientowanej na konkretną aplikację:
- całościowy charakter gotowej infrastruktury (system jest tak dobrze zintegrowany i tak zupełny (complete), że zmniejsza to w znacznym stopniu elastyczność – przyjmujemy gotową infrastrukturę z „całym dobrodziejstwem inwentarza” „as is”),
9

- nakłady związane z instalacją i konfiguracją złożonego środowiska czasu wykonania,
- konieczność zapewnienia pełnej zgodności składowych systemu z użytym środowiskiem,
- narzut związany z dodatkowym przetwarzaniem na poziomie systemowym, funkcje infrastruktury angażują dodatkowo procesor,
- mała elastyczność dot. własności operacyjnych składowych, - raczej zgodność z infrastrukturą niż z wymaganiami,
- utrudniona integracja z usługami systemu operacyjnego, np. usługi katalogowe (FIPA DF vs. X500 NDS, ActiveDirectory) [Ovum],
- podawany przez autorów [Coulson], [Blair], [Eliassen] powód jakoby DCOM/CORBA/RMI nie zapewniały wpływu na QoS (wydajność, stabilność pasma, wiarygodność) jest również kontrowersyjny, QoS własnością zależną od warstwy transportowej (usługowej a więc leżącej poniżej), dostarczającej swoich usług protokołowi obiektowemu,
- kwestie pozamerytoryczne: ew. koszty licencji i wdrożenia technologii, eksperymentalny charakter istniejących infrastruktur .Np. nawet aglet IBM nie cieszy się popularnością w praktycznych implementacjach.
Odejście od infrastruktur prefabrykowanych wymaga jednak rozwiązania dwóch problemów:
- Ustalenia, jakie techniki programowania są niezbędne w celu zapewnienia pomyślnej implementacji systemu rozproszonego, który będzie uwzględniał postulaty nowoczesnych architektur oprogramowania (agentowych, komponentowych, kooperacyjnych).
- Znalezienia metody, która umożliwi (wzgl. ułatwi) automatyczne przejście od specyfikacji na poziomie logicznym (reguł przetwarzania) do projektu technicznego, który przyjmie postać specyfikacji komponentów, serwerów aplikacji. Projekt techniczny powinien określać również własności operacyjne poszczególnych składowych.
1.2. Cel i zakres pracy
W pracy stawiane są dwie tezy:
- Obiektowy protokół komunikacyjny może stanowić środowisko implementacyjne umożliwiające pomyślną realizację postulatów architektur: komponentowych, agentowych oraz kooperacyjnych. Ich własności operacyjne można realizować na poziomie aplikacyjnym.
- Możliwa jest automatyczna identyfikacja komponentów realizujących aplikacyjne reguły przetwarzania. Istnieje efektywny algorytm grupujący wierzchołki grafu przepływu danych w klasy równoważności, będące potencjalnymi kandydatami na serwery aplikacji oraz komponenty programowe.
10

Autor jest zdania, że możliwe jest uwypuklenie roli warstwy pośredniczącej, które odchodzi od dominującego punktu widzenia na rzecz nowego, zawierającego w sobie formalną metodę identyfikacji komponentów przy pomocy metod teorii grafów i relacji. Metoda podana przez autora nie rości sobie pretensji do dostarczenia definitywnej odpowiedzi, które z dwóch podejść – gotowa infrastruktura vs. aplikacja – okaże się w konkretnym przypadku optymalne. Należy jednak zauważyć, że brak jest dotąd prac zajmujących się systematycznym podejściem do tworzenia aplikacji rozproszonych, które jednocześnie nie oferowałyby jakiejś swojej (potencjalnie „najlepszej”) infrastruktury.
Celem pracy nie jest podanie konkurencyjnej metody, która ma wyprzeć dotąd istniejące (zintegrowana warstwa pośrednicząca), a tylko wzbogacenie kolekcji możliwości tworzenia aplikacji rozproszonych. Tym bardziej, że pod adresem podejścia aplikacyjnego można sformułować następujące zastrzeżenia:
- czasochłonność – Konieczność implementacji od podstaw. Prefabrykowana infrastruktura, dostarczając gotowych komponentów systemowych, skraca czas rozwoju aplikacji.
- stopień komplikacji szczegółów technicznych – Implementacja specjalizowanej infrastruktury wymaga znajomości używanego protokołu obiektowego. Gotowa infrastruktura pozwala skoncentrować się na regułach przetwarzania.
- podatność na błędy – Można zakładać, że prefabrykowane rozwiązania są lepiej przetestowane i bardziej stabilne.
- brak zgodności ze standardami – Prefabrykowane infrastruktury powinny być zgodne z pewnymi standardami wyższego poziomu (np. FIPA, MAF), zwiększając interoperacyjność aplikacji,
- potencjalna redundancja – Gotowa infrastruktura powinna „wyłączyć przed nawias” (factor out) wspólną funkcjonalność, podczas gdy komponenty aplikacyjne same muszą obsługiwać swoje własności operacyjne.
Analiza projektu, dotycząca zwłaszcza fazy przejścia pomiędzy specyfikacją logiczną, biznesową (np. diagram przepływu danych) a specyfikacją techniczną, powinna dostarczyć odpowiedzi na strategiczne pytania:
- Czy posłużyć się gotową infrastrukturą?- Jeśli tak, którą wybrać?- Jeśli nie, jakie funkcje zaimplementować w postaci ogólnie dostępnych usług?
Rozdz. 6 zawiera interesujące rozważania na ten temat. Zaproponowana tam metoda analizy zależności między regułami przetwarzania, choć pokazana jako element RAW, może dopomóc w podjęciu optymalnej decyzji dot. wszystkich trzech wymienionych kwestii. Klasy równoważności mogą identyfikować funkcje „systemowe” w ramach konkretnej aplikacji. W ten sposób termin „systemowy” trochę się relatywizuje. Funkcja nie jest sama z siebie systemowa. Jest raczej pewną współdzieloną usługą
11

ułatwiającą implementację pewnej grupy reguł przetwarzania. Takie rozumienie zadań infrastruktury przypomina koncepcję „struktur komponentowych” ([Szyperski], p. rozdz. 2.2), przeciwstawiającą sztywne rozumienie komponentu elastycznym, doraźnym i wymiennym strukturom wzajemnie kompatybilnych obiektów. Wspólnym mianownikiem prac badawczych prowadzonych w kierunku zapewnienia większej elastyczności rozproszonych aplikacji może być odejście od kompatybilności (zgodności operacyjnej) rozumianej w kategoriach 0-1 na rzecz pewnego continuum, dopuszczającej zgodność częściową. Przykładowo, w rozdz. 2.2, w punkcie komentującym osiągnięcia architektur agentowych, rozważa się kwestię zhierarchizowania systemów agentowych na wzór warstwowego protokołu sieciowego.
Agentowość-mobilność-autonomiczność
Refleksja Interfejs programowydokumentów
Rozszerzone Architektury Wielowarstwowe (RAW):-agentowość-komponentowość-dynamizm dokumentów-kooperacyjność
Wywołanie asynchronicznemetody
MBV -przekazywanieprzez wartość
Dynamiczny polimorfizm
Obiektowe protokoły komunikacyjne
nowe możliwośćisyntezy
Środowiskoimplementacji
własności
Postulowane cechy
.2 Rozszerzona architektura wielowarstwowa – metody i techniki
Wniosek z powyższej dyskusji nasuwa się jeden: zarówno intuicyjna analiza wymienionych „za i przeciw” jak i zastosowania metod formalnych mogą w istotny sposób przyczynić się do wyboru właściwej strategii tworzenia oprogramowania. Nie można w arbitralny sposób rozstrzygnąć, abstrahując od konkretnych zastosowań, o właściwym wyborze. Zawarte w rozdz. 7 przykłady eksperymentów implementacyjnych zawierają przykłady „intuicyjnej” analizy, zestawiającej techniki proponowane w rozprawie z konwencjonalnymi. Co do metody formalnej, to rozdz. 6 zawiera analizę jej własności kombinatorycznych oraz pewien „sztuczny” przykład o odpowiednio dużej złożoności, która wyklucza analizę przez człowieka.
12

Na. rys. .2 ujawniono strukturę pracy dot. pierwszej ze stawianych tez. Wychodząc od postulatów nowoczesnych architektur oprogramowania sformułowano zadania związane z technikami obsługi własności operacyjnych na poziomie protokołu obiektowego. Są nimi odpowiednio: przetwarzanie asynchroniczne, przekazywanie parametrów obiektowych przez wartość, implementacja refleksji. Wynikają one z ograniczeń protokołu obiektowego (por. rozdz. 2). W kolejnych punktach (A, B i C) zostanie bardziej szczegółowo omówiona zawartość rys. .2. Następnie zostanie omówiona zawartość poszczególnych rozdziałów rozprawy.
Komunikacja asynchroniczna
Model Obiektowy Model Komunikatowy
Poziom Aplikacji Poziom Systemu
.3 Klasyfikacja metod komunikacji asynchronicznej
A. Przetwarzanie asynchroniczne, autonomiczność agentów, uogólniona modalność
W obrębie programowania obiektowego, mianem komunikatu (message) określa się sygnał skierowany do obiektu mający na celu zmianę jego stanu i wykonanie pewnej operacji – wywołanie metody [Subieta1]. Pojęcia „metoda” i „komunikat” są ściśle z sobą związane, lecz nie tożsame. Z punktu widzenia rozważań o RAW i przetwarzaniu asynchronicznym wygodne będzie rozróżnienie między nimi jako alternatywnymi technikami komunikacji – komunikat (typ komunikatu) to pewien typ danych (np. WM_XXXX w Windows). Na odpowiednio wysokim poziomie rozważań abstrakcyjnych, w obrębie programowania obiektowego komunikat (message) oraz metoda [Kindberg] traktowane są jako sposób zmiany stanu obiektu. Jednak w praktycznych implementacjach, przy uwzględnieniu czynników natury technicznej, różnice stają się wyraźne: metody są to funkcje zadeklarowane w obrębie obiektu, natomiast komunikaty są pewnymi standaryzowanymi klasami obiektów, których wartości są następnie interpretowane. Znane mechanizmy przetwarzania asynchronicznego oparte są zarówno na transmisji zdarzeń [AMETAS], [Mole], [Kindberg], [Clark], [Pattison] jak i na systemowych mechanizmach protokołów obiektowych [Prosi2], [Hubert]. Rys. .3 pokazuje próbę sklasyfikowania, z punktu widzenia prezentowanych rozważań, możliwych metod. Dalej zostaną krótko omówione rozwiązania MSMQ, April, Poczta Elektroniczna (SMTP), DCOM oraz podejście proponowane w ramach RAW.
Jako przykład implementacji Modelu Komunikatowego niech posłuży April [Clark] (Agent Process Implementation Language), w którym architektura komunikacji jest
13

osadzona na poziomie konstrukcji języka programowania. Komponenty systemu opartego o April przyjmują postać procesów systemu UNIX, korzystających z komunikatowej infrastruktury komunikacyjnej. Infrastruktura komunikacyjna wykorzystuje protokół TCP/IP i składa się z kolejek komunikatów – po jednej na każdy węzeł (rys. .4).
Komunikację w ramach systemu April można scharakteryzować następująco:
- rozwiązanie zamknięte – osadzone w języku, bez obsługi mobilności agentów, narzucające każdorazowo konieczność przenoszenia (port) implementacji na docelowe platformy,
- brak potwierdzenia odbioru – chociaż niezbędne jest uzyskanie połączenia TCP/IP w momencie wysyłania komunikatu,
- ograniczona współbieżność obsługi komunikatów,- brak ułatwień dla współpracy z jakimkolwiek protokołem obiektowym.
Autorzy opisywanego rozwiązania zestawiają April z protokołem CORBA, jako architektury alternatywne.
Inną propozycją w obszarze Modelu Komunikatowego jest, tym razem chodzi o produkt firmowy, MSMQ (MS Message Query) [Pattison]. Oczywiście dostępny tylko dla Windows. MSMQ jest zaawansowaną składową systemu operacyjnego, zawierającą w sobie mechanizm grupowania komunikatów w transakcje oraz ułatwienia dla przesyłania obiektów DCOM (rozdz. 4.2 zawiera uwagi na ten temat przedstawione w kontekście nie MSMQ lecz mobilności agentów). Podstawowym zarzutem wobec MSMQ może być, podobnie jak wobec April, brak buforowania komunikatów po stronie nadawcy. Innymi słowy węzeł docelowy (kolejka komunikatów) musi być dostępna cały czas.
TCP/IP
Kolejka komunikatów
Węzeł sieci
.4 April (por. [Clark]) – przykład rozwiązania w Modelu Komunikatowym
Takiego mankamentu nie ma protokół pocztowy. Poczta, na ogół, jest postrzegana jako mechanizm wymiany informacji między użytkownikami. W mniejszym zakresie wykorzystywana jest jako narzędzie komunikacji między składowymi systemu, gdzie nadawcą i odbiorcą są procesy. Przykładem takiego wykorzystania, jednym z nielicznych, może być replikacja baz danych (np. Sybase ASA). Prezentowana w rozdz.
14

4.4 metoda przekazywania obiektów jest neutralna względem mechanizmu transmisji i może wykorzystać pocztę elektroniczną, pod warunkiem, że potraktuje się ją jako usługę (service), a nie rodzaj „infrastruktury”. Należy w tym miejscu zauważyć, że dostęp do poczty (protokół SMTP) nie wymaga żadnych środowisk czasu wykonania (innych niż standardowy dostęp do Internetu).
Kolejna grupa rozwiązań przedstawionych na rys..3, dotyczy protokołów obiektowych i obejmuje rozwiązania na poziomie systemowym i aplikacyjnym. Przykładem pierwszego z nich jest propozycja DCOM (dokładniej opisana w rozdz.3.3). Jak widać na rys..5 i tak musi gdzieś powstać wątek roboczy, który przetwarza równolegle asynchroniczne wywołanie. Umieszczenie go w warstwie systemu może odbyć się po stronie serwera (rys..5a) lub klienta (rys..5b). Preferowany jest pierwszy przypadek. Drugi dotyczy sytuacji, w której serwer działa pod kontrolą starszej wersji Windows, która nie obsługuje jeszcze systemowej asynchroniczności. Dokładne zestawienie metod „aplikacyjnej” i „systemowej” zawiera rozdz.3.1 W tym miejscu komentarz ograniczy się do krótkiej uwagi, że: po pierwsze umieszczenie wątku po stronie systemu daje mniejszą kontrolę nad nim*; po drugie zaś mechanizmy synchronizacji oferowane przez system, aczkolwiek niebagatelne, są ograniczone w stosunku do istniejących na poziomie aplikacyjnym.
Serwera) Wątek po stronie serwera (standard)
b) Wątek po stronie klienta
Obiekt docelowySystem (DCOM)
Sieć
Serwer
Obiekt docelowySystem (DCOM)
Sieć
Wątek roboczy
Wątek roboczy
Klient
Klient
.5 DCOM (por. [Prosi2])– Rozwiązanie na poziomie systemowym
* chociażby: aplikacja działająca na węźle wieloprocesorowym może wymagać utworzenia więcej niż jednego wątku dla obsługi wywołania – a więc obsługa „operacyjna” poza systemem.
15

Inaczej niż w istniejących rozwiązaniach, w niniejszej pracy proponuje się realizację asynchroniczności (i związanej z nią synchronizacji rozproszonych procesów) na poziomie aplikacyjnym. Rzeczywiście, tryb przetwarzania (synchroniczny -asynchroniczny) jest pewną cechą właściwą dla konkretnej reguły przetwarzania. Co więcej, rodzaj i sposób użycia przez konkretną regułę przetwarzania mechanizmów synchronizacji może być, dzięki proponowanej metodzie, elastycznie dostosowany do konkretnych potrzeb. W takim układzie, wywołanie synchroniczne jest najprostszym przypadkiem zastosowania mechanizmów synchronizacji.
Podstawowe cechy realizacji przetwarzania asynchronicznego na poziomie aplikacyjnym (rys..6):
- wykorzystanie interfejsu i środowiska czasu wykonania protokołu obiektowego,- możliwość przetwarzania wielowątkowego,- możliwość zastosowania elastycznego algorytmu (protokołu) synchronizacji
opartego o obiekty aplikacyjne.
Pierwsza z wymienionych cech oznacza, że nie jest potrzebne dodatkowe oprogramowanie realizujące środowisko czasu wykonania – przykładowo: wystarcza sam DCOM - nie ma konieczności przenoszenia na docelową platformę MSMQ. Druga cecha (właściwa również rozwiązaniom systemowym DCOM i CORBA) wynika z faktu, że przetwarzanie asynchroniczne jest ściśle związane z wielowątkowością. Równoległe wykonywanie funkcji nabiera szczególnego znaczenia w kontekście aplikacji rozproszonych – wykonywanych na wielu węzłach sieci, czyli wielu procesorach (por. wstęp do rozdz.3). Wreszcie, zastosowanie obiektów protokołu jako reprezentacji stanu „zsynchronizowania” pozwala na zupełnie dowolne przekazywanie danych pomiędzy rozproszonymi, równoległymi procesami.
Sieć
Serwer – wątek na poziomie aplikacji„Wskaźniki” do obiektów synchronizujących
przechowywane w wątku roboczym
Ob1 Proxy1
Ob2
ObN
...
Proxy2
ProxyN
...
Klient + obiekty synchronizujące
.6 Przetwarzanie asynchroniczne na poziomie aplikacji – RAW
16

Zależność między wywołaniem synchronicznym a modalnością (dot. stanu interfejsu użytkownika) prowadzi do sformułowania pojęcia modalności uogólnionej. W rozdz. 3.4 prezentowane są rozważania dotyczące związku trybu wywołania i interakcyjności. Modalność, określana jako ograniczenie możliwości interakcji użytkownika, jest ściśle związana z aktualnym stanem systemu. Uelastycznienie mechanizmu synchronizacji pozwala na większą swobodę w zakresie sterowania dostępnością elementów interfejsu.
B. Migracja obiektów, mobilność agentów
Druga klasa zagadnień omawianych w rozprawie dotyczy migracji obiektów. Migracja oznacza, że obiekty określonej klasy nie jest są na stałe przypisane do swojej przestrzeni adresowej i mogą ją zmieniać. Zmiana może odbywać się zarówno w obrębie jednego węzła sieci jak i całej sieci. Naturalnym rozwiązaniem byłoby osadzenie obsługi migracji na poziomie protokołu komunikacyjnego. Nie jest to takie proste. Szczegółowe omówienie zawiera rozdz. 2.3 (z punktu widzenia DCOM – migracja pokazana jako przekazanie parametru „przez wartość” – systemowe MBR Marshalling by Reference vs. aplikacyjne MBV) oraz wstęp do rozdz. 4 (rozważania dot. np. konstruktorów kopiujących w C++ i równoważności przekazania przez wartość oraz persystencji ).
Zatrzymanie
Określenie stanu agentapodlegającego migracji
Zapis egzemplarzaklasy
Zakodowanie zapisanegoegzemplarza
Uwierzyteln ieniewęzła źródłowego
Przesłanie danych
Odtworzenie stanu agenta
Utworzenie egzemplarzaklasy
Odczyt stanuoraz kodu
Rozkodowanie danych
Identyfikacja węzłaźródłowego
Uruchomienie
Odb
iór o
biek
tu
Inicjalizacja transferu
.7 Migracja obiektu – architektura MAF
Główne wyzwania dot. migracji obiektów zostaną podane za [Subieta2]:
- określenie jednostki migracji i postaci obiektów zmieniających swoje położenie,- śledzenie obiektów i aktualizacja połączeń,- aktualizacja katalogu baz danych (dot. obiektowych baz danych),- kompresja ścieżek dostępu,- obsługa migracji złożonych (compound) obiektów – zwierających wewnątrz
obiekty składowe lub odsyłacze do innych obiektów).
17

Trzeci punkt nie został poruszony w rozprawie. Odnośnie pozostałych RAW proponuje swoje rozwiązania, aczkolwiek niektóre pojawiają się implicite, narzucone jako skutek wyboru protokołu obiektowego w charakterze warstwy pośredniczącej.
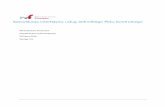
Z uwagi na architektoniczny charakter rozprawy przyjęta zostanie nieco inna niż ogólnie przyjęta klasyfikacja uwypuklająca zależność metody migracji względem protokołu komunikacyjnego (por. [Dollimore]). Reprezentatywnymi mechanizmami migracji mogą być metoda zastosowana w omawianym już MSMQ, osadzone w ramach języka Java ułatwienia dla trwałości obiektu oraz infrastruktury agentowe.
a) metoda uproszczona
Węzeł I Węzeł II
ObiektA
ObiektA’
1. Request(Move A)
2. Request(Move A)
3. Execute(A)
4. Quit(A)
b) metoda pełna
Węzeł I Węzeł II
Węzeł źródłowy
ObiektA
ObiektA’
2. Execute(A)
6. Inform(Transfer A)| Quit(A’)
3. Inform(Okay|Fail)
5.In form(Move A)
1. Request(Move A)4. Inform(Move A)
.8 Migracja obiektu – architektura FIPA
Język Java jest realizacją postulowanej od dawna metody realizacji przenaszalności oprogramowania za pomocą interpretowanego kodu pośredniego. Z tego też powodu ew. migracja obiektu znajduje w tym języku naturalne wsparcie. W istocie, transmisja kodu pośredniego oraz stanu obiektu może dokonać się bez konieczności dostarczania dodatkowych mechanizmów obsługujących ten proces. Tym właśnie należy tłumaczyć dominującą pozycję Javy w dziedzinie agentów mobilnych (np. Mitsubishi Concordia) oraz w CE. Należy jednak zauważyć, że osadzenie mechanizmów migracji w
18

konstrukcji języka nie jest korzystną cechą. Co więcej, migracja w Javie nie odnosi się w wyraźny sposób do wymienionych już zagadnień jak śledzenie obiektów czy migracja obiektów złożonych.
Z kolei MSMQ pozwala na przeźroczyste przekazywanie obiektów danych w postaci treści komunikatu. „Silnie polimorficzne” pole data jest w stanie obsłużyć dowolną daną binarną prostego (nieobiektowego) typu. Natomiast, jeśli jest nią obiekt ActiveX, to zakłada się, że potrafi on zapisać swój stan w sekwencyjnym strumieniu (implementuje określony interfejs). W tym miejscu należy zauważyć, że wspomniany interfejs można zaimplementować również w obiekcie nie będącym pełnym komponentem. Fakt ten może być postrzegany jako istotna przewaga DCOM, który pozwala obiektowi elastycznie (programista ma swobodny wybór) implementować wiele interfejsów, nad protokołem CORBA. W terminach programowania obiektowego oznacza to (nieformalnie) rodzaj dynamicznego wielodziedziczenia (możliwe również w czasie wykonywania –dziedziczenie dynamiczne).
Oczywiście każda infrastruktura agentowa musi zawierać ułatwienia dla migracji obiektów. Przykładami specyfikacji takich infrastruktur są FIPA oraz MAF. Specyfikacja FIPA określa dwa sposoby migracji: uproszczoną oraz pełną. Metoda uproszczona zakłada, że węzeł systemu agentowego jest w stanie zidentyfikować stan obiektu poddawanego migracji i przekazać go do węzła docelowego. Metoda ta może więc być uznana za wariant persystencji sterowanej zewnętrznie (container managed persistency) – rys. .8a. Metoda pełna oparta jest o współudział obiektu, który zostaje poinformowany o konieczności dostarczenia swojego stanu w postaci umożliwiającej jego odtworzenie na węźle docelowym. W terminologii Javy można uznać to za persystencję sterowaną wewnętrznie (por. bean managed persistency specyfikacji EJB) rys. .8b. Z kolei MAF przedstawia migrację jako uporządkowany ciąg procesów. Z rys. rys. .7 wynika, że chodzi w tym przypadku o pewien bardziej złożony proces, obejmujący również uwierzytelnienie. Nasuwa się w tym miejscu wątpliwość, czy takie zintegrowanie procesu migracji jest właściwe. Samo przekazanie obiektu przez wartość jest pewnym dobrze zdefiniowanym zadaniem, uzasadniającym jego wyodrębnienie.
Metoda zawarta w RAW wychodzi z założenia, że zdolność do migracji jest pewną własnością obiektu i jako taka może być jedynie implementowana na poziomie aplikacyjnym. W kwestii cytowanych już problemów związanych z migracją, należy zauważyć że:
- Migracja w ramach protokołu obiektowego określa jednostkę migracji, którą jest obiekt tego protokołu.
- Każdy system rozproszony wymaga utrzymywania przestrzeni nazw, pozwalającej rozstrzygać logiczne identyfikatory obiektów. Ułatwienia dla przestrzeni nazw przyjmują postać tzw. usług katalogowych, które mogą być
19

użyte dla lokalizacji mobilnych agentów. W rozdz. 2.3 pokazano jak w prosty sposób można zintegrować obiekty DCOM z dowolną (również SQL-ową) usługą katalogową.
- Kompresja ścieżek dostępu może być wykonywana dynamicznie na poziomie protokołu. Trzeba w tym miejscu zauważyć, że jest zagadnienie ogólniejsze i tzw. kompresja dot. również unifikacji termów w języku prolog czy instrukcji equivalence w fortranie (por. [Warren], [Ban76], [Galler]).
- Występowanie złożonych obiektów jest silnym argumentem na rzecz podejścia aplikacyjnego. Fakt, czy składowa ma być skopiowana do nowej przestrzeni adresowej czy pozostać dostępna jako referencja należy do kompetencji danego obiektu. W ramach przyjętej metody powinny być możliwe obydwa warianty. W terminach programowania obiektowego jest to wybór pomiędzy tzw. głębokim i płytki kopiowaniem (shallow vs. deep copy - por. [RougeWave])
Zaproponowana w rozprawie technika rozdzielonej (split) migracji obiektu oparta jest na niezależnym transferze kodu (definicji klasy) oraz stanu obiektu. Ma ona tę zaletę, że ułatwia zastosowanie niezależnych implementacji dla poszczególnych węzłów sieci. Dzięki temu, migracja (mobilność agentów) przestaje być cechą wyłącznie operacyjną. Poszczególne wcielenia obiektu (agenta) mogą dynamicznie dostosowywać się zarówno do zmieniających się warunków technicznych jak i do zmian w środowisku informacyjnym, tym samym stając się podstawą zaproponowanego podejścia do problematyki wielowarstwowych baz danych.
C. Refleksja, dynamiczny polimorfizm, dokumenty dynamiczne
Istotnym problemem w obszarze aplikacji rozproszonych jest kwestia dostępności definicji typów danych. Zagadnienie to daje się sformułować zarówno w terminach ograniczeń protokołu obiektowego (statyczna struktura typów por. rozdz. 2.3) jak i postulatów stawianych w obszarach eksperymentalnych architektur oprogramowania (refleksja, dynamiczne dokumenty). Z jednej strony, składowe binarne (skompilowane) systemu rozproszonego nie zawierają informacji o używanych typach danych, z drugiej zaś, dynamiczna konfiguracja i rekonfiguracja może doprowadzić do pojawienia się nowych typów, formatów plików, dokumentów itd.
Z całą pewnością języki interpretowane są pod tym względem bardziej elastyczne od języków kompilowanych. To właśnie podczas procesu kompilacji, konkretnie konsolidacji, usuwana jest tablica symboli, zawierająca informacje o typach danych. Dlatego też, języki interpretowane (skryptowe) mogą wydawać się atrakcyjną możliwością zwiększenia elastyczności systemu rozproszonego. W ogólności można podać następującą klasyfikację metod służących do przezwyciężenia ograniczeń „statycznej struktury typów”:
20

- określenie standardów wyższego poziomu, tzw. business object dla poszczególnych dziedzin,
- wprowadzenie jawnej binarnej reprezentacji typów, - polimorfizm,- refleksja programowa.
Pierwsza z wymienionych możliwości (zaproponowana w [Manola]) wydaje się mało realna jako rozwiązanie ogólne. Jest to po prostu próba zdefiniowania i sklasyfikowania wszystkich możliwych typów danych używanych w określonych dziedzinach programowania. Niemniej, należy zauważyć, że idea standaryzowanych dokumentów (np. EDIFACT, HL7) sprawdziła się w pewnych klasach zastosowań. Ciekawe, że praca [Manola] odwołuje się w jednym z rozdziałów do refleksji programowej, proponując pomysły będące w zasadzie jej zaprzeczeniem.
a) wywołanie statyczne
adresatoridentyfiakklasaf ),( method
b) wywołanie polimorficzne
adresatoridentyfiakobiektf ),(VTBLVTBL
method
c) implementacja dynamicznego polimorfizmu
adrestatoridentyfiakobiektf ),,(TApp
IDispatch
GetIDsOfNames
Invoke
.9 Klasyfikacja trybów wywołania metody
Kolejna możliwość to zachowanie tablicy symboli. Przykładem takiego postępowania jest byt określany jako biblioteka typów, funkcjonujący w ramach protokołu DCOM. Biblioteka typów, związana ściśle z tzw. automatyzacją OLE, ma na celu wsparcie integracji języków skryptowych (interpretowanych np. VisualBasic) oraz binarnych komponentów (ActiveX). Przyjmując definicję refleksji (refleksji lingwistycznej) zawartej w [Subieta1] można zauważyć, że biblioteka typów jest, przynajmniej częściową jej realizacją. Argumentem na rzecz tej tezy niech będzie tzw.
21

import biblioteki typów, polegający na automatycznym wygenerowaniu kodu źródłowego w jęz. pascal (Delphi). Przykładem wykorzystania bibliotek typów przez architektury mogą być propozycje OpenDCOM i OpenORB [Coulson], gdzie „refleksyjność” (czyli jawna reprezentacja stanu systemu w postaci pewnej struktury danych) systemu przybiera postać dynamicznego grafu ze statycznymi bibliotekami typów jako wierzchołkami.
Wspomniane już pojęcie polimorfizmu użyte jest w swoim „technicznym” znaczeniu, w którym chodzi o tzw. późne wiązanie (late binding). Z punktu widzenia integracji oprogramowania i przetwarzania rozproszonego polimorfizm jest niezbędny. Na rys. .9 przedstawiono klasyfikację trybów wywołania metody obiektu. Wywołanie statyczne to identyfikator zamieniony na adres w procesie konsolidacji pliku wykonywalnego – adres metody wyznaczany jest na podstawie identyfikatora w kontekście klasy. Zwykły polimorfizm oznacza, że adres jest funkcją konkretnego obiektu i typu metody. Możliwość ta wynika z faktu, że obiekt przechowuje, w czasie wykonania, informację o klasie. Informacja ta przybiera postać tablicy VMT (Virtual Method Table).
W rozprawie proponowany jest mechanizm dodatkowego uelastycznienia polimorfizmu o parametr czasu. Wykorzystanie mechanizmów automatyzacji OLE umożliwia bieżące interpretowanie tablicy symboli, która może przyjąć postać dowolnego zasobu danych (np. atrakcyjna możliwość użycia w tym charakterze DTD z języka XML). Podejście to jest zastosowaniem pewnej ogólnej zasady opóźniania obliczeń i podstawiania w miejsce stałej pewnej funkcji, wyznaczającej wartość na żądanie. W tym przypadku żądanie dotyczy rozstrzygnięcia identyfikatora. Zasadnicze cechy mechanizmu określanego jako „dynamiczny polimorfizm”:
- użycie tylko jednego typu danych DCOM dla wszystkich komponentów – IDispatch - jest on jednocześnie rodzajem typu samoopisującego się,
- możliwość dynamicznej zmiany typu, gdyż rozstrzygnięcie identyfikatora może odbywać się poprzez wywołanie funkcji,
- połączenie możliwości języków interpretowanych (elastyczność) i kompilowanych (wydajność),
- ułatwienie przetwarzania zmiennych w czasie dynamicznych dokumentów.
Przeprowadzone eksperymenty dowodzą, że wywołanie przez dynamiczny polimorfizm jest trochę wolniejsze. Niemniej w przypadku wywołania zdalnego węzła różnice są nieistotne. Co więcej, można mówić o skalowalności rozwiązania – i wykonywaniu optymalizacji w sytuacjach, gdzie zezwalają na to konkretne reguły przetwarzania. Np. jeśli wiadomo, że w określonym stanie dynamiczny dokument nie będzie zmieniał swej struktury, to rozstrzygnięcie identyfikatorów można wykonać jednorazowo.
22
Omówienie zawartości rozdziałów
Trzon pracy stanowią rozdz. 3-6, w których zawarto oryginalne wyniki z zakresu technik programowania za pomocą protokołu obiektowego (rozdz. 3-5, zawierające opisy odpowiednio: symulacji wywołania asynchronicznego, przekazywania parametrów obiektowych przez wartość, dynamicznego polimorfizmu) oraz (rozdz. 6) z zakresu metod algorytmicznej analizy grafowych diagramów zależności. Analiza zależności odbywa się pod kątem występowania wierzchołków równoważnych, co ma na celu identyfikację komponentów. Rozdz. 6 zwiera prezentację dwóch przypadków użycia (case study) oraz jedno studium wykonalności (feasibility study). W ramach przedstawionych w rozdz. 7 eksperymentów implementacyjnych z RAW, szczególną uwagę zwrócono na porównanie nowych możliwości dostępnych dzięki zaproponowanym rozszerzeniom z innymi konwencjonalnymi architekturami. Uzasadnienie proponowanych technik (rozdz. 3-5) zawarto we wstępnych podrozdziałach, które oprócz wprowadzenia w zagadnienie zawierają opisy użytych w nich pojęć oraz krótki opis idei przewodnich proponowanego rozwiązania. Przede wszystkim starano się uzasadnić nieadekwatność rozwiązań na poziomie systemowym (protokołu czy też prefabrykowanej infrastruktury). Dalsze podrozdziały zawierają odpowiednio techniczny opis implementacji oraz szczegółowe uzasadnienie tez. Dalej zostaną krótko omówione treści prezentowane w kolejnych rozdziałach zawierających oryginalne wyniki.
Rozdz. 3 zawiera omówienie technik wywołania asynchronicznego oraz propozycję implementacji w protokole DCOM Przedstawione jest znaczenie komunikacji asynchronicznej. Po pierwsze, ukazana została jako podstawa technicznej implementacji autonomiczności agentów. Po drugie, wprowadzono pojęcie uogólnionej modalności, do realizacji której symulacja wywołania asynchronicznego może służyć, dostarczając rozszerzonych mechanizmów synchronizacji między klientem a serwerem lub w ogólniejszym przypadku między dostawcą informacji a jej konsumentem. Po trzecie, pewne znane ze standardu POSIX obiekty synchronizacji wraz z obiektowymi protokołami komunikacyjnymi mogą być podstawą implementacji sieciowych obiektów synchronizacyjnych.
W rozdz. 4 zaprezentowano technikę przekazywania parametrów obiektowych przez wartość (MBV Marshaling By Value). Przedstawiona jest dyskusja istniejących rozwiązań oraz własne propozycje. Przekazywanie parametru przez wartość i możliwość utworzenia jego kopii w obszarze adresowym wywołania sieciowego ma fundamentalne znaczenie dla implementacji mobilności agentów (por. [Muel]). W terminach protokołu obiektowego mobilność jest niczym innym jak utworzeniem kopii agenta na zdalnym urządzeniu i przydzieleniem mu zasobów i uprawnień w przestrzeni adresowej tego urządzenia. Innym zastosowaniem przekazywania przez wartość może być realizacja postulatów [Nierstrasz] programowania zorientowanego komponentowo
23

(componentware). Poprzez agregację komponentu można symulować na poziomie binarnym konstrukcje programowe znane z języków C++ czy ADA (wzorce i pakiety rodzajowe).
Coraz bardziej widoczna jest tendencja do reprezentowania interfejsu użytkownika poprzez dokumenty [Manola], [Flynn] – rozumiane jako zasoby danych spełniające wymogi formalnych standardów. Zagadnienie tworzenia, przechowywania i przetwarzania dokumentów elektronicznych staje się jednym z głównych wyzwań [Flynn]. Rozdz. 5 zawiera propozycję uelastycznienia interfejsu IDispatch (automatyzacji OLE), tak by mógł on stanowić obiektowy interfejs dostępu do dokumentu elektronicznego. Przedstawiono zastosowanie dynamicznego polimorfizmu w konkretnych systemach informatycznych oraz możliwości wykorzystania go do przetwarzania w obszarze komunikacji B2B (np. EDI, XML). Zaproponowano też mechanizm obiektowego dostępu do usług katalogowych (np. takich jak X500, NDS Active Directory) czy komponentowej reprezentacji rekurencyjnych struktur danych. Co więcej, mechanizmy oparte na elastycznym interfejsie IDispatch okazują się być niczym innym niż (przynajmniej częściową) realizacją mechanizmu refleksji [Edmo], [Kiczales], postulowanego jako jeden z atrybutów architektur kooperacyjnych. W kontekście architektur oprogramowania refleksja może służyć do przezwyciężenia ograniczeń związanych ze statyczną strukturą typów danych*. W przeciwieństwie do rozwiązań prezentowanych dotychczas w literaturze [Stroud], [Kari], [Kiczales], zaproponowany w pracy mechanizm ma znaczenie praktyczne i jest przeznaczony do wykorzystania w implementacji rzeczywistych systemów.
Z1 Z2 Z3
SR1 SR2 SR3
C1
C2
C3
C4
Z1 Z2 Z3
SR1 SR2 SR3
Z1~Z3
f1
f2
f3
f4
f5
f6
.10 Wyznaczanie relacji równoważności –identyfikacja komponentów
* Por. rozdz. 2 ograniczenia obiektowego protokołu komunikacyjnego z punktu widzenia postulatów stawianych przez architektury oprogramowania.
24

W rozdz. 6 zaproponowano algorytm automatycznej analizy diagramu przepływu danych reprezentowanego przez zaetykietowany graf skierowany. Celem zaprezentowanego algorytmu jest dostarczenie narzędzia pozwalającego porządkować diagramy o dużych rozmiarach oraz licznych powiązaniach. Inaczej niż w przypadku prefabrykowanej infrastruktury – tworzenie infrastruktury specjalizowanej wymaga każdorazowo pewnych nakładów związanych z określeniem składowych oraz usług (ułatwień czy też obsługi własności poza-funkcjonalnych). Algorytm analizy na wyjściu podaje klasy równoważności wierzchołków grafu (rozpatruje się diagram przepływu danych). W pracy pokazano, że określona w ten sposób równoważność wierzchołków może być podstawą do identyfikacji komponentów w systemie wielowarstwowym rys. (1.3) oraz łączenia tychże komponentów w serwery aplikacji, komponenty i przypisywanie im własności operacyjnych. Podana metoda umożliwia wyznaczenie klas równoważności w czasie nlog (n). Bazuje ona na podanym przez Hopcrofta ogólnym schemacie wyznaczania największej partycji. Dodatkowo algorytm może być wykorzystany do znajdowania automorfizmów w grafach i innych obiektach kombinatorycznych.
W zakończeniu (rozdz. 8) zaprezentowana jest analiza wpływu proponowanych rozwiązań na techniki implementacji i projektowanie aplikacji w architekturach wielowarstwowych. Jeszcze raz pojawia się w pracy kwestia rozdzielenia funkcjonalnych i poza-funkcjonalnych cech systemu informatycznego. Przedstawione są też tematy dalszych prac badawczych oraz implementacji. Dotyczy to zwłaszcza problemu znajdowania relacji równoważności indukowanej przez grupę automorfizmów oraz badania izomorfizmu grafów. Z uwagi na dynamicznie rozwijające się prace w obrębie architektur oprogramowania dokonano też krótkiego przeglądu technik, które mogą być uznane za alternatywne lub komplementarne w stosunku do prezentowanych w rozprawie, a które pojawiły się w trakcie redakcji.
25

2. Obiektowe protokoły komunikacyjne
Z uwagi na szczególne znaczenie jakie w zagadnieniach architektur aplikacji mają obiektowe protokoły komunikacyjne, rozdział ten jest poświęcony opisowi ich sposobu funkcjonowania oraz własności. Szczególny nacisk zostanie położony na cechy ściśle związane z tematyką i wynikami zawartymi w rozprawie. Dotyczy to zwłaszcza kierunków badań w obszarze architektur oprogramowania.
Można zaryzykować tezę, że o ile pojawienie się konwencjonalnych mechanizmów komunikacji sieciowej zaowocowało pojawieniem się architektury klient serwer, to rozwój obiektowych mechanizmów komunikacji przyniósł w efekcie nowy sposób widzenia zagadnień architektur oprogramowania. Bez możliwości oferowanych przez obiektowy model komunikacji praktycznie nie do pomyślenia byłyby implementacje, wdrożenia czy choćby zakrojone na szerszą skalę eksperymenty obliczeniowe z zakresu nowoczesnych architektur.
Rozwój systemów operacyjnych i protokołów komunikacyjnych
Abs
trak
cja
wła
snoś
ci o
pera
cyjn
ych
Aplikacje monolityczne
Architekturadwuwarstwowa
Architekturatrójwarstwowa
Architekturawielowarstwowa
Programowaniesieciowe
RPC
Komunikacjaw modelu zdarzeniowym
Przekazywanieobiektów
2.1. Mechanizmy komunikacji sieciowej i rozwój architektur [Singer]
Komunikacja międzyprocesowa IPC uważana może być za część składową systemu operacyjnego. System operacyjny UNIX oraz standard zawierający wymogi dla przenośnego oprogramowania POSIX określają m.in. dostępne sposoby wymiany danych między procesami oraz interfejs programisty pozwalający na korzystanie z nich. Podobnie interfejs sieciowy oraz protokoły obiektowe mogą być sklasyfikowane jako składowa systemu. Niemniej, z uwagi na znaczną objętość swojej specyfikacji i
26

implementacji oraz podstawową rację swego bytu jaką jest niezależność systemowa, protokoły komunikacyjne rozpatruje się jako wyodrębnioną część.
Chociaż istnieje wiele standardów sieciowych protokołów obiektowych (w tym trzy wiodące DCOM,CORBA,RMI) to mają one następujące cechy wspólne:
- niezależność platformowa,- niezależność językowa (wyjątek RMI): język IDL służy wyłącznie do
deklarowania obiektów,- obiektowy model programowania,- przeźroczystość położenia (location transparency).
Pojawienie się i intensywny rozwój obiektowych protokołów komunikacyjnych jest na ogół łączony z wyzwaniami związanymi z rozwojem aplikacji dla Internetu. Pogląd taki nie wydaje się do końca uzasadniony, choć niewątpliwie prawdziwa eksplozja Internetu przyczyniła się w znaczący sposób do wzrostu zainteresowania obiektowymi mechanizmami komunikacji.
Uwagi historyczne [Gopalan] Początek prac nad standardowym protokołem sieciowym, opartym na modelu obiektowym datuje się na rok 1989. Niezależne gremium - OMG - zaproponowało wtedy pewien standard, którego podstawową składową była CORBA (Common Object Request Broker Architecture) – przyjęta ostatecznie w roku 1991. Następna wersja standardu określała zasady komunikacji pomiędzy systemami heterogenicznymi. Propozycja OMG spotkała się z dużym zainteresowaniem zarówno środowisk akademickich jak producentów oprogramowania, czego skutkiem było pojawienie się licznych implementacji standardu.
Równolegle do OMG powstało, tym razem jako inicjatywa jednej firmy, ciało o nazwie Active Group, którego celem miało być opracowanie modelu obiektowej komunikacji dla systemu Windows. Jako punkt wyjścia przyjęto istniejącą składową tego systemu OLE - z którą to wynik prac Active Group miał zapewniać zgodność na poziomie binarnym. W ten sposób powstały: model obiektowy COM/DCOM oraz standard komponentów ActiveX Ważne jest następujące rozróżnienie: o ile COM/DCOM jest specyfikacją pewnego protokołu komunikacji międzyprocesowej, której wiodącej (ale nie jedynej) implementacji dokonała jedna firma, to ActiveX określa pewien standard komponentu przeznaczony dla implementacji przez niezależnych twórców oprogramowania. W ogólności należy zauważyć, że obiektowe protokoły przyjmują postać implementacji, natomiast specyfikacje komponentów pozostają jedynie pewnymi konwencjami programowania określającymi wymogi operacyjne, które obiekt musi spełniać by zostać uznanym za komponent. Podobnie techniczne wyniki przedstawione w niniejszej pracy mają charakter propozycji pewnych konwencji, dzięki którym składowe systemu informacyjnego nabierają cech właściwych architekturom: agentowym, komponentowym czy kooperacyjnym.
27

Niezależnie od różnic historycznych i nieco odmiennych stawianych im celów zarówno CORBA jak i DCOM należą do tej samej klasy oprogramowania. Co więcej, dostępne są mechanizmy integracji obydwu protokołów za pomocą oprogramowania pośredniczącego.
2.1. Protokół obiektowy DCOM
Tradycyjny model komunikacji międzyprocesowej wykorzystywał plik sekwencyjny jako podstawowy mechanizm wymiany danych. Otwarcie kanału komunikacyjnego między dwoma procesami, również wykonywanymi na różnych węzłach sieci następowało w wyniku wywołania funkcji systemowych, zwracających daną identyfikującą plik. Podejście to było związane z jednej strony z ogólną koncepcją systemu UNIX, gdzie plik sekwencyjny był bytem abstrakcyjnym reprezentującym urządzenia zewnętrzne i co za tym idzie, operacje wejścia i wyjścia. Z drugiej strony plik sekwencyjny naturalnie współgrał z czwartą warstwą modelu komunikacji sieciowej ISO-OSI [Tanen]. Warstwa ta, zwana warstwą transportową, udostępnia usługę niezawodnego strumienia danych, realizując zadania związane z uporządkowaniem datagramów, retransmisją buforowaniem. Plik sekwencyjny był więc idealną strukturą danych reprezentującą usługi warstwy transportowej.
a) Obiekt lokalny
b) Obiekt zdalny
2.2 Komunikacja w protokole DCOM [Gopalan]
Komunikacja międzyprocesowa za pośrednictwem pliku, nie jest jednak rozwiązaniem optymalnym z punktu widzenia programowania aplikacyjnego. Coraz większa popularność modelu obiektowego sprawiła, że niezbędne stały się mechanizmy komunikacji, w których kanał komunikacyjny byłby dostępny w postaci egzemplarza klasy. W modelu obiektowym procesy wymieniają dane poprzez wywoływanie metod czy też zmianę wartości atrybutów.
28

Protokół DCOM powstał w wyniku rozszerzenia modelu komponentowego COM o możliwości sieciowe. Jego składowymi są:
- przenośny język definicji interfejsów IDL (interface definition language),- oprogramowanie komunikacyjne ORPC (object remote procedure call), oraz
interfejs programisty (API)- zestaw definicji standardowych interfejsów.
Otwarcie kanału łączności następuje poprzez utworzenie obiektu (rys.2.3c). Tworzony obiekt określony jest poprzez identyfikator klasy (unikalny w danym kontekście) oraz adres sieciowy węzła (np. adres TCP/IP). Proces żądający utworzenia obiektu nazywa się w tym przypadku klientem natomiast proces realizujący to żądanie serwerem.
a) Oznaczenie symboliczne (UML)
TApp
IApp
function DoIt;
IUnknown
b) Deklaracja (Pascal)
IApp = interface(IUnknown) ['{B14BACCD-429E-47E4-B2DF-AAE591A31ACE}'] function DoIt: HResult; stdcall; end;
c) Odwołanie do obiektu po stronie klienta
var app:IApp;begin app= CreateRemoteComObject(‘tytan.kari.put.poznan.pl’,IID_IApp);//VCL app.DoIt;end;
2.3 Obiekt DCOM (perspektywa interfejsu programisty)
Po utworzeniu obiektu klient może wywoływać metody obiektu DCOM oraz modyfikować jego stan poprzez przypisywanie wartości atrybutom. Z punktu widzenia klienta nie ma znaczenia, gdzie dany obiekt naprawdę rezyduje. To znaczy, wywołanie metody odbywa się w ten sam sposób niezależnie od tego, czy obiekt znajduje się na tym samy węźle, czy na węźle zdalnym. Ta własność protokołu nazywana jest niezależnością lokacyjną (location transparency)(rys. 2.2).
29

Klasa obiektu DCOM określa jednoznacznie pewien obiektowy typ danych, czyli zestaw dostępnych metod oraz atrybutów. W terminologii DCOM taki zestaw nosi nazwę interfejsu (rys. 2.3b). Obiekt określonej klasy może udostępniać szereg interfejsów. Jest to cecha charakterystyczna DCOM. Istotną zaletą takiego podejścia jest możliwość grupowania komponentów w pewne struktury, kolekcje na podstawie implementowanych interfejsów. Przykładowo lista łączona zawierająca obiekty obsługujące trwałość (persistency) może sama taką trwałość implementować. Możliwość udostępniania wielu interfejsów przez obiekt DCOM przypomina wielodziedziczenie. Istotnie, w implementacji konkretnego obiektu DCOM (np. w C++) można się tymże wielodziedziczeniem posłużyć. Implementowanie wielu interfejsów przez jeden obiekt w DCOM , związane jest ściśle z ActiveX.
Moduł binarny implementujący obiekt DCOM może być w zależności od potrzeb biblioteką ładowaną dynamiczną (DLL w Windows , SO w Linux) lub samodzielnym modułem wykonywalnym. W terminologii DCOM określa się te implementacje jako:
- In-Process Server: biblioteka dynamiczna lub OCX, metoda wywołana korzysta z wątku klienta,
- Out-of-Process Server: moduł wykonywalny, na czas wywołania następuje przełączenia na wątek serwera,
- Remote Server: j.w., z tym że moduł wykonywalny rezyduje na zdalnym węźle.
O ile korzystanie z metod i atrybutów obiektu jest w pełni niezależne od postaci modułu binarnego, to dość złożone są w tym przypadku kwestie współbieżnością. Dot. to zwłaszcza bibliotek dynamicznych. W DCOM wprowadza się pojęcie tzw. apartamentu (apartment) oznaczające wątek w którym odbywa się wykonanie metod danego obiektu. Ponieważ dla rozważanych tu zagadnień podstawowe znaczenie mają postacie binarne Remote i Out-of Process, kwestie te nie będą tu szerzej omawiane. Szczegóły można znaleźć w [Platt]. Szczegółowe uzasadnienie nieadekwatności modelu apartamentowego dla implementacji aplikacji wielowarstwowych znajduje się w rozdz. 3, gdzie omówione zostaną zagadnienia wielowątkowości w aplikacjach rozproszonych, zwłaszcza dot. DCOM.
2.2. Eksperymentalne warianty architektur wielowarstwowych
W ramach prac nad architekturami wielowarstwowymi wykrystalizowały się trzy zasadnicze kierunki: agenci, komponenty oraz systemy kooperacyjne. Kierunki te są względem siebie zarówno komplementarne (np. cytowana dalej komponentowa architektura agentowa) jak i alternatywne. Cechą wspólną dotychczasowych dokonań są próby określenia monolitycznej warstwy pośredniczącej*. Warstwa ta – zbudowana
* Pewnym wyjątkiem może być podejście do komponentów reprezentowane przez [Szyperski] – gdzie warstwa pośrednicząca jest zhierarchizowaną strukturą.
30

nad protokołem komunikacyjnym – ma dostarczać standardowych usług ułatwiających realizację własności poza-funkcjonalnych.
IMetaInterception
ILifeCycle
IMetaInterface
IMetaArchitecture Custom Service
IUnkonwn
MetaInterception
MetaArchitecture
MetaInterface
OpenCOMIMetaArchitecture
IOpenCom
IUnkonwn
Type Libraries
System Graphs
2.4 Składowe architektury OpenDCOM [Coulson]
Architektury komponentowe Cechą charakterystyczną konwencjonalnego podejścia do programowania jest ścisłe rozgraniczenie pomiędzy fazą tworzenia systemu informatycznego oraz jego działania. Faza powstawania systemu dzieli się w klasycznym modelu na szereg etapów obejmujących przykładowo: określenie założeń, projekt (tworzony na wielu poziomach abstrakcji), specyfikację techniczną, kodowanie, testowanie oraz wdrożenie.
Powyższy sposób postępowania jest ściśle związany z architekturami: monolityczną i klient serwer. Programy powstałe w oparciu o te architektury mają określoną strukturę:
31

(moduły procedury) dostępną jedynie na poziomie kodu źródłowego. Możliwość ingerencji w sam system w czasie jego funkcjonowania ogranicza się do parametrów przewidzianych w założeniach projektowych.
Podstawowym celem, który stawiają sobie twórcy architektur komponentowych jest zmiana tego stanu rzeczy. Aplikacja komponentowa ma być złożona z pewnego zbioru składowych, które udostępniają sobie nawzajem usługi korzystając jednocześnie z dostępnych zasobów danych i komunikując się ze stacjami roboczymi użytkowników. Podstawową metodą tworzenia aplikacji ma być kompozycja - rozumiana jako proces łączenia i konfigurowania komponentów programowych w jeden spójny system realizujący specyficzne reguły przetwarzania.
Pomyślna realizacja procesu tworzenia aplikacji komponentowej wymaga stworzenia specjalnej strategii rozwoju oprogramowania oraz ścisłego określenia reguł i standardów dla obiektów mających być komponentami. Co więcej, musi istnieć infrastruktura operacyjna zapewniająca mechanizmy komunikacji pomiędzy poszczególnymi składowymi systemu oraz wspierająca mechanizm kompozycji.
Istotnym problemem jest fakt, że proces konsolidacji klasycznego modułu wykonywalnego (link-time) usuwa z binarnego obrazu informacje o symbolach i adresach. Informacje te są jednak niezbędne, jeśli system ma w przyszłości poddawać się dynamicznej rekonfiguracji. Powinny one być dostępne dla mechanizmów obsługujących kompozycję i zapewniać możliwość dynamicznego odwzorowania nazwy, logicznego identyfikatora na fizyczny adres umożliwiający wywołania funkcji względnie uzyskanie dostępu do danych. Pod tym względem rysuje się zdecydowana przewaga języków interpretowanych nad kompilowanymi. Należy zauważyć, że przechowywanie informacji o symbolach jest w każdym wypadku związane ze zwiększonym zapotrzebowaniem na pamięć oraz zmniejszeniem wydajności. Przykładami struktur danych umożliwiających dynamiczną konsolidację i tworzenie obiektów mogą być CRuntimeClass (Visual C++), TypeLibrary (DCOM/IDL) czy też RTTI (Delphi). Dwa ostanie zostaną szerzej omówione w rozdz. 6.
Zgodność jednostek programowych – będących komponentami - na poziomie binarnym (zapewniana np. przez użycie odpowiedniego protokołu obiektowego) nie jest wystarczająca. Wymagana jest również zgodność operacyjna, oznacza ona pewien zbiór standaryzowanych wymagań. Przyjmują one najczęściej postać definicji interfejsów obiektowych, które obiekt musi implementować. Najbardziej znanym takim standardem jest ActiveX. Chociaż nie jest to standard ściśle związany z jakimś konkretnym systemem informatycznym, to – przynajmniej w pewnym zakresie – zorientowany jest on na współpracę z pakietem MSOffice.
32

O ile ActiveX jest przykładem pewnego ogólnego standardu, to istnieją koncepcje tworzenia standardów specjalizowanych (o ograniczonym zakresie) [Szyperski]. Standardy te miałyby obowiązywać w ramach określonych klas aplikacji, zastosowań (komunikacja, starowanie, multimedia) czy też nawet pojedynczych realizacji [Coulson]. Standardy te określa się jako struktury (Component Frameworks).
Dalszym krokiem w mającym na celu umożliwienie pełniejszej integracji komponentów w ramach systemu jest określanie standardów na jeszcze wyższym poziomie – funkcjonalnym [Manola]. Oprócz zgodności binarnej i operacyjnej komponenty miałyby zapewniać realizację pewnych standardowych funkcji przetwarzania danych, implementując konkretne reguły przetwarzania, w sposób pozwalający na ich wielokrotne wykorzystanie – tzw. Business Objects. Postuluje się zdefiniowanie standardowych typów danych (dokumentów) dotyczących pewnych dziedzin (np. handel międzynarodowy, wymiana naukowa, podatki). Dzięki temu zwiększa się możliwość ponownego wykorzystywania prefabrykowanych komponentów, co więcej standaryzowane dokumenty i reguły przetwarzania powinny dać szansę lepszej integracji pomiędzy całymi systemami. Chociaż standaryzacja funkcjonalna może się wydawać mało realna to postępujące procesy globalizacji oraz integracji organizmów państwowych gospodarczych mogą być tu istotnym czynnikiem stymulującym.
Architektury kooperacyjne W zależności od obszaru zainteresowań konkretnych badaczy (architektury oprogramowania lub bazy danych) przyjmuje się, że podstawowymi cechami kooperacyjnego systemu informatycznego są refleksja programowa [Kiczales] lub odejście od dwufazowego blokowania [Rusin]. Chociaż z punktu widzenia niniejszej rozprawy istotniejsze jest ujęcie architektoniczne to kwestie związane z odejściem od dwufazowego blokowania [Bernstein] wpisują się w zagadnienie wielowartswowości aplikacji i zostaną poruszone w rozdz. 4.5.
Pojęcie refleksja programowa (software reflection) pojawiło się w pracach [Maes] oraz [Kiczales]. Podobnie jak w przypadku architektur komponentowych powodem, którym kierowano się proponując mechanizmy refleksji było dążenie do zatarcia ostrego rozgraniczenia pomiędzy fazami tworzenia oprogramowania i jego eksploatacji. Chodziło przede wszystkim o możliwość dynamicznej konfiguracji i rekonfiguracji systemu w oparciu o samoopisujące się jednostki programowe (software entities).
W swej istocie refleksja spełnia jeden z postulatów z obszaru architektur komponentowych – zachowuje informacje o obiektach, które przy konwencjonalnym podejściu dostępne są jedynie w fazie kompilacji i konsolidacji modułu wykonywalnego. Różnica pomiędzy obydwoma architekturami dotyczy odmiennego rozłożenia akcentów (w architekturze kooperacyjnej dostęp do informacji o strukturze działającego systemu jest celem samym w sobie) oraz użytych metod. Niemniej
33

uzasadnione jest stwierdzenie, że obydwie architektury są w jakiś sposób komplementarne wobec siebie.
W zaproponowanej w pracy [Coulson] rekonfigurowalnej platformie pośredniczącej wyodrębniono warstwę usługową (OpenDCOM) odpowiedzialną za realizację usług związanych z refleksją programową. Korzystająca z jej usług warstwa wyższa (OpenORB) ma z kolei charakter par excellence komponentowy przyjmując postać wspomnianych już struktur komponentowych (Component Framework). Refleksja programowa w OpenDCOM jest oparta o biblioteki typów, które ze względu na swój statyczny charakter wykazują pewne ograniczenia: mogą być jedynie w całości wymieniane. Zaproponowana w rozdz. 5 konwencja tzw. dynamicznego polimorfizmu rozwiązuje ten problem, zezwalając obiektowi na większą elastyczność dot. jego struktury.
Architektury agentowe Historycznie rzecz biorąc, to właśnie architektury agentowe były pierwszym pomysłem dotyczącym rozwoju rozproszonych systemów informatycznych. Pierwsze prace pojawiły się już w latach 80-tych. Zajmowały się one zarówno kwestiami dotyczącymi algorytmów rozproszonych jak i zagadnień technicznych związanych ze środowiskami czasu wykonania oraz problematyką środowisk heterogenicznych.
Z czasem wykrystalizowały się dwa nurty poszukiwań:
- Rozproszona Sztuczna Inteligencja (Distributed Artificial Intelligence): szczególny wariant sztucznej inteligencji zajmujący się możliwościami prowadzenia procesów obliczeniowych w środowisku rozproszonym, z dostępem do niejednorodnych zasobów informacyjnych oraz ze szczególnym naciskiem na zadania integracji, współdziałania wielu autonomicznych podmiotów realizujących wspólny cel,
- Komponentowe Architektury Agentowe, gdzie celem badań było zdefiniowanie środowiska czasu wykonania zapewniającego możliwość pomyślnej implementacji agenta programowego.
Podstawowym pytaniem w ramach drugiego z wymienionych kierunków jest: „czy istnieją pewne wspólne cechy środowiska czasu wykonania, właściwe dla wszystkich systemów agentowych oraz jakimi cechami powinny wyróżniać się narzędzia służące do tworzenia systemów agentowych” [Martin].
Chociaż metoda agentów programowych była przez pewien czas uważana za jedyny sposób tworzenia rozproszonych środowisk obliczeniowych, to na obecnym etapie rozwoju uzasadniony jest pogląd, że jest ona szczególnym przypadkiem architektury komponentowej. W istocie, agent programowy (np. agent mobilny) może być uważany za pewien rodzaj komponentu (a więc jednostki programowej zgodnej z określonym
34

standardem) posiadającym zdolność przetwarzania asynchronicznego oraz zmiany węzła sieci.
W komponentowym podejściu do architektur obiektowych rozróżnia się dwa podstawowe typy obiektów. Mianowicie:
- system agentowy: reprezentujący węzły sieci świadczące usługi systemowe agentom, (rys. 2.5 – Agent Management System, Directory Facilitator)
- agent mobilny: komponent implementujący reguły przetwarzania, przede wszystkim związane z algorytmami sztucznej inteligencji.
Usługi systemowe w architekturze agentowej obejmują m.in. zarządzanie cyklem istnienia agenta, mechanizmy komunikacji, migrację. Wymienione usługi tworzą rodzaj infrastruktury technicznej dostarczając agentom mechanizmów umożliwiających im pomyślne wykonywanie zadań określonych przez reguły przetwarzania.
Wiele architektur agentowych dołącza do infrastruktury technicznej usługi wyższego rzędu, implementujące synchronizację procesów czy też zaawansowane protokoły negocjacyjne. Mechanizmy tego typu są ukierunkowane na wspomaganie implementacji algorytmów rozproszonych.
Szczególną rolę odgrywają w tym przypadku definicje standardów. Ważne jest, by agenci mobilni (podobnie jak obiekty w obiektowym protokole komunikacyjnym) mogli korzystać z węzłów systemu agentowego zaimplementowanych niezależnie od siebie. Dlatego też architektury agentowe funkcjonują przede wszystkim w postaci specyfikacji typów obiektowych w ramach określonego protokołu. W terminologii architektur komponentowych można tę specyfikację określić jako strukturę komponentową Component Framework.
Powszechnie akceptowana struktura komponentowa, określająca węzły systemu agentowego i definiująca typ agenta mobilnego umożliwia niezależne tworzenie składowych systemu informatycznego. Umożliwia też łatwą integrację istniejących systemów, czy też ponowne wykorzystanie istniejących modułów.
Dwoma najbardziej znanymi standardami są obecnie FIPA [FIPA] Foundation for Intelligent Physical Agents oraz MAF Mobile Agent Facilty [MAF]. Drugi z wymienionych jest rodzajem struktury komponentowej w ramach protokołu CORBA. Stanowi on zbiór wytycznych dla twórców systemów agentowych, mających zapewnić możliwość bezproblemowej ich współpracy – podobnie jak specyfikacja GIOP zapewnia kompatybilność protokołu CORBA.
Niewątpliwą wadą wspomnianych specyfikacji jest ich dużą objętość i konieczność poniesienia znacznych nakładów w przypadku ich implementacji. O ile w przypadku standardów protokołów obiektowych nakłady te są uzasadnione powstaniem
35

atrakcyjnego rynkowo produktu, to implementacja systemu agentowego powinna być raczej zorientowana na konkretne zastosowania.
Prawdopodobnie rozwiązaniem mogłoby być podanie standardu w postaci warstwowej – podobnie jak w przypadku protokołów sieciowych. Kompatybilność agenta programowego mogłaby być w tym przypadku realizowana na różnych poziomach. Najniższy poziom oznacza wtedy konkretny protokół obiektowy – tzn. agent jest obiektem np. DCOM. Na wyższych poziomach kompatybilność byłaby związana z obsługą określonych funkcji operacyjnych, implementowanych za pomocą standaryzowanych interfejsów (por. ActiveX). Na najwyższym poziomie agent współpracuje z protokołami negocjacyjnymi, które wspierają implementację algorytmów synchronizacji w systemach wieloagentowych (por. [Bernd]).
AgentManagement
System
DirectoryFacilitator
AgentCommunication
Channel
Agent1
Agent2
DCOM
Host A Host B
An example implementation of FIPA compliant AA
GatewayAgent3<<wrapper>>
Agent4
Legacy Other FIPA
2.5. Implementacja FIPA i protokół DCOM por.[Sheremetov]
Częściowa kompatybilność sprawia, że agent kompatybilny na poziomie funkcji operacyjnych czy też usług katalogowych mógłby korzystać ze wsparcia dla migracji podczas swojej wędrówki przez rozproszony system. Z jednej strony warstwowa specyfikacja przypomina model odniesienia ISO-OSI dla protokołów sieciowych, który to model określa siedem warstw: od poziomu sprzętu do poziomu aplikacji. W tym układzie warstwa wyższa korzysta z usług warstwy niższej, sama natomiast udostępnia swoje usługi kolejnej warstwie. Z drugiej strony standard określający architekturę agentową stanowi rodzaj struktury komponentowej: [Szyperski] zhierarchizowanego i zmodularyzowanego zestawu specyfikacji (norm definicji), w którym poszczególne
36

składowe stanowią wymienne podsystemy – tak samo jak w przypadku organizacji protokołu sieciowego.
2.3. DCOM i architektury oprogramowania.
Jak widać na rys. 2.3c protokół DCOM może być postrzegany jako mechanizm pozwalający na tworzenie (deklarowanie) obiektów danych z możliwością określenia ich lokalizacji. Jedynym wyróżnikiem jest fakt, że obiekt może być utworzony jedynie przy pomocy jawnego wywołania funkcji a nie np. deklaracji w sekcji var. Jest to związane z dążeniem do oddzielenia języka i protokołu, poprzez udostępnienie tego drugiego za pośrednictwem interfejsu programisty (API) oraz z faktu, że w protokole obiektowym nie występują z oczywistych względów obiekty statyczne (choć występują obiekty trwałe).
Okazuje się jednak, że nawet tak atrakcyjna możliwość, jak rozszerzenie deklaracji danej o określenie lokalizacji (węzła sieci) nie jest wystarczająca dla zadań integracji środowiska rozproszonego. W protokole DCOM są następujące ograniczenia:
- Statyczna struktura typów (na rys 2.3c zmienna app) – należy zadeklarować typ określający interfejs. Typ ten musi być określony w momencie kompilacji.
- Brak możliwości dostępu do istniejących obiektów – innymi słowy chodzi o odpowiednik słowa kluczowego extern znanego z języka C.
- Metody mogą być wywoływane jedynie w sposób synchroniczny.- Parametry wywołań będące egzemplarzami klas mogą być przekazywane tylko w
trybie przez zmienną (MBR – marshal by reference).
Należy zauważyć, że wymienione problemy nie są wynikiem przeoczeń ze strony twórców protokołów – wynikają one z istoty problemu. Krótkim uzasadnieniem* niech będzie fakt, że dotyczą one również pozostałych protokołów (CORBA i RMI) .
Pierwszy wymieniony problem – statyczna struktura typów – ma znaczenie z punktu widzenia zadań dynamicznej konfiguracji i rekonfiguracji systemu rozproszonego. Wymóg, by komponenty można było wymieniać, zastępować i rekonfigurować jest związany z pojawianiem się nowych klas (typów obiektowych). Co więcej, w związku z przetwarzaniem dynamicznych dokumentów reprezentowanych przez komponenty DCOM zmieniać się może struktura dokumentu (w sensie typu danych). Próbami częściowego rozwiązania ograniczeń statycznych typów w DCOM/CORBA/RMI są odpowiednio: biblioteki typów (type library – rozdz. 6), DII (dynamic interface invocation [Stal]) oraz Java Reflection. Możliwość dynamicznego zmieniania klasy obiektu i rozpoznawanie jego składowych (atrybutów oraz metod) jest pożądana we wszystkich trzech wariantach architektur wielowarstwowych. Propozycję rozwiązania problemu w ramach RAW zawiera rozdz. 5.3.
* Dokładniej każde z ograniczeń jest omówione w odpowiednich rozdziałach pracy
37

Kwestia dostępu do istniejących obiektów DCOM została stosunkowo wcześnie zauważona przez autorów związanych z czasopismami technicznymi [Prosise1, Prosise2]. Po pierwsze trzeba powiedzieć: DCOM (jeszcze jako OLE) oferował rodzaj przestrzeni nazw oraz mechanizm umożliwiający dostęp do współdzielonych obiektów. Można było korzystać z obiektów określanych jako moniker – które dokumentacja określała jako „inteligentne ścieżki do plików” . Istotnie, dzięki strukturze danych ROT (Running Objet Table) możliwy jest przeźroczysty dostęp do obiektów „aktywnych” (istniejących w danej chwili) jak i obiektów zapisanych w ramach dokumentów MSOffice (lub innych aplikacji obsługujących OLE/COM i implementujących moniker’y). Po drugie: DCOM pozwala na tworzenie obiektów tzw. singleton, które występują tylko w jednym egzemplarzu i jako takie są dzielone przez wszystkich klientów wywołujących CreateComObject dla tej klasy. Ograniczenia tego rozwiązania są oczywiste. Zwłaszcza, że w artykule [Box1] podane są argumenty przeciwko serwerom typu singleton.
function GetKeyedObject(key:string):variant;var bs:TBlobStream; sa:TStreamAdapter; disp:IDispatch;beginwith TQuery.Create(nil) dobegin
SQL.Add(Format('select ObjRef from ObjMap where ’+ ’ ObjKey='#39'%s'#39,[Key])); Open; bs:=TBlobStream.Create(TBlobField(Fields[0]), bmRead); sa:=TStreamAdapter.Create(bs); CoUnMarshalInterface(sa as IStream,IDispatch,disp); result:=disp; Free;end; end;
2.6. Uzyskanie dostępu do obiektu DCOM identyfikowanego przez klucz z bazy SQL
W powołanych artykułach proponowana jest m.in. metoda. polegająca na modyfikacji serwera obiektowego DCOM, w taki sposób by utrzymywał bazę danych o utworzonych już obiektach. Prosta baza zawierać ma połączenie obiektu i pewnej nazwy. Rozwiązanie to nie jest zadowalające gdyż:
- nakłada na programistę obowiązek każdorazowego implementowania „magazynu” istniejących już obiektów oraz uniemożliwia dostęp do istniejących obiektów utworzonych przez serwery dostępne jedynie w postaci binarnej (konieczność ingerencji w kod źródłowy),
- nie ma możliwości współpracy ze standardowymi protokołami obsługującymi przestrzeń nazw (typu X500) lub bazami danych, uwaga dot. zwłaszcza baz umożliwiających replikację
38

Drugi z podanych zarzutów dot. w praktyce wszystkich monolitycznych infrastruktur pośredniczących [Ovum]. Na obecnym etapie rozwoju, systemy operacyjne oferują zaawansowane usługi katalogowe, będące silnym a co najważniejsze standaryzowanym narzędziem obsługi rozproszonej przestrzeni nazw. Idealnym rozwiązaniem byłaby możliwość zapisywania rekordów składających się z klucza (nazwy logicznej) oraz przeźroczystego co do położenia i zrozumiałego dla DCOM wskaźnika do obiektu. Okazuje się, jest że możliwe to dzięki pewnemu nadużyciu funkcji CoMarshalInterface oraz wykorzystaniu wirtualnych strumieni danych (rys. 2.6 ). Szczegóły zawiera praca [Sikor02].
Zagadnienia wywołania asynchronicznego oraz przekazywania obiektu przez wartość są opisane szczegółowo w rozdz. 3 i 4. W tym miejscu rozważania zostaną ograniczone do stwierdzenia, że o ile podjęta została próba (DCOM dla Windows 2000) dodania asynchroniczności na poziomie systemowym., to nie jest ona satysfakcjonująca Są dalej dwie możliwości wątki robocze osadzone w komponencie lub wspomniane, nowe rozszerzenie DCOM. Decyzja o użyciu mechanizmów asynchronicznych na poziomie systemu sprowadza się do pytania: czy dużym nakładem (kod związany z „biurokracją” - rozdz. 3.3) należy tworzyć wątek roboczy na poziomie systemowym, czy raczej jawnie uruchamiać wątki robocze wewnątrz komponentu, zyskując tym samym większą elastyczność w zakresie organizacji obliczeń oraz ew. synchronizacji za pomocą obiektów przekazanych przez referencję. Jak pokazano w rozdz. 3 przetwarzanie asynchroniczne na poziome aplikacji to w istocie kwestia wielowątkowości w systemie złożonym z rozproszonych komponentów.
Odmienne w stosunku do DCOM podejście zaproponowano w protokole CORBA funkcja może być zadeklarowania jak jednokierunkowa oneway. W tym miejscu należy zauważyć, że komunikacja w sieci jest z natury asynchroniczna – polega na wysyłaniu i odbieraniu ramek (frame) z danymi. Protokół DCOM symuluje przetwarzanie synchroniczne w komunikacji asynchronicznej, by później znowu symulować asynchroniczność. Podejście w CORBA jest bardziej eleganckie i polega na bezpośrednim odwołaniu się do warstwy sieciowej. Metoda w tym przypadku nie dostarcza mechanizmów późniejszej synchronizacji. Mogą być one jednak zaimplementowane na poziomie aplikacyjnym [Hubert].
39

3. Przetwarzanie asynchroniczne
Zagadnienie przetwarzania asynchronicznego stosunkowo późno znalazło się w obszarze problematyki badawczej związanej z programowaniem aplikacyjnym. Przyczyną takiego stanu rzeczy był brak obsługi wywołania asynchronicznego w językach programowania, gdyż dostępność tego mechanizmu jest raczej cechą środowiska systemu operacyjnego. Tak więc, w definicji standardów niektórych języki w ogóle z niego zrezygnowano (C,C++) [Stroust] lub zdecydowano się symulować takie przetwarzanie w środowisku czasu wykonania (np. ADA) por. [Kempe]
Przetwarzanie asynchroniczne było związane raczej z programowaniem systemowym, szczególnie zaś sterownikami urządzeń. O ile warunkiem koniecznym dla przetwarzania asynchronicznego jest możliwość równoległego wykonywania operacji, to większość urządzeń może pracować niezależnie od CPU. W pracach badawczych z obszaru programowania aplikacyjnego asynchroniczność pojawiła się razem z architekturami agentowymi [Muel]. Wywołanie asynchroniczne było w tym przypadku operacyjną realizacją autonomiczności. Kolejnym obszarem, w którym kwestie asynchroniczności nabrały znaczenia były obiektowe protokoły komunikacyjne.
Z punktu widzenia komunikacji w ramach warstwy pośredniczącej istotne jest spostrzeżenie, że sprzęt sieciowy (działający na zasadzie komutacji pakietów) z natury działa w sposób asynchroniczny. Dopiero wyższe warstwy protokołu (w tym obiektowe) zapewniają przetwarzanie synchroniczne.
Obiektowe protokoły komunikacyjne (DCOM, CORBA, RMI), których częścią składową jest język definicji interfejsu IDL, mogą być uważane za element systemu operacyjnego [Platt]. Stanowią one wygodne narzędzie dostępu do usług sieciowych i przetwarzania rozproszonego dla funkcji aplikacyjnych. Protokół obiektowy, w odróżnieniu od sieciowych interfejsów niskiego poziomu, operuje na typach danych charakterystycznych dla programowania aplikacyjnego - takich jak: obiekty, metody, własności, identyfikatory czy interfejsy. Zlikwidowana w ten sposób została „luka semantyczna” pomiędzy warstwami aplikacyjną oraz systemową. Konsekwencją zacierania wspomnianej „luki semantycznej” może być, w skrajnym przypadku, również stopniowe zacieranie się granic pomiędzy tymi dwoma rodzajami programowania. Wśród protokołów obiektowych szczególną pozycję, związaną z popularnością systemu Windows, zdobył sobie DCOM.
Obiektowy protokół komunikacji DCOM jest również dostępny poza środowiskiem Windows. Obok niezaprzeczalnych zalet ma on również pewne mankamenty (rozdz. 2.3.). Najpoważniejszym z nich, z punktu widzenia systemów czasu rzeczywistego czy też wielowątkowego programowania aplikacyjnego jest brak mechanizmu wywołania
40

asynchronicznego [Sikor00a]. W rozdziale tym zostanie zaprezentowany mechanizm symulacji takiego wywołania. Pokazane zostanie też wykorzystanie protokołów obiektowych w kontekście rozwoju oprogramowania opartego o serwery aplikacji i architektury wielowarstwowe umożliwiające zintegrowanie opisywanej metody z protokołami aplikacyjnymi wyższego rzędu – architektur wielowarstwowych (MIDAS).
Przetwarzanie asynchroniczne w ramach tworzenia aplikacji opartych na architekturze wielowarstwowej nabiera samodzielnego znaczenia. Znaczenie to nie ogranicza się tylko do możliwości symulacji pewnych cech operacyjnych agentów. Już w przypadku konwencjonalnej architektury Klient-Serwer występował problem oczekiwania na zbiór wynikowy otrzymywany jako rezultat zapytania. W czasie oczekiwania na wynik z serwera aplikacja najczęściej znajdowała się w stanie modalnym. Możliwość przetwarzania asynchronicznego była zależna od operacyjnych cech danego serwera baz danych lub sterownika czy też innego elementu pośredniczącego [Tom] (należącego jednak też do warstwy systemowej). Dzięki dostępności wywołania asynchronicznego w warstwie aplikacyjnej – istnieje możliwość implementacji reguł przetwarzania dostarczających znacznie bogatszych mechanizmów synchronizacji między klientem i serwerem (w ogólności między dostawcą informacji i jej konsumentem, gdyż w architekturze wielowarstwowej nie występują już klient i serwer). Co więcej, obiekty protokołu komunikacyjnego mogą pełnić funkcję sieciowych elementów synchronizacyjnych (semaforów) lub przynajmniej stanowić interfejs dostępu do takowych.
3.1. Tryby wywołania funkcji
Funkcja lub procedura może być wywołana na dwa sposoby: synchroniczny lub asynchroniczny. W przypadku wywołania synchronicznego jednostka wywołująca czeka na zakończenie wykonywania funkcji. Inaczej jest w przypadku wywołania asynchronicznego – po rozpoczęciu wykonywania funkcji następuje powrót do jednostki wywołującej. Wywołana asynchronicznie funkcja może (i tak się najczęściej dzieje) przekazać wywołującej jednostce obiekt synchronizujący. Obiektem tym może być semafor, dzielony obszar pamięci lub adres kolejki komunikatów. Jednostka wywołująca jest za pośrednictwem przekazanego obiektu zawiadamiana o zakończeniu wykonywania funkcji asynchronicznej.
Jak już wspomniano, języki programowania na ogół nie dostarczają mechanizmów wywołania asynchronicznego. Dzieje się tak, ponieważ ich dostępność zależy bardziej od systemu operacyjnego i sprzętu niż od języka. Dlatego też tego rodzaju dostępne są poprzez API systemu operacyjnego lub poprzez pewne standardowe mechanizmy i biblioteki rozszerzające możliwości tego systemu.
41

Przykładem implementacji różnych trybów wywołań na poziomie systemu mogą być funkcje SendMessage oraz PostMessage. Pierwsza z nich to synchroniczne przekazanie funkcji WndProc komunikatu systemowego. Druga funkcja powoduje jedynie umieszczenie komunikatu w kolejce okna i natychmiastowy powrót z wywołania. Bardziej wyrafinowanym przykładem mogą być funkcje przetwarzające pliki, które posługują się strukturą OVERLAPPED (dosł. „nakładające się”). Dostęp do plików, a zwłaszcza czytanie dużych ilości danych, jest operacją czasochłonną. Dlatego projektanci systemu uznali za wskazane dostarczenie mechanizmów asynchronicznego wywołania, umożliwiających aplikacji przetwarzanie danych podczas oczekiwania na zakończenie operacji plikowych. Ponieważ kanały transmisji sieciowej takie jak socket czy pipe również mogą być traktowane jako pliki, tym ważniejsza była dostępność tego typu mechanizmów.
W typowych aplikacjach, które nierzadko wykonują masowe operacje uaktualniania czy przeszukiwania baz danych istnieje uzasadniona potrzeba wywołań asynchronicznych. Podstawowy – w obszarze Windows- protokół dostępu do baz danych ODBC dostarcza wyłącznie funkcji synchronicznych (wersje 3.0). Jedyną możliwością jest w tym przypadku stworzenie jawnego wątku, w ramach którego zostanie synchronicznie wywołana funkcja ODBC. Rozwiązanie takie, aczkolwiek zadowalające ma tę wadę, że wymaga od programisty użycia mechanizmu niskiego poziomu, w żaden sposób nie związanego z logiką przetwarzania. Istotny jest fakt, iż aplikacja w pewnych sytuacjach nie musi czekać na zakończenie transakcji należy również do tej logiki.
Dlatego też korzystne byłoby wprowadzenie mechanizmu „wyższego poziomu”, jakim jest wywołanie asynchroniczne. Dzięki mechanizmom udostępnianym przez standardowe protokoły możliwe jest wywołanie metody serwera zarówno w obrębie jednego urządzenia jak i wywołanie sieciowe. W wywołaniu sieciowym istnieje w dalszym ciągu możliwość przekazywania i obsługi obiektów synchronizujących.
Ponieważ obiektem synchronizującym może być dowolny obiekt, istnieje możliwość przekazania jednostce wywołującej dodatkowych danych – na przykład o statusie zakończonej transakcji. Obiekt przekazywany może również zawierać w sobie dowolny obiekt synchronizujący. Może nim być semafor. Dzięki temu zastosowanie mechanizmu wysokiego poziomu, jakim w stosunku do jawnie tworzonego wątku jest wywołanie asynchroniczne, w niczym nie umniejsza elastyczności rozwiązania. Aplikacja nadal dysponuje pełną możliwością reagowania na ewentualne zdarzenia mające miejsce podczas przetwarzania danych przez funkcję asynchroniczną.
42

3.2. Przetwarzanie asynchroniczne - RAW
Można przyjąć, że na poziomie aplikacji (przede wszystkim aplikacji wielowarstwowej) zagadnienie asynchronicznego wywołania funkcji dotyczy możliwości przetwarzania wielowątkowego. O ile na poziomie systemu operacyjnego asynchroniczność jest możliwa dzięki równoległej pracy urządzeń oraz jednostki centralnej, to aplikacja, by mieć taką zdolność, musi być wykonywana przez zbiór wątków. Różnicą w stosunku do klasycznej aplikacji wielowątkowej jest fakt, że poszczególne wątki mogą być wykonywane w ramach wielu procesów i mogą rezydować na różnych węzłach sieci. Z tego powodu szczególnie ważne jest zapewnienie mechanizmów synchronizacji, które byłyby w stanie funkcjonować w sieci.
Powyższa obserwacja, dot. równoważności funkcji asynchronicznej i rozproszonej wielowątkowości jest podstawą zaproponowanej metody. Przede wszystkim należy zauważyć, że w najprostszym przypadku funkcja może jedynie zainicjować wątek roboczy i zakończyć działanie (pozostawiając „osierocony” wątek). Ma to miejsce gdy jednostka wywołująca nie potrzebuje żadnych danych o zainicjowanym przetwarzaniu. Na ogół jednak potrzebny jest przynajmniej status jakim operacja zakończyła się. Potrzebny jest więc mechanizm, który zawiadomi wywołującego o zakończeniu, innymi słowy dokona synchronizacji procesów.
Programowanie asynchroniczne w ramach RAW oparte jest na następujących przesłankach:
- realizacja własności poza funkcjonalnej, jaką jest aynchroniczność wywołania, odbywa się na poziomie aplikacyjnym;
- obiekt DCOM zawiera wewnętrzne wątki, które realizują funkcje aplikacyjne;- synchronizacja odbywa się za pośrednictwem osadzonych w wątku obiektów
DCOM, które przekazane są przez referencje (MBR - Marshaling by Reference);- jeżeli pominąć sprawy niezawodności (zależne od protokołu sieciowego i
sprzętu) to współdzielony obiekt DCOM może być implementacją semafora sieciowego.
Zgodnie z powyższym zostanie teraz przedstawiony przykład implementacji, w którym wywołana metoda Asynchronous tworzy wątek i przechowuje daną identyfikująca obiekt synchronizujący. Z uwagi na prostotę synchronizacja sprowadza się do wyświetlenia komunikatu po stronie klienta (wywołanie metody Done).
Wszystkie interfejsy użyte w implementacji są interfejsami dualnymi – tzn. obsługiwane są zarówno przez VMT jak i mechanizm IDispatch. Obydwie deklaracje zamieszono jedynie dla interfejsu ICallback – pozostałe prezentowane są tylko w wersji IDispatch.
43

W implementacji występują dwa interfejsy: jeden z nich reprezentuje obiekt, którego metoda jest wywoływana (IMidas), drugi jest obiektem synchronizującym (ICallback). Określenia obiekt synchronizujący w odniesieniu do ICallback używamy tylko w kontekście prezentowanego rozwiązania.
Metoda Done obiektu synchronizującego jest wykonywana po zakończeniu przetwarzania przez funkcję wywołaną asynchronicznie. W przykładzie funkcja ta wyświetla po prostu komunikat dla użytkownika. Nic nie stoi na przeszkodzie, by w tym miejscu był na przykład podnoszony semafor czy obsługiwany jakiś inny obiekt synchronizujący. Ważna jest jednak uwaga (rys. 3.3.), że jeżeli obiekt Callback ma być użyty w wątku roboczym to należy ten obiekt przekazać z pośrednictwem pary funkcji: CoMarshalInterThreadInterfaceInStream - CoUnMarshalInterface*.
type TCallback = class(TAutoObject, ICallback) protected procedure Done; safecall; end;
implementationuses ComServ,Dialogs;
procedure TCallback.Done;begin MessageDlg('Done',mtInformation,[mbOk],0)end;initialization TAutoObjectFactory.Create(ComServer, Tcallback, Class_Callback, ciMultiInstance);
3.1. Implementacja obiektu synchronizującego (ICallback –interfejs dualny)
IMidasDisp = dispinterface ['{5289D1A1-E2B8-11D3-979A-0000F4D20379}'] function GetProviderNames: OleVariant; dispid 22929905; procedure ShowWindow(const text: WideString); dispid 1; procedure HideWindow; dispid 2; procedure Asynchronous( Callback: IDispatch); dispid 3; procedure Method1(x: OleVariant); dispid 4; end;
3.2 Deklaracje serwera (tylko IDispatch)
Należy zwrócić uwagę na zasadniczą ideę prezentowanego rozwiązania: Interfejs ICallback jest widoczny w obrębie metody wywołanej asynchronicznie wyłącznie jako interfejs typu IDispatch. Dzięki temu nie jest konieczne deklarowanie odpowiadającego mu typu. Z kolei sam obiekt związany z tym interfejsem istnieje w przestrzeni procesu
* Dot. modelu apartamentowego, omówione w rozdz. 3.3 , też [Platt] lub dokumentacja - plik ole.hlp
44

wywołującego i dzięki temu może być użyty przez wątek roboczy do zawiadomienia tego procesu o zakończeniu przetwarzania.
Metody interfejsu należącego do serwera aplikacji mogą być wywoływane w dowolny sposób: synchroniczny i asynchroniczny. W rzeczywistości wszystkie one wywoływane są synchronicznie. Jedynie zastosowany mechanizm symulacji sprawia, że niektóre z nich przekazują sterowanie do procesu wywołującego natychmiast po uruchomieniu wątku roboczego.
procedure TMidas.Asynchronous(Callback: IDispatch);begin intf:=Callback; WorkThread.Init(callback);end;
3.3. Implementacja metody asynchronicznej
Symulacja asynchroniczności odbywa się ponad warstwą protokołu komunikacyjnego i może to być uznane również za wadę prezentowanego rozwiązania. Powrót z wywołania następuje dopiero po przekazaniu parametrów, w tym obiektu synchronizującego, uruchomieniu wątku roboczego. Można jednak zauważyć, że nawet jeśli mechanizm wywołania asynchronicznego byłby realizowany w ramach samego protokołu, to konieczność obsługi obiektów synchronizujących uniemożliwia natychmiastowy powrót z takiego wywołania.
procedure Tform1.Button3Click(Sender: TObject);const IID_IDispatch: TGUID = ( D1:$00020400;D2:$0000;D3:$0000;D4:($C0,$00,$00,$00,$00,$00,$00,$46));
var Intf:IUnknown; Cbck:IDispatch;begin Intf:=TCallback.Create; Intf.QueryInterface(IID_IDispatch,cbck); RemoteServer1.AppServer.Asynchronous(cbck);//MIDAS!end;
3.4. Wywołanie przekazujące obiekt synchronizujący
DCOM może znaleźć zastosowanie jako mechanizm komunikacji pomiędzy komponentami realizującymi funkcje krytyczne pod względem czasowym oraz
45

komponentami odpowiedzialnymi za prezentację stanu oraz interakcję z użytkownikiem. Dodanie mechanizmu wywołania asynchronicznego w istotny sposób zwiększa walory protokołu DCOM w kontekście systemów sterujących urządzeniami czy monitorujących złożone procesy technologiczne.
Przedstawiona technika, chociaż zaprezentowana w ramach architektury MIDAS (Borland Delphi), może być zastosowana również niezależnie od niej. Zastosowanie architektury wielowarstwowej i dekompozycja oprogramowania (por. rozdz. Error:Reference source not found) na komponenty pozwala wyodrębnić jednostki realizujące zadania krytyczne pod względem czasu wykonania i niezawodności oraz te, w przypadku których najistotniejszym czynnikiem może być elastyczność dialogu z użytkownikiem. Wszystko to może przyczynić się zarówno do wzrostu niezawodności oprogramowania jak i efektywności procesu jego rozwoju.
3.3. Asynchroniczne przetwarzanie na poziomie DCOM
Zostanie teraz omówiona próba rozszerzenia protokołu DCOM o wywołanie asynchroniczne. Na początek należy zauważyć, że problematyka przetwarzania wielowątkowego jest w tym protokole opisywana przez tzw. model apartamentowy. W pewnym uproszczeniu można przyjąć, że apartament obiektu jest to wątek, w którym została wywołana metoda jego utworzenia. Z uwagi na stopień w jakim implementacja obiektu umożliwia współbieżny dostęp (poprzez ochronę zmiennych globalnych, instancyjnych za pomocą semaforów) DCOM może zezwalać na niczym nie ograniczony dostęp do obiektu lub może stosować uszeregowanie poszczególnych żądań. Szeregowanie to odbywa się poprzez otwarcie kanału komunikacyjnego (tzn. zamiast normalnego polimorfizmu przez VMT , tworzony jest systemowy obiekt pośredniczący)
Model apartamentowy jest dość skomplikowany i w dużej mierze służy jedynie jako pretekst do wyrafinowanych rozważań na temat implementacji serwerów obiektowych i ew. ich optymalizacji. Przeciwko temu modelowi można sformułować następujące zarzuty:
- wynika on z ewolucyjnego rozwoju protokołu – OLE COM DCOM, a zwłaszcza przejścia z 16 na 32 bity;
- optymalizacja polegająca na wywołaniu przez VMT ma sens tylko przy wywołaniu lokalnym;
- w architekturze wielowarstwowej składowe mają najczęściej postać modułów wykonywalnych;
- w przypadku serwera MTS tak rozumiana wielowątkowość jest i tak przeźroczysta;
46

- wprowadzono model apartamentowy Free w celu wymuszenia na systemie wykonawczym by utworzył kanał komunikacyjny, w sytuacji, gdy zgodnie z modelem apartamentowym byłby on zbędny (por. [Platt97]) .
Implementowani serwera obiektowego w postaci biblioteki DLL ma sens tylko w przypadku, gdy faktycznie stanowi rodzaj rozszerzenia środowiska czasu wykonania. W tym przypadku jest on pewną biblioteką dostarczającą usług, również w postaci tworzenia obiektów. Jednak obiekty te nie powinny być współdzielone (shared) przez procesy czy wątki. Z doświadczeń autora wynika, że dążenie do nieuzasadnionej optymalizacji z wykorzystaniem modelu apartamentowego może przynosić skutek odwrotny do zamierzonego.
Co się tyczy mechanizmu synchronizacji w DCOM, to na wstępie należy zauważyć, że niezależnie od tego czy asynchroniczność jest implementowana na poziomie aplikacyjnym czy systemowy to zawsze musi być utworzony wątek roboczy. Może to mieć miejsce zarówno lokalnie jak i na innym węźle sieci. Serwer tworzący egzemplarze klas, które są w stanie obsługiwać wywołanie asynchroniczne zgodnie ze specyfikacją DCOM, musi samodzielnie implementować systemowy obiekt (IAsyncCall), zawierający jeden lub więcej wątków wątek W efekcie, rozwiązanie systemowe niczym nie różni się od aplikacyjnego, z tą różnicą, że trzeba ponieść niebagatelny nakład na zakodowanie zgodne ze specyfikacją.
Mechanizm wywołania asynchronicznego w protokole DCOM został zrealizowany na poziomie definicji interfejsu obiektu. Język opisu definicji (IDL) i przetwarzający ten język kompilator (MIDL) zostały rozszerzone o elementy umożliwiające deklarowanie interfejsów w wersjach asynchronicznych. W języku IDL pojawił się nowy atrybut instruujący kompilator o konieczności wygenerowania procedur obsługujących wywołanie asynchroniczne DCOM .
Interfejs oznaczony atrybutem asynchroniczności może być wywołany w obydwu trybach: synchronicznym i asynchronicznym. Obsługę obu typów wywołań realizują dwie wersje zestawów rdzenia (stub) i zastępcy (proxy). Wersje asynchroniczna i synchroniczna posiadają oddzielne identyfikatory interfejsów, przy czym dla danego obiektu DCOM można posługiwać się nimi niezależnie. Oznacza to, że dla jednego obiektu możliwe są wywołania obydwu typów, z tym że należy każdorazowo posługiwać się odpowiednim interfejsem*.
Sam obiekt, po stronie serwera może być obsługiwany przez konwencjonalny serwer DCOM. W tym przypadku całe zadanie asynchronicznego przetwarzania realizuje strona klienta. Serwer może być zaimplementowany na platformie NT 4.0, która nie obsługuje wywołania asynchronicznego.
* Ponieważ, jak już wspomniano w rozdz. 2.1, obiekty DCOM mogą implementować wiele interfejsów
47

Można też zaimplementować bardziej wyrafinowaną obsługę, która daje możliwość kontroli stanu zainicjowanego procesu przetwarzania asynchronicznego oraz (w pewnym zakresie) ingerencji w proces wywołania. Odbywa się to poprzez własną implementację pewnych standardowych interfejsów DCOM (konkretnie przedstawionych dalej ICallFactory oraz ISynchronize).
Jako przykład w dalszych rozważaniach posłuży funkcja JobRechnungErfassen zaczerpnięta z aplikacji wielowarstwowej bazy danych* (rys. 2.4). Realizuje ona proces wystawiania rachunku dla pewnego zlecenia. Z punktu widzenia analizy przetwarzania asynchronicznego istotne jest, że funkcja ta realizuje złożone reguły przetwarzania, korzysta intensywnie z dużych ilości danych przechowywanych w bazie. Jest ona dlatego idealnym kandydatem do realizacji w postaci asynchronicznego wywołania.
[object,uuid(4B4FF84F-7D30-51E8-C94A-A6E70EAAA193),async_uuid(DB207EA4-96F6-5377-A55B-8D56939DADC8),helpstring("RechnungInterface"),pointer_default(unique)
]interface IRechnung : IUnknown{
[helpstring("Asynchronous Call")] HRESULT JobRechnungErfassen ([in] long JobID, [out] unsigned double*GesamtBetrag);
};
3.5. Deklaracja asynchronicznej klasy (IDL)
Funkcja ta posiada dwa parametry: wejściowy JobId oraz wyjściowy GesamtBetrag. W wersji asynchronicznej interfejsu każdej funkcji odpowiadają dwie funkcje implementujące ją: Begin_xxx oraz Finish_xxx, odpowiadające za inicjalizację przetwarzania oraz zakończenie. Funkcja inicjująca zawiera parametry wejściowe, natomiast funkcja odpowiedzialna za zakończenie - parametry wyjściowe. Parametry mieszane (inout) obecne są w obydwu funkcjach. Funkcja Finish_xxx wywoływana jest w trybie synchronicznym. Powrót z wywołania tejże odbywa się po zakończeniu przetwarzania. Ten najprostszy scenariusz przedstawiony jest na rys. 3.5. Należy zauważyć, że jest to jedyna możliwość w przypadku gdy serwer obiektowy jest zaimplementowany w sposób konwencjonalny (nie uczestniczy w przetwarzaniu asynchronicznym).
Interfejs wywołania asynchronicznego (w prezentowanym przykładzie IAsynchRechnung) uzyskiwany jest każdorazowo za pośrednictwem obiektu ICallFactory. Dzięki temu możliwe jest równoległe wykonanie wielu wywołań asynchronicznych, odnoszących się do tego samego obiektu. Dla każdego wywołania
* Ta agentowa aplikacja zostanie wspomnina jeszcze w rozdz. 7 zawierającym opisy przypadków zastosowań RAW
48

należy utworzyć każdorazowo odpowiadający mu obiekt asynchroniczny, gdyż jego ponowne wykorzystanie przed zakończeniem aktywnego wywołania jest niedozwolone. Obiekt wywołania identyfikuje jedną parę wywołań: inicjującą i finalizującą. Protokół DCOM wymaga również, by każdemu wywołaniu metody Begin_xxx towarzyszyło wywołanie odpowiadającej mu metody Finish_xxx. Jest to związane z przydziałem zasobów (konkretnie buforów transmisyjnych) i koniecznością ich zwolnienia.
Metoda Finish_xxx nie jest jedynym mechanizmem synchronizacji udostępnianym przez DCOM. Dodatkowe możliwości oferowane są przez funkcje interfejsu ISynchronize. Dają one możliwość monitorowania statusu wywołania bez konieczności wywołania synchronicznego. Najprostszą metodą wykorzystania ISynchronize jest funkcja ISynchronize::Wait z limitem czasowym. Funkcja ta blokuje się na czas określony limitem lub wraca natychmiast informując czy przetwarzanie zostało zakończone, dając w ten sposób możliwość realizacji pollingu czyli aktywnego czekania (busy waiting). Rozwiązanie oparte na aktywnym czekaniu tylko w ograniczonej liczbie przypadków można uznać za satysfakcjonujące.
Możliwa jest też synchronizacja za pośrednictwem metody Signal interfejsu ISynchronize. W przeciwieństwie do metody Wait konieczna jest w tym przypadku własna implementacja interfejsu. Powinna ona zawierać metodę Signal, której wywołanie poinformuje proces o zakończeniu przetwarzania. Ponieważ ICallFactory musi realizować również pewne „statutowe” zadania, rozsądnym rozwiązaniem może by zagregowanie standardowego (udostępnianego przez DCOM) obiektu wywołania we własnej implementacji, która z kolei udostępni własną wersję ISynchronize. Biorąc pod uwagę, że mechanizm typu callback należy do typowego repertuaru metod synchronizacji, metoda oferowana przez DCOM nie jest, z uwagi na pracochłonną implementację, optymalna .
Ingerencja w proces wywołania asynchronicznego odbywa się za pomocą metod interfejsu ICancelMethodCalls udostępnianego z kolei przez obiekt wywołania. Jedyną możliwą ingerencją jest przerwanie przetwarzania. Jest to możliwe tylko dla obiektów, które implementują własny interfejs ICallFactory. Metoda IcancelMethodCalls :: Cancel zawiera jeden parametr określający czas oczekiwania na zakończenie przetwarzania przed podjęciem próby jego przerwania. Przerwanie przetwarzania nie zwalnia procesu wywołującego z obowiązku wywołania metody Finish_xxx. Wartości parametrów typu out zawartych w tym wywołaniu zależą od implementacji użytkownika. Implementacja może za pomocą pollingu badać stan klienta i w razie żądania przerwania podjąć stosowne kroki i przekazać np. częściowe wyniki.
Podstawową wadą rozwiązań przyjętych w obsłudze asynchronicznego wywołania w DCOM jest, oprócz wspomnianego już stopnia komplikacji realizowania pewnych elementów, brak możliwości asynchronicznego wywołanie metod interfejsów typu
49

IDispatch. Przekłada się to na niedostępność tegoż wywołania w obrębie automatyzacji OLE. Interfejs IDispatch oraz towarzyszące mu biblioteki typów odgrywają kluczową rolę w realizacji postulatów inżynierii oprogramowania (patrz rozdz. 5) (architektury kooperacyjne, komponentowe czy tzw. mechanizm refleksji). Ich brak praktycznie eliminuje standardowy mechanizm DCOM z zastosowań w obszarze programowania aplikacyjnego systemów informatycznych. Mechanizmy synchronizacji, aczkolwiek realizują zasadnicze wymagania (możliwe zarówno aktywne czekanie jak i sygnalizacja), to nie są one wystarczająco elastyczne by zapewnić bardziej wyrafinowane mechanizmy współpracy między wykonywanymi równolegle procesami. Dotyczy to np. mechanizmu uogólnionej modalności (patrz rozdz. 3.4). Tak więc w dalszym ciągu aktualne są metody symulacji wywołania asynchronicznego, działające niezależnie od nowych rozszerzeń protokołu DCOM.
Mechanizm pełnej realizacji wymogów komunikacji asynchronicznej powinien charakteryzować się następującymi cechami [Prosise1]:
- Powinien umożliwiać klientowi przekazanie do serwera obiektu synchronizującego, który następnie zostanie użyty do zawiadomienia tegoż klienta o zakończeniu przetwarzania. Ewentualnie będzie wykorzystywany do sukcesywnego przekazywania statusu realizowanej operacji.
- Uruchomiony przez wywołanie inicjujące wątek roboczy powinien być w stanie zagregować przekazany obiekt synchronizujący.
- Wywołanie inicjujące kończy swoje działanie w momencie uruchomienia wątku roboczego. Po czym sterowanie powraca do klienta.
- Wątek roboczy w momencie zakończenia przetwarzania, wywołuje metody zagregowanego obiektu w celu zawiadomienia klienta o wyniku i statusie zakończonej operacji.
Agregacja (przechowywanie) obiektu DCOM odbywa się za pośrednictwem mechanizmu określanego jako marshaling. Jest on dokładniej opisany w rozdz. 4.
Również lansowany przez OMG protokół CORBA zawiera w sobie elementy obsługujące przetwarzanie asynchroniczne. Dostępne w protokole CORBA funkcje oneway, mogące uchodzić za pewną wersję wywołania asynchronicznego, nie są semantycznie równoważne funkcjom protokołu DCOM. Powrót z wywołania funkcji asynchronicznej w DCOM (czy w proponowanej w pracy symulacji takiego wywołania) gwarantuje bowiem, że parametry wywołania zostały przekazane i przetwarzanie zostało pomyślnie zainicjowane. Różnica pomiędzy semantykami jest podobna do tej, która występuje pomiędzy komunikacją za pomocą asynchronicznego gniazda (socket) a wysłaniem ramki UDP. Wyczerpujące case study, które demonstruje możliwości protokołu CORBA w tym zakresie zawiera [Hubert].
50

3.4. Uogólniona modalność
Terminem modalność (ang. mode) określany jest tryb interfejsu użytkownika w którym dostęp do pewnych funkcji jest ograniczony ze względu na reguły przetwarzania w systemie informacyjnym[IBM]. Użytkownik znajduje się w trybie modalnym, jeżeli musi najpierw odwołać wykonywaną bieżąco operację lub ją zakończyć, zanim będzie on mógł kontynuować dalszą pracę z systemem. Modalność wymusza więc dostosowanie się użytkownika, jego sposobu pracy z aplikacją składową SI do wewnętrznej logiki tejże aplikacji. Tak więc tryb modalny może być uważany za sposób synchronizacji interfejsu użytkownika np. w oczekiwaniu na wykonanie zapytania skierowanego do serwera SQLowej bazy danych.
Tryb modalny jest określany jako „zło konieczne” w ramach interfejsu systemu, gdyż zaburza intuicję użytkownika dotyczącą modelu konceptualnego systemu. Czas wykonania funkcji stanowi (na ogół) jego własność niefunkcjonalną (operacyjną). Co więcej ogranicza dostępność do funkcji systemu zmniejszając jego interaktywność. Zbiór wytycznych dla projektowania graficznego interfejsu aplikacji [IBM], zawiera wskazówkę dotyczącą unikania za wszelką cenę trybów modalnych i stosowania ich tylko tam gdzie jest to niezbędne.
Chart ID : ModalChart Name : ModalChart Type : UML Sequence Diagram
Object1 : Consumer Object2 : Provider
SynchronousCall( )
return( )
Kon
we n
cjo n
alna
mod
aln o
ść
3.6. Synchroniczne wywołanie metody obiektu klasy Provider
Najczęstszą postacią trybu modalnego w interfejsie użytkownika są formularze modalne, których zamknięcie umożliwia dalszą pracę z systemem. Innymi postaciami wymienionymi w [IBM] są:
51

- tryb załadowany (spring-loaded mode) – w którym użytkownik w sposób ciągły wykonuje pewną operację przez co znajduje się w trybie modalnym. Przykładem modalności tego typu mogą być różne tryby pracy kursora myszki podczas przeciągania,
- tryb narzędziowy (tool driven mode) – obecny jest on przede wszystkim w programach graficznych. Tryb pracy kursora myszki zmienia się wraz z wyborem konkretnego narzędzia rysującego.
Najistotniejszą cechą trybu modalnego jest oczekiwanie na zakończenie wykonywanej operacji. Jak już wspomniano, dla systemów informatycznych operacją, której zakończenia oczekuje się jest najczęściej transakcja korzystająca z zasobów baz danych lub inna operacja wymagająca dostępu do zasobów sieciowych.
Rysunki 3.6 i 3.7 pokazują zależność pomiędzy wywołaniem asynchronicznym oraz modalnością interfejsu użytkownika. Jeżeli transakcja, lub inne żądanie skierowane do komponentu w ramach architektury wielowarstwowej zostanie wywołane w sposób synchroniczny, to w czasie oczekiwania na zakończenie operacji interfejs użytkownika będzie znajdował się w trybie modalnym. Co więcej, interfejs nie będzie w stanie prezentować żadnej informacji dotyczącej bieżącego statusu wykonywanej operacji. Zakończenie wywołania jest jedynym sposobem na udostępnienie aplikacji klienta statusu zakończonej operacji oraz zsynchronizowania procesów tejże aplikacji oraz komponentu lub serwera.
Chart ID : GModalChart Name : GModalChart Type : UML Sequence Diagram
Object1 : Consumer Object2 : Provider
AsynchronousCall( )
Synchronize( )
Synchronize( )
Synchronize( )
Uog
óln i
ona
mod
a lno
ś ć
52

3.7. Asynchroniczne wywołanie metody obiektu klasy Provider
Inaczej rzecz się ma w przypadku wywołania asynchronicznego. Aplikacja klienta ma większą liczbę możliwości zsynchronizowania procesów. Może się to odbyć za pomocą standardowych mechanizmów udostępnianych przez DCOM (patrz rozdz. 3.2). Możliwa jest też synchronizacja poprzez zagregowane, przekazanego przez referencję obiektu zwrotnego, w wątku roboczym komponentu symulującego wywołanie asynchroniczne, tak jak to pokazano w mechanizmie symulacji.
W ten sposób uzyskuje się możliwość sygnalizowania aplikacji statusu przetwarzania po stronie serwera. Co więcej, sygnalizacja może być obsługiwana po stronie klienta. Reguły przetwarzania udostępniają (uaktywniają) pewne niedostępne elementy interfejsu – realizując w ten sposób mechanizm uogólnionej modalności.
Modalność konwencjonalna zakłada istnienie dwóch stanów elementu interfejsu użytkownika – modalny oraz niemodalny (modeless). Wyłączenie trybu modalnego odbywa się na skutek zakończenia lub odwołania operacji.
W przypadku przetwarzania asynchronicznego możliwe jest zdefiniowanie dowolnej ilości stanów interfejsu. Ich ilość może być określona poprzez reguły przetwarzania charakterystyczne dla aktualnego systemu informatycznego. Stany interfejsu mogą definiować automat skończenie stanowy, w którym źródłem symboli wejściowych będą wywołania funkcji obiektu synchronizującego.
Chart ID : JobPerfectChart Name : JobPerfectChart Type : UML Sequence Diagram
Object1 : Spreadsheet Object2 : MISComponent Object3 : SQLServer
SQLExecute( )
SQLFetch( )
Initialize( )
SQLFetch( )
UpdateKostenstelle( )
SQLExecute( )
SQLFetch( )UpdateKostenstelle( )
3.8. Dynamiczne uaktualnianie interfejsu użytkownika podczas przetwarzania zapytania skierowanego do bazy danych
53

Przedstawiony sposób synchronizacji oparty na mechanizmie symulacji wywołania asynchronicznego jest modalnością uogólnioną. Implementacja takiej modalności dla bazodanowych systemów informatycznych jest w praktyce trudna, jeśli oprzeć ją o konwencjonalne architektury ( w tym architekturę klient – serwer) oparte na modelu SPI (system provider interface – patrz rozdz. 5.2), ponieważ w tym przypadku możliwości implementacji określone są poprzez funkcje dostępne w środowisku operacyjnym. Rozszerzony model wielowarstwowy zacierający granicę pomiędzy warstwą systemową i aplikacyjną umożliwia stworzenie źródła danych realizującego pożądane sterowanie stanami interfejsu użytkownika.
Pokazany zostanie teraz przykład implementacji uogólnionej modalności w systemie informatycznym służącym do monitorowania wyników finansowych organizacji. W ramach prezentowanego przykładu wyznaczane jest wiele wskaźników finansowych takich jak dochodowość, rentowność, stopień wykorzystania zasobów ludzkich i kapitałowych. Wyznaczane są zarówno dane syntetyczne (zbiorcze) oraz analityczne, z rozbiciem na poszczególne oddziały, jednostki organizacyjne oraz rozrachunkowe (niem. Kostenstellen). Użytkownik ma możliwość definiowania wirtualnych składowych organizacji stanowiących podstawę późniejszej analizy.
Przedstawiona operacja intensywnie korzysta z obszernych ilości danych zawartych w bazie. W konwencjonalnej wersji interfejs użytkownika był blokowany na czas wykonywania analizy. Dzięki zastosowaniu uogólnionej modalności można zwiększyć w znacznym stopniu komunikatywność systemu (ang. responsivness) i zwiększyć przez to jego walory użytkowe.
3.5. Autonomiczność agentów
Przedstawione w rozdz. 2.2 architektury agentowe pojawiły się w ramach badań prowadzonych w obrębie Rozproszonej Sztucznej Inteligencji (DAI distributed artificial intelligence), Teorii Sterowania (Control Theory) oraz Sztucznej Inteligencji (Artificial Intelligence). Miały być odpowiedzią na rosnące potrzeby związane z implementacją systemów informatycznych dla kooperujących organizacji i przedsiębiorstw (virtual enterprise), dla potrzeb kontroli ruchu powietrznego czy dla zarządzania zaopatrzeniem w korporacjach o zasięgu globalnym [Muel].
Agent może być rozumiany jako sprzętowa lub programowa autonomiczna jednostka realizująca zadania, funkcjonująca w złożonym, dynamicznie zmieniającym się środowisku [Muel]. Autonomia oznacza w tym przypadku umiejętność samodzielnego podejmowania decyzji, opartej na wewnętrznej reprezentacji świata. Autonomiczność zakłada również brak stałego połączenia ze zleceniodawcą, który jedynie inicjuje proces przetwarzania – przekazując agentowi zadanie wraz z danymi lub wytycznymi którymi dysponuje i które uznaje za niezbędne do jego realizacji.
54

Istotne jest rozróżnienie pomiędzy operacyjnym i funkcjonalnym aspektem autonomiczności agenta. W pracy [Nierstrasz] pojawiają się pojęcia funkcjonalnych i niefunkcjonalnych własności komponentów w systemie informatycznym. Jako własności funkcjonalne określone są te, odpowiedzialne za realizację reguł przetwarzania. Własności niefunkcjonalne (nazywane tutaj operacyjnymi) dotyczą warunków technicznych, zdeterminowanych przez środowisko czasu wykonania. We wzmiankowanej pracy pojawia się stwierdzenie o konieczności technologicznego wsparcia różnych form kooperacji – rozumianej jako rozwój możliwości środowiska czasu wykonania.
Autonomia agenta może być rozumiana dwojako – w aspekcie funkcjonalnym oraz operacyjnym. Funkcjonalna autonomiczność oznacza, że agent jest w stanie samodzielnie analizować zmieniający się stan jego otoczenia. Jego algorytmy działania, reprezentacja stanu wewnętrznego oraz interfejs dostępu do otoczenia są wystarczające do rozwiązania postawionego zadania.
W kategoriach technicznych czy operacyjnych autonomiczność sprowadza się do asynchroniczności agenta. Wywołanie asynchroniczne, wraz z przekazaniem danych i zainicjowaniem przetwarzania jest realizacją autonomiczności na poziomie środowiska czasu wykonania.
W ten sam sposób jak za autonomiczność w warstwie logicznej odpowiedzialne są odpowiednie algorytmy, tak w warstwie fizycznej, czy też implementacyjnej odpowiednie funkcje protokołu komunikacyjnego zapewniają, z jednej strony zainicjowanie asynchronicznego przetwarzania. Z drugiej strony, umożliwiają ponowną synchronizację systemu, która w kontekście implementacyjnym sprowadza się do wykorzystania sieciowych obiektów synchronizacyjnych.
Z punktu widzenia logicznych własności agenta zakończenie przetwarzania asynchronicznego czy też przekazanie informacji o bieżącym jego statusie jest określane jako współdzielenie wyników (result sharing) [Bernd] i ma szczególne znaczenie w środowiskach wieloagentowych (MIS Multiagent Information Systems).
Przedstawiona w poprzednim rozdziale agregacja obiektów protokołu przekazywanych przez referencję stwarza możliwość implementacji dowolnie złożonych reguł przetwarzania. W istocie, wyodrębnienie aspektu operacyjnego inicjacji przetwarzania (asynchroniczności) oraz późniejszej synchronizacji (poprzez wywołania metod zagregowanych obiektów i ewentualne zasygnalizowanie standardowych semaforów dostępnych w systemie), pozwala na użycie dostępnych w ramach języka implementacji typów danych do reprezentowania i współdzielenia wyniku.
55

Przedstawione w literaturze [Bernd, Clark] rozwiązania oparte są na eksperymentalnych środowiskach implementacyjnych, służących jedynie do modelowania i prac badawczych. Jako takie, mają ograniczone znaczenie praktyczne. Autorzy wspomnianych publikacji nie podają ani jednego przypadku pomyślnej implementacji wdrożonego systemu informatycznego. Należy zauważyć, że dzięki rozszerzeniu istniejących i sprawdzonych protokołów obiektowych o cechy pozwalające na realizację operacyjnych cech agentów uzyskuję się środowisko implementacyjne pozwalające na wykorzystanie języków takich jak Delphi, Kylix czy VC++.
Asynchroniczna funkcja wyznaczania parametrów ekonomicznych (rys. 3.8) jest również przykładem zastosowania postulatów architektur agentowych w programowaniu aplikacyjnym. Wywołanie asynchroniczne oraz obiekty zagregowane sterują stanem procesu wywołującego. Rolę interfejsu do reprezentacji świata zewnętrznego pełni w tym przypadku ODBC, odpowiedzialne za dostęp do bazy danych.
Tak więc asynchroniczne wywołanie metody jest częściową realizacją operacyjnych (niefunkcjonalnych) własności agenta. Drugą własnością tego typu jest mobilność. W przeciwieństwie do autonomiczności jest ona uważana za własność mającą wyłącznie operacyjny charakter [Muel] – pogląd ten nie jest jednak do końca uzasadniony. Omówienie tego zagadnienia znajduje się w rozdz. 4. Rozszerzenie protokołu obiektowego o asynchroniczność i mobilność umożliwia pełną implementację systemów agentowych za pomocą konwencjonalnych języków programowania – bez konieczności uciekania się do obszernych infrastruktur.
56

4. Migracja obiektów
Istotą prezentowanej metody przekazywania parametrów obiektowych przez wartość jest rozdzielenie implementacji obiektu (komponentu) od reprezentacji jego stanu – bez konieczności odwoływania się do specyficznych własności środowiska implementacji (Java itp.). Podobnie jak w przypadku procesu, rozumianego w kontekście systemu operacyjnego, przez połączenie kodu instrukcji, stosu oraz pamięci statycznej przechowującej wartości zmiennych globalnych – na egzemplarz komponentu składają się kod wykonywalny, przechowywany w pliku implementacji oraz jego bieżący stan wyrażany m.in. przez wartości pól składowych (pola publiczne i prywatne) czy przydzielone zasoby.
Należy zwrócić uwagę, że nawet w konwencjonalnych obiektowych językach programowania przekazywanie parametrów obiektowych przez wartość (np. egzemplarzy klas w ramach C++) nie jest sprawą trywialną. Tryb przekazywania przez wartość wymaga bowiem zadeklarowania konstruktora kopiującego por. [Stroustrup] odpowiedzialnego za utworzenie egzemplarza obiektu na stosie*. Wynika stąd, że semantyka przekazania przez wartość może zawierać w sobie pewne specyficzne dla danego typu operacje – obejmujące np. przydział pamięci czy utworzenie wątków roboczych. Za najbardziej zaawansowane środowisko programistyczne, realizujące postulaty programowania obiektowego uchodzi język ADA por. [Kempe].
W przypadku komponentów programowych w środowisku sieciowym pojawia się dodatkowo kwestia przenośności między platformami. Obiekt (komponent) może być przekazany zdalnie pomiędzy dwoma procesami uruchomionymi na różnych węzłach sieci – niekoniecznie kompatybilnych na poziomie binarnym. Jedną z możliwości jest zastosowanie implementacji niezależnej od platformy (kod bajtowy maszyny wirtualnej języka JAVA). Możliwe jest też, proponowane tutaj, stworzenie oddzielnej implementacji komponentu dla każdej platformy.
Przekazanie komponentu przez wartość może odgrywać istotną rolę w procesie realizacji mobilności agentów. Agent zrealizowany jako komponent (w kontekście określonego protokołu obiektowego) może zostać przeniesiony do innego węzła sieci poprzez przekazanie go jako parametru. W wyniku migracji obiektu na urządzeniu docelowym zostaje utworzona kopia agenta. Proces tworzenia kopii może obejmować wszystkie operacje związane z poprawnym funkcjonowaniem agenta takie jak wspomniane już: przydzielenie wątków, zasobów, odtworzenie wartości zmiennych oraz uwierzytelnienie.
* Proste przypadki - przepisanie zawartości pamięci bądź wywołanie konstruktorów dla składowych- mogą być osbłużone przez konstruktor generowany automatycznie.
57

Innym zastosowaniem przekazywania komponentów przez wartość może być realizacja postulatów technologii komponentowych. Architektura Komponentowa (componentware) - przedstawiona w rozdz. 2.2 nowa technologia, która pojawiła się w ramach inżynierii oprogramowania, opiera się na wykorzystaniu składowych systemu w modelu tzw. czarnej skrzynki (black box model) [Nierstrasz]. Istotą tego modelu jest synteza oprogramowania aplikacyjnego ze składników dostępnych jedynie w postaci binarnej (odwrotnie w modelu white box – wymagana jest dostępność źródeł). Przekazywanie kopii obiektów przez wartość może odgrywać rolę z punktu widzenia postulowanego w ramach opisywanego modelu mechanizmu kompozycji, polegającego na konfigurowaniu komponentów ogólnego przeznaczenia za pomocą zagregowanych obiektów, realizujących specyficzne reguły przetwarzania, czy też funkcje operacyjne. Kompozycja obejmująca przekazanie typu ukonkretniającego pewne abstrakcyjne funkcje zawarte w komponencie bibliotecznym jest zbliżona do wzorców (template) znanych z C++, czy typów rodzajowych (generic) z języka ADA . Należy ciągle mieć na uwadze, że celem kompozycji jest udostępnianie wspomnianych mechanizmów bez dostępu do kodu źródłowego. Co więcej z zachowaniem przeźroczystości miejsca (location transparency)
4.1. Marshaling – reprezentacja strumieniowa
Wszystkie parametry wywołań metod w protokołach obiektowych mogą być przekazywane przez wartość*. Jedynym, ale znaczącym wyjątkiem są parametry będące obiektami. Dla parametrów typu obiektowego przewidziano specjalny mechanizm - w obszarze adresowym metody wywoływanej tworzony jest tzw. zastępca (proxy), którego zadaniem jest przekazywanie wszelkich odwołań do metod i składowych parametru do obiektu macierzystego.
Uzasadnienie takiego stanu rzeczy jest proste. Protokół obiektowy ma działać w sposób możliwie przejrzysty. Wynika stąd, że wywołanie metody obiektu utworzonego na zdalnym węźle sieci powinno odbywać się w ten sam sposób, jak dzieje się to w obrębie jednego węzła lub nawet jednego procesu. Typy podstawowe wchodzące w skład definicji protokołu obiektowego mogą być przekazywane przez wartość, gdyż cała ich semantyka jest zawarta w obrębie protokołu. Inaczej jest w przypadku typu obiektowego – tutaj znana jest tylko jego deklaracja i to tylko w przypadku obiektów implementujących interfejsy standardowe. Dlatego też, przekazywanie obiektu przez wartość wymaga, by jego implementacja była dostępna na każdym węźle, do którego obiekt ten byłby przekazywany. Z tego też powodu twórcy protokołów obiektowych nie zaimplementowali mechanizmów umożliwiających, czy choćby ułatwiających utworzenie kopii obiektu w obszarze adresowym metody wywoływanej. Wspomniana przejrzystość może być rozumiana jako dążenie do uniezależnienia mechanizmu
* Właściwie tylko przez wartość, semantyka jest zbliżona do języka ADA (in, out, inout)
58

przekazywania parametrów obiektowych od konkretnych typów. Jak wskazują doświadczenia z obszaru obiektowych języków programowania, gdzie obiekt mający być przekazywany przez wartość musi implementować konstruktor kopiujący, nie jest możliwe zrealizowanie przekazania obiektu bez ingerencji w jego semantykę.
Okazuje się jednak, że w przypadku komponentów, rozumianych tutaj jako obiekty implementujące pewne określone przez standard interfejsy, możliwe jest wykorzystanie tychże interfejsów do celów przekazywania przez wartość. Jeżeli komponent, implementuje interfejs zapewniający obsługę metod trwałego zapisu (persistence), to istnieje możliwość reprezentacji i odtworzenia stanu obiektu w sposób zbliżony do sposobu działania konstruktora kopiującego.
Mechanizmy przekazywania przez wartość są pożądane z dwóch powodów: po pierwsze komunikacja przez proxy odbywa się za pośrednictwem kosztownego połączenie sieciowego, w którym dane przechodzą przez wiele warstw protokołu; po drugie reguły przetwarzania konkretnej aplikacji zezwalają albo czasem wręcz wymagają posłużenia się kopią konkretnego obiektu w obszarze adresowym metody wywoływanej. O przyczynach natury „aplikacyjnej” pisano już we wstępie do rozdziału.
Dalej zostanie zaprezentowany mechanizm symulujący przekazywanie parametru obiektowego w trybie MBV. Wykorzystana zostanie pewna elastyczna technika reprezentacji obiektu poprzez strumień sekwencyjny znana jako marshaling por. [Box], [Brock].
Dana typu obiektowego może być rozpatrywana w trzech kategoriach – deklaracji, implementacji oraz stanu. Stan obiektu będzie rozumiany jako wartość wszystkich jego atrybutów (publicznych oraz prywatnych). Marshaling realizuje zadanie polegające na stworzeniu reprezentacji obiektu w postaci sekwencyjnego strumienia, który może być przekazany do innej przestrzeni adresowej. Dane odczytane ze strumienia służą następnie do zbudowania połączenia z obiektem wyjściowym. Należy pamiętać, że strumień jest obiektem wirtualnym. Oznacza to, że jest określony jako interfejs realizujący określony zestaw funkcji (IStream).
Protokół obiektowy realizuje marshaling w standardowej postaci. W jego wyniku powstają obiekty takie jak wspomniany już proxy (w obrębie metody wywoływanej) oraz stub (rdzeń – reprezentujący połączenie z obiektem zastępcą). Zadaniem tej pary jest utrzymywanie połączenia pomiędzy wywołaną metodą a obiektem przekazanym jako parametr.
Specyfikacja protokołu DCOM (za [Brock]) podaje dwa przypadki, w których obiekt powinien implementować własny marshaling. Po pierwsze obiekty znajdujące się w
59

pamięci współdzielonej (shared memory) mogą tworzyć obiekty proxy odwołujące się do tych obszarów. Przykładem takich obiektów mogą być strumienie i przechowalnie – implementujące odpowiednio interfejsy IStream oraz IStorage. Możliwość taka istnieje oczywiście tylko dla wywołań w obrębie jednego urządzenia. Drugą przyczyną uzasadniającą własną implementację może być niezmienność stanu obiektu. Twórcy protokołu DCOM zakładają, że tylko obiekty nie zmieniające po utworzeniu wartości swoich atrybutów mogą być przekazywane przez wartość. Pogląd taki wydaje się być co najmniej kontrowersyjny. Najważniejsza jednak, z punktu widzenia prezentowanych rozważań, jest sama możliwość nałożenia własnej implementacji mechanizmu reprezentacji strumieniowej.
Za przekazywanie obiektu przez referencję „odpowiedzialny” jest właśnie standardowy marshaling protokołu obiektowego. Jak już wspomniano, protokół DCOM przewiduje możliwość implementowanie przez obiekty własnego, specyficznego sposobu reprezentowania go przez strumień i nawiązywania połączenia – innymi słowy własny marshaling. Fakt ten jest punktem wyjścia dla metody określanej jako MBV (Marshaling by Value).
IMarshal = interface(IUnknown) ['{00000003-0000-0000-C000-000000000046}'] function GetUnmarshalClass(const iid: TIID; pv: Pointer; dwDestContext: Longint; pvDestContext: Pointer; mshlflags: Longint; out cid: TCLSID): HResult; stdcall; function GetMarshalSizeMax(const iid: TIID; pv: Pointer; dwDestContext: Longint; pvDestContext: Pointer; mshlflags: Longint; out size: Longint): HResult; stdcall; function MarshalInterface(const stm: IStream; const iid: TIID; pv: Pointer; dwDestContext: Longint; pvDestContext: Pointer; mshlflags: Longint): HResult; stdcall; function UnmarshalInterface(const stm: IStream; const iid: TIID; out pv): HResult; stdcall; function ReleaseMarshalData(const stm: IStream): HResult; stdcall; function DisconnectObject(dwReserved: Longint): HResult; stdcall; end;
4.1. Deklaracja interfejsu IMarshal [Platt]
Znane w literaturze rozwiązanie [Box],[Brown] jest oparte na analizie roli interfejsu IMarshal rys. 4.1 w procesie przekazywania parametrów. Jeśli obiekt ma być przekazany jako parametr wywołania to protokół sprawdza najpierw czy dysponuje on własną implementacją marshaling’u. Jeżeli tak, to wywołanie funkcji QueryInterface zwraca wartość wskaźnika to interfejsu IMarshal. W przeciwnym razie wywoływana jest (w dalszym ciągu przez protokół) funkcja CoCreateStandardMarshaler, której zadaniem jest utworzenie wspomnianego interfejsu IMarshal – tym razem systemowego.
60

W tym momencie protokół dysponuje już interfejsem – standardowym lub specyficznym obiektu. Wywoływana jest teraz metoda tego interfejsu IMarshal.Marshallinterface. Jako parametr wywołania zostaje do niej przekazany strumień, do którego obiekt zapisze dane niezbędne do nawiązanie połączenia. Wywołanie metody IMarshal.Marshallinterface poprzedza próba ustalenia wielkości strumienia przez wywołanie IMarshal.GetUnmarshalSizeMax. Ponieważ większość implementacji strumienia nie wymaga określenia z góry wielkości zapisywanych danych, metoda ta na ogół nie jest implementowana.
Dysponując strumieniem z zapisanymi danymi, protokół tworzy obiekt zastępczy (proxy) w przestrzeni adresowej metody wywoływanej. Następnie, za pomocą funkcji QueryInterface uzyskuje wskaźnik do interfejsu IMarshal tego obiektu, następnie wywołuje metodę IMarshal.Unmarshallinterface przekazując jej strumień z danymi. Wynikiem tego wywołania powinno być nawiązanie połączenia z obiektem.
Powyższy opis zawiera przesłanki metody określanej jako MBV. Odpowiednia implementacja pary funkcji interfejsu IMarshal - IMarshal.Marshallinterface oraz IMarshal.Unmarshallinterface powinna zamiast zestawu proxy-stub utworzyć kopię obiektu. Występują tu jednak dwie trudności: po pierwsze mają być przekazywane przez wartość obiekty klas, których kody źródłowe są niedostępne - a więc bez możliwości modyfikowania. (programowanie odbywa się w trybie black-box); po drugie konieczny jest dostęp do sposobu zapisu stanu obiektu w strumieniu, w dalszym ciągu bez dostępu do implementacji.
Drugi problem jest prostszy do rozwiązania. Każdy obiekt ActiveX powinien implementować interfejs IPersistStream, służący do zapisu stanu obiektu. Wynika stąd pierwsze ograniczenie opisywanej metody: tylko obiekty które potrafią zapisać stan w strumieniu można przekazywać przez wartość. Uwaga ta w dalszym ciągu dotyczy tylko obiektów, do których implementacji nie ma dostępu.
Dodanie własnej realizacji funkcji IMarshal.Marshallinterface oraz IMarshal. Unmarshallinterface do istniejącej implementacji, dostępnej tylko w postaci binarnej jest bardziej skomplikowanym zadaniem. Można wymienić cztery możliwości:
- osadzenie interfejsu IMarshal w obiekcie,- zagregowanie obiektu w klasie implementującej własny interfejs IMarshal,- wykorzystanie mechanizmu tzw. posłusznego przekaźnika* (Blind Delegator)
[Box], [Brown],- osadzenie obiektu w interfejsie IMarshal .
Najprostsza z wymienionych propozycji (osadzenie interfejsu IMarshal) – wymaga szczątkowej współpracy z obiektem. Dlatego nie będzie ona dalej rozpatrywana. * Metoda służąca do symulacji dziedziczenia opisana w rozdz. 4.2 , wykorzystana w stworzonej na Uniwersytecie Lancaster architekturze OpenDCOM/OpenORB [Coulson, Blair] p. rozdz. 2.2.
61

Agregowanie obiektu w obiekcie innej klasy ma te wady, że: po pierwsze musi być dokonane już w momencie tworzenia obiektu; po drugie musi być obsługiwane przez sam obiekt. Okazuje się, że nie zawsze jest to możliwe. Obiekty zaimplementowane w Visual Basic nie mogą być agregowane. W związku z tym jako potencjalni kandydaci zostają tylko Blind Delegator oraz osadzanie obiektu w interfejsie.
4.2. Blind Delegator (BD)–posłuszny przekaźnik
Jeżeli założyć, że jednym z podstawowych zadań protokołu obiektowego jest wykorzystanie binarnych modułów implementujących komponenty, to idea oddzielenia implementacji od interfejsu okazuje się być wystarczająca. Aplikacje korzystające z komponentów muszą jedynie znać (deklarować) odpowiednie interfejsy. Takie rozwiązanie, aczkolwiek eleganckie, ma tę wadę, że nie umożliwia rozszerzania komponentu o nowe interfejsy oraz ew. specjalizowania czy modyfikacji już istniejących. Innymi słowy na poziomie komponentu binarnego konieczny byłby mechanizm przypominający dziedziczenie*. Opisywany problem nie ogranicza się do kwestii dodania własnej implementacji interfejsu IMarshal. Równie istotne znaczenie mają funkcje kontroli i nadzoru nad obiektem i dostępem do niego. Ogólnie rzecz biorąc, potrzebny jest mechanizm pozwalający modyfikować funkcjonalność komponentów, które są dostępne wyłącznie w postaci binarnej (Model black-box [Nierstrasz]). Dlatego też, z pewnym przybliżeniem można przyjąć, że BD służy również do realizacji funkcji inżynierii odwrotnej.
Mechanizm BD umożliwia przechwytywanie wywołań metod obiektu, pozwalając w ten sposób rozszerzać realizowane przez ten obiekt funkcje. Jest to mechanizm bardziej elastyczny od tych, które są oferowane przez agregację obiektu. Ta ostatnia pozwala jedynie by interfejsy obiektu zagregowanego były widziane przez otoczenie jako interfejsy obiektu agregującego. Tak więc, przechwytywanie odbywa się na poziomie interfejsu a nie metody. Inaczej można to opisać w następujący sposób: jedyną metodą w pełni kontrolowaną przez obiekt agregujący jest IUnknown.QueryInterface. Jednakże dla celów rozszerzenia implementacji IMarshal byłoby to wystarczające, pod warunkiem, że wszystkie obiekty umożliwiają agregację.
Rozszerzona definicja DCOM wprowadza nowy typ obiektu zastępczego tzw. smart-proxy. Realizuje on pewien specjalny sposób komunikacji pomiędzy obiektami. Obiekt, który ma utworzyć smart-proxy powinien implementować interfejs IStdMarshallinfo. Jego zadaniem jest dostarczenie protokołowi identyfikatora klasy (CLSID), która jest z kolei odpowiedzialna za utworzenie obiektu zastępczego. Nic nie stoi na przeszkodzie, by taki specjalizowany obiekt zawierał w sobie standardowego zastępcę. Rozwiązanie
* Swego rodzaju atrapą dziedziczenia (również wielodziedziczenia) jest tzw. agregacja [Brock] – mechanizm ten jest dalej powoływany.
62

to można określić jako pośrednie pomiędzy standardową funkcją systemową a indywidualną implementacją na poziomie obiektu.
Podobny efekt jest dostępny, jeżeli zastosować agregację standardowego marshalingu we własnej implementacji. Jest to bardziej ogólna metoda, stosowana w przypadkach, gdy obiekt potrafi sam obsłużyć tylko szczególne sposoby komunikowania. W pozostałych przypadkach zdaje się on na mechanizmy standardowe. W implementacji metody IMarshal.Marshallinterface jest wtedy wywoływana funkcja CoCreateStandard-Marshaler. Decyzja o tym, kiedy obiekt ma używać standardowych mechanizmów komunikacji a kiedy korzystać z własnych zapada na podstawie parametrów określających tryb jego przekazywania. Technika ta może być stosowana jako swego rodzaju częściowa realizacja mechanizmu BD czy też agregacji.
procedure BDMethod0;asm
push (0*4) jmp delegate end;
procedure BDMethod1;asm
push (1*4) jmp delegate end;
procedure UDMethod0;asm
push (0*4)jmp delegateAndprocess
end;
4.2. Metody wywoływane przez Posłuszny Przekaźnik por.[Box]
Pełna realizacja BD wymaga, by wszystkie odwołania do metod obiektu mogły być przechwytywane – niezależnie od roli, jaką pełnią w procesie przekazywania parametru obiektowego czy reprezentacji strumieniowej. W szczególnym przypadku może to dotyczyć również całych interfejsów – jak IMarshal. Realizacja wymaga więc zastosowania technik zależnych od konkretnych architektur procesorów, gdyż ingerencja w kod wywołania odbywa się na poziomie binarnym. Potrzebne są procedury napisane w języku maszynowym, których zadaniem jest odpowiednie skierowanie wywołań oraz obsługa stosu.
Kod implementujący BD korzysta z binarnej postaci tablicy metod wirtualnych obiektu klasy. BD sam będący obiektem tworzy strukturę danych symulująca VMT (Virtual Method Table). Struktura ta zawiera adresy bloków kodów łączących odpowiedzialnych za przekazywanie wywołań do obiektu osadzonego.
63

W przypadku gdy blok pośredniczący w wywołaniu metody sam wywołuje dodatkowe funkcje premethod i postmethod mówi się o uniwersalnym przekaźniku UD (Universal Delegator) [Brown].
Pierwsze trzy parametry wywołania procedury asemblerowej Pascala przekazywane są przez rejestry (odpowiednio EAX,EDX,ECX). Dlatego rejestry odpowiedzialne za stos (ESP, EBP) nie wymagają obsługi. Procedury odpowiedzialne za delegowanie wywołań metod obiektu mogą być zadeklarowane w ten sam sposób. Istotne jest również, że na stosie zostaje każdorazowo numer wywoływanej metody. Dzięki temu delegator nie ma problemu ze skierowaniem wywołania do wyjściowego obiektu.
procedure Delegator;//realizacja BD kod oparty na przykładzie w [Box]asm mov eax,[esp+8]
mov eax,[eax+4] mov [esp+8],eax
mov eax,[eax]add eax,[esp]mov eax,[eax]add esp,4jmp [eax]
end;
4.3. Posłuszny Przekaźnik
Procedura realizująca przekazywanie wywołania metody do właściwego obiektu pochodzi z [Brown]. Została tam zamieszczona również jej bardziej ogólna wersja pozwalająca na skojarzenie z metodami obiektu funkcji pre- oraz postmethod. – wywoływanych odpowiednio przed i po właściwej metodzie obiektu. Przedstawiona tam technika wymaga jednak krótkiego omówienia. Jest oczywiste, że pre- i postmethod nie mogą być funkcjami odwołującymi się do zmiennych globalnych gdyż nie będą prawidłowo obsługiwać rekurencji. Jako rekurencję rozumiane jest nie tylko wywołanie metody (być może pośrednio) przez nią samą, lecz w ogóle ponowny dostęp do obiektu (re-entrance).
Jeżeli BD lub UD realizują tylko specyficzny marshaling obiektu, to rekurencja oczywiście nie wystąpi*. W ogólnym przypadku należy jednak oczekiwać, że UD i BD będą działać poprawnie w każdej sytuacji – wywołania metod oraz dostęp do składowych będą wielowejściowe. Dwa możliwe rozwiązania to:
- zmienne globalne realizowane są w postaci stosu przechowującego konteksty wywołań (metoda zastosowana w [Brown])
*Rekurencja nie wystąpi nawet w mało realnym przypadku, gdzie obiekt zawiera osadzone egzemplarze swojej klasy, które mają być przekazane przez wartość. Jest tak ponieważ odpowiednie procedury trwałego zapisu zostaną wywołane bezpośrednio a nie poprzez marshaling.
64

- funkcje Delegatora są metodami i mogą przechowywać kontekst jako stan obiektu unikając w ten sposób korzystania ze zmiennych globalnych lub statycznych
Analiza tych dwóch metod prowadzi do wniosku, że są one w pewien sposób równoważne. Pierwsza z nich opiera się na wykorzystaniu jawnego stosu zewnętrznego, podczas gdy druga przechowuje kontekst na stosie systemowym. Jeżeli wywoływana jest metoda, to stosie odkładane są dwie wartości – adres powrotu oraz wskaźnik do obiektu. Właśnie ten dodatkowy wskaźnik wykorzystuje stos systemowy do przechowania kontekstu.
Jeżeli wykorzystywany jest jawny stos, to należy pamiętać o poprawnej obsłudze wielowątkowości i zdefiniowaniu sekcji krytycznych. Prowadzi to do pewnych komplikacji, gdyż należy zadbać o uszeregowanie dostępu do zmiennych globalnych deklarowanych poza głównym wątkiem aplikacji. Szczegóły implementacji Delegatora w obydwu postaciach wraz z omówieniem zagadnień współbieżności można znaleźć w [Box], [Brown].
4.3. Osadzanie obiektu OE (object embedding)
Technika oparta na mechanizmie BD jest niewątpliwie bardzo elastyczna i stwarza duże możliwości rozszerzania i modyfikowania komponentów binarnych. Jest ona jednak zbyt wyrafinowana, jeżeli ma służyć wyłącznie do celów realizacji różnych trybów przekazywania parametrów. Należy pamiętać, że potrzebne jest jedynie dodanie do istniejącego komponentu binarnego nowej implementacji interfejsu IMarshal.
function TComObject.QueryInterface(const IID: TGUID; out Obj): Integer;begin if FController <> nil then Result := IUnknown(FController).QueryInterface(IID, Obj) else Result := ObjQueryInterface(IID, Obj);end;
4.4. VCL –implementacja QueryInterface [Lisch]
Proponowana technika – zwana dalej OE (Object Embedding) – jest najprostsza ze wszystkich tu omawianych. Jest ona modyfikacją metody opartej na agregowaniu obiektu. Polega na zastąpieniu agregowania obiektu prostym jego osadzeniem w obiekcie realizującym specyficzny marshaling. Osadzenie obiektu oznacza tutaj przechowywanie wskaźnika.
By przekonać się czy takie rozwiązanie jest dopuszczalne, należy przeanalizować, na czym polega agregowanie obiektów. Pomocna będzie tutaj analiza implementacji metody QueryInterface komponentu VCL –TComObject - rys. 4.4.
65
as, 3.01.-0001,
Tutaj tekst opisujący alokację pamięci dla stosu delegatora.

Okazuje się, że obiekt implementuje dwie metody QueryInterface, z których jedna jest prywatna i realizuje żądania dostępu do interfejsów obiektu, podczas gdy druga (publiczna) jest odpowiedzialna za agregowania obiektu i przekazywanie ewentualnych żądań do obiektu FController. FController jest obiektem agregującym i jako taki podejmuje decyzje, w jaki sposób implementacja obiektu będzie dekomponowana za pomocą obiektów zagregowanych. Tak więc, jedynym dodatkowym zadaniem obiektu zagregowanego jest przekazywanie wywołań QueryInterface do agregatu.
Po stronie przekazującej parametr QueryInterface będzie zawsze udostępniała interfejsy obiektu realizującego marshaling. Po drugiej stronie dostępne będą interfejsy właściwego obiektu.
W dalszym ciągu dostępne są możliwości ingerowania w stan obiektu w chwili jego odtwarzania w przestrzeni adresowej metody wywoływanej. Są one tylko nieznacznie ograniczone w stosunku do tych, które stwarzają techniki oparte na przekaźnikach. Ograniczenia dotyczą tylko przechwytywania późniejszych wywołań metod.
Pod jednym względem mechanizm osadzania obiektu jest bardziej elastyczny od przekaźnika. Wynika to z faktu, że połączenie obiektu z interfejsem IMarshal nie jest trwałe. W obrębie metody do, której parametr został przekazany może zostać podjęta decyzja o trybie dalszego przekazywania. Nie są tu konieczne żadne dodatkowe założenia odnośnie sposobu w jaki parametr został przekazany do metody.
Porównanie z metodami opartymi na agregacji wypada również na korzyść prostszego mechanizmu. W stosunku do agregacji osadzanie ma bowiem tę przewagę, że pozwala na modyfikowanie już istniejących obiektów. Agregacja nie daje takiej możliwości – gdyż obiekt jest agregowany w momencie tworzenia. Decyduje o tym parametr funkcji CoCreateInstance. Nie ma więc możliwości późniejszego dodania obiektu do agregatu. Poza tym wspomniano już, że nie wszystkie obiekty muszą obsługiwać agregowanie. Jest to fakt zaskakujący, jeśli zważyć prostą postać metody QueryInterface komponentu TComObject.
Jedyne założenie dotyczące obiektu wykorzystywanego w OE dotyczy interfejsu IPersistStream. Obiekt ten musi go implementować, by możliwy był trwały zapis stanu. Protokół DCOM określa jednak alternatywny sposób zapisu stanu, komplikując nieco sytuację. Niektóre obiekty implementują bowiem interfejs IPropertyBagPersist jako metodę trwałego zapisu. Mechanizm ten, niezgodny z filozofią strumieniowej reprezentacji, wydaje się preferowany w przypadku komponentów implementowanych w oparciu o bibliotekę MFC.
66

4.5. Ogólny schemat migracji opartej na rozdzieleniu stanu i klasy
67

Podstawową trudnością w przypadku komponentów opartych o IPropertyBag jest fakt, że interfejs ten nie jest w żaden sposób powiązany z marshalingiem. W przypadku IPersistStream i IMarshal strumień był niejako wspólnym mianownikiem obu interfejsów - obiektem danych, który mógł służyć do symulacji jednego mechanizmu przez drugi.
Chart ID : MBV ClassesChart Name : MBV ClassesChart Type : UML Class Diagram
ComponentMBVWrapper IMarshal
IUnknown
Component IPersistStorageIUnknown
4.6. Klasy realizujące MBV
Jedynym nasuwającym się rozwiązaniem dla komponentu implementującego IPropertyBag jest przekazanie interfejsu IPersistPropertyBag poprzez standardowe mechanizmy komunikacji (parę stub/proxy) wraz z zagregowaniem tego interfejsu. Następnie obiekt proxy może utworzyć kopię przekazywanego obiektu inicjując ją za pomocą zastępcy interfejsu IPersistPropertyBag.
4.4. Migracja obiektu na poziomie aplikacyjnym – RAW
Metoda MBV, aczkolwiek atrakcyjna pod względem technicznym może być w dalszym ciągu uważana za zbyt skomplikowaną, jeśli ma służyć do celów migracji obiektów w ramach systemu wielowarstwowego. Głównym zastosowaniem MBV jest rozszerzenie standardowego marshaling’u, mające na celu przejrzyste przekazywanie parametru obiektowego w DCOM - tzn. wywołanie przekazujące obiekt oraz sam obiekt nie muszą w żaden sposób współdziałać z procedurą przekazywania parametru w trybie przez wartość. W tym miejscu należy powtórzyć spostrzeżenie, że obiektowe języki programowania nie określają semantyki przekazywania obiektów przez wartość. W związku z tym, uzasadnione jest osadzenie przekazania przez wartość w obszarze
68

aplikacyjnym. Zostanie teraz zaproponowana bardziej adekwatna technika, nie czyniąca powyższych założeń.
Przesłanki prezentowanej metody są następujące:
- Migracja kodu oraz migracja stanu obiektu mogą odbyć się oddzielnie. Oznacza to, że kod wykonywalny dostarczany jest do węzła docelowego poprzez standardowy mechanizm DCOM jakim jest zarejestrowanie klasy w systemie.
- Zmiana węzła systemu jest równoważna przekazaniu komponentu DCOM implementującego dany obiekt w trybie MBV.
- Implementacja może zawierać specjalizowane metody obsługujące mobilność. Inaczej jest w MBV, gdzie standardowy komponent ActiveX nie współdziała w żaden sposób z procesem migracji. MBV zakłada jedynie, że komponent implementuje interfejs IPersistStream. Innymi słowy: możliwość przekazania obiektu danej klasy należy do definicji jego typu (dlatego poziom aplikacyjny).
Przedstawiona dalej metoda opiera się na ogólnej zasadzie rozdzielenia stanu i implementacji. Rekord danych będący postacią transportową (application level marshaling) składa się z dwóch części: identyfikatora typu obiektu oraz zasobu danych reprezentujących stan. Identyfikatorem typu w przypadku protokołu DCOM jest 128 bitowa liczba określana jako identyfikator klasy (CLSID). Alternatywnie można użyć tzw. czytelnego identyfikatora (PROGID), który ma postać łańcucha. Istnieją funkcje DCOM zapewniające odwzorowanie pomiędzy tymi dwoma identyfikatorami. Jak już wspomniano jednej klasie mogą na różnych węzłach systemu odpowiadać różne implementacje, dlatego też PROGID wydaje się słusznym wyborem.
Zakłada się, że poszczególne węzły są obiektami DCOM, zapewniającymi obsługę migracji. Komponenty te są statyczne (same nie migrują) – reprezentują za to węzły systemu np. agentowego. W przykładzie występują dwa komponenty DCOM: MobileAgent oraz AgentSystem. Podstawową metodą publiczną komponentu AgentSystem jest dwuargumentowa procedura ReceiveAgent. Parametrami metody są: identyfikator klasy (w przykładzie użyto PROGID) oraz interfejs reprezentujący strumień. Jej zadaniem jest odtworzenie w węźle docelowym agenta o podanym typie oraz zainicjowanie go przy użyciu strumienia (dana typu IStream). Należy pamiętać, że zgodnie z regułami DCOM strumień zostanie przekazany przez referencję - utworzony zostanie kanał komunikacyjny, za pomocą którego nowoutworzony obiekt wczyta swoje dane. Procedura SendAgent wywoływana jest dla lokalnego węzła systemu agentowego. Jej parametrami są obiekt agenta mobilnego oraz węzeł zdalny (jako proxy).
69

procedure TMobileAgent.Deserialize(const cargo: IUnknown);var stg:IStream; size:word; drop:longInt;begin stg:=cargo as IStream; stg.Read(@size,sizeof(size),@drop); SetString(Finfo,nil,size); stg.Read(@FInfo[1],size,@drop);
stg.Read(@size,sizeof(size),@drop); SetString(id,nil,size); stg.Read(@id[1],size,@drop);
CoUnMarshalInterface(stg,IID_IDispatch,Callback);end;
procedure TMobileAgent.Serialize(const cargo: IUnknown);var stg:IStream; size:word; drop:longInt;begin stg:=cargo as IStream; size:=length(FInfo); stg.Write(@size,sizeof(size),@drop); stg.Write(@FInfo[1],size,@drop);
size:=length(id); stg.Write(@size,sizeof(size),@drop); stg.Write(@id[1],size,@drop);
CoMarshalInterface(stg,IID_IDispatch,Callback, MSHCTX_DIFFERENTMACHINE,
nil,MSHLFLAGS_NORMAL);end;
4.7. Zapis i odtworzenie stanu
Można uniknąć przekazywania parametru reprezentującego IStream. Alternatywą jest w tym przypadku zapisanie strumienia do obszaru pamięci. Następnie obszar ten zostaje przesłany jako argument wywołania funkcji odpowiedzialnej za migrację. Po stronie docelowej blok danych służy do zainicjowania strumienia pamięci, z którego obiekt wczytuje swój stan. Jak wykazały testy, szybkość działania obu metod jest zbliżona. Różnica dotyczyć może jedynie kwestii bezpieczeństwa (poufności). Transmisja za pomocą strumienia musi polegać na mechanizmach utajniania protokołu sieciowego, podczas gdy blok danych może być zaszyfrowany przez węzeł systemu. Oczywiście nic nie stoi na przeszkodzie by obiekt sam szyfrował i odszyfrowywał swoje dane – odpowiednio w procedurach zapisu i odczytu ze strumienia.
70

function TAgentSystem.ReceiveAgent(const agentType: WideString; const cargo: IUnknown): Integer;var agent:Variant;begin agent:=CreateOleObject(agentType); agent.Deserialize(cargo as IStream); agent.AgentSystem:=self as IAgentSystem; agent.Start; //asynchronous – initializes work thread and returns result:=OK; //no error handlingend;
procedure TAgentSystem.SendAgent(const agent:Variant;const targetAgentSystem:TAgentSystem);var sa:TStreamAdapter; ms:TMemoryStream;begin ms:=TMemoryStream.Create; sa:=TStreamAdapter.Create(ms);
agent.Callback:=TCallback1.Create as IDispatch; agent.Serialize(sa as IUnknown); ms.Seek(0,soFromBeginning); targetAgentSystem.ReceiveAgent(agent.ProgId,sa as IUnknown); ms.Free;sa.Free;end;
4.8. Procedury migracji
Obiekt z przykładu, chociaż oparty na protokole DCOM nie jest komponentem ActiveX. Implementuje on tylko swój aplikacyjny oraz operacyjny interfejs (dualny tzn. zarówno IDispatch jak i VMT). Korzyścią płynącą z implementacji standardowych interfejsów ActiveX mogłoby być np. wykorzystanie standardowych aplikacji obsługujących takowe komponenty do celów komunikacji z użytkownikiem. Rozszerzenie to mogłoby być również korzystne z punktu widzenia integracji z istniejącymi aplikacjami. Autor jednak nie posiada doświadczeń w tym zakresie.
Utarło się przekonanie, że: po pierwsze, migracji wymaga zastosowania specjalizowanego środowiska tworzenia oprogramowania; po drugie, zagadnienia interoperacyjności są domeną języka Java lub innych przenośnych języków interpretowanych*. Jednym z celów tej pracy jest zakwestionowanie poglądów tego typu. Środowisko protokołu obiektowego, dzięki zastosowaniu odpowiednich technik i architektur, może z powodzeniem realizować cechy operacyjne agentów.
Szczególna rola, która w obrębie architektur rozproszonych jest przypisywana językowi Java może być uznana za przesąd. Zagadnienie interoperacyjności może być rozwiązane przy pomocy specjalizowanych implementacji. Nic nie stoi bowiem na przeszkodzie, by tej samej klasie (identyfikowanej przez CLSID lub PROGID)
* Np.Tcl – migracja na poziomie kodu źródłowego, ew. lansowane przez MS język C# i technologia .NET z językiem pośrednim i kompilacją JIT
71

odpowiadały na różnych węzłach systemu rzoproszonego różne implementacje. Podejście to stwarza dodatkową szansę niwelowania różnic semantycznych środowiska informacyjnego agenta (rozdz.4.5).
O ile zapis „nieobiektowych” danych nie różni się niczym od zapisu do pliku, to komponenty osadzone wewnątrz agenta muszą być przekazywane zgodnie z regułami DCOM. Należy w tym przypadku zdecydować czy reprezentowany przez interfejs komponent ma być przekazany przez wartość (para CLSID/PROGID i przekazany w trybie MBR interfejs strumienia) czy też przez referencję (funkcja CoMarshalInterface może mieć za parametr adapter strumienia użytego w migracji agenta). Oczywistym zastosowaniem interfejsów przekazanych przez referencję mogą być zadania związane z komunikacją między agentami. Na rys. 4.8 pole Callback zawiera wskaźnik do interfejsu typu IDispatch. Pole to jest przekazywane w trybie MBR
Istotnym zagadnieniem w ramach DCOM jest zestawienie połączenia pomiędzy dwoma węzłami (np. systemu agentowego). Jak już zauważono w rozdz. 2.3, dostępne funkcje zorientowane są raczej na tworzenie nowych obiektów niż uzyskiwanie połączeń z już istniejącymi. Standardowy mechanizm oparty na ROT (Running Object Table) i tzw. Monikerach nie wydaje się adekwatny. Autor opracował więc własny sposób, korzystający ze strumieniowej reprezentacji obiektów typu proxy. Co ważne ta alternatywna metoda daje się łatwo zintegrować z usługami katalogowymi (LDAP, X500, ActiveDirectory) lub bazami danych (rozdz. 2.3 ) W ten sposób możliwa jest m.in. techniczna realizacja zadania wyznaczania trasy agenta i wyszukiwania istniejących agentów w systemie rozproszonym .
Podsumowując można wymienić następujące zalety przedstawionej metody migracji obiektów:
- możliwość mutowania implementacji agenta (identyfikator typu GUID 128 bitów może być rozstrzygany w kontekście danej platformy lub nawet środowiska informacyjnego – dokładniej opisane w rozdz. 4.5 – punkt Heterogeniczne źródła danych)
- możliwość integracji z rozproszonymi usługami katalogowymi zgodnymi ze standardami, usługami komunikacyjnymi (np. wysłanie agenta przez e-mail)
- wydajność kod wykonywalny może być pobierany z serwera plikowego położonego najbliżej węzła docelowego
- optymalne kodowanie danych (strong vs. weak migration),
4.5. Mobilność agentów
Rozdział ten jest dalszym ciągiem rozważań na temat obsługi własności operacyjnych architektur agentowych zapoczątkowanych w rozdz. 3.5. Jako jedna z dwóch własności operacyjnych została w nim wymieniona mobilność agenta.
72

Mobilność jest określana jako brak stałego przypisania agenta do węzła sieci. Oznacza to, że po utworzeniu i rozpoczęciu przetwarzania agent może zmieniać ten węzeł, dostosowując swoje położenie w zależności od zasobów, z których korzysta lub innych czynników mających wpływ na szybkość realizacji zlecenia lub na stan systemu.
Mobilność jest cechą pożądaną z wielu względów. Za [Ametas, Scheb, Wood, Dierks, Hohl, Gray] można stwierdzić, że po pierwsze dzięki mobilności agenci nie są na stałe fizycznie przypisani do jednego systemu, mogą natomiast swobodnie zmieniać swoją lokalizację. Dzięki temu zmniejszone jest obciążenie sieci, ponieważ agent, po przejściu na nowy węzeł, nie musi już pobierać z niego danych z odległego węzła. Obliczenia wykonywane są tam, gdzie dostępne są dane. Cecha ta jest istotna z punktu widzenia aplikacji czasu rzeczywistego, w których cechy wydajnościowe odgrywają szczególną rolę. Zmiana węzła może być również korzystna, gdyż w pewnych sytuacjach prowadzi do bardziej równomiernego wykorzystania elementów sieci i równoległości obliczeń. Węzeł inicjujący przetwarzanie zostaje na czas „podróży” agenta odciążony. W ten sposób powstają niejako implicite wieloprocesorowe struktury obliczeniowe. Korzyść ta dotyczy również innych zasobów systemowych, prowadzi do zwiększonej skalowalności systemu i jego elastyczności.
Oprócz już wymienionych zalet , można podać jeszcze dwie, które są związane z poufnością i bezpieczeństwem. Mobilność agenta aczkolwiek uważana za wyzwanie jeśli chodzi o bezpieczeństwo systemu, może być też pewnym ułatwieniem, jeśli zostanie prawidłowo zaimplementowana. Jednorazowe uwierzytelnienie się agenta w momencie przechodzenia na węzeł zwiększa wydajność (jeśli agent znalazł się na „zaufanym” węźle), gdyż późniejszy dostęp do poufnych zasobów nie będzie wymagał powtarzania tego procesu – rys. 4.9. Co więcej zmniejszona ilość transmisji sieciowych związanych z dostępem do zasobów sprawia, że system jest mniej podatny na ewentualny podsłuch.
4.9. Poufność w systemie agentowym
73

Jak już wspomniano w rozdz. 2.4 mobilność może być uznana za cechę wyłącznie operacyjną. Oznacza to, że umiejętność zmieniania przez agenta swojej fizycznej lokalizacji nie ma wpływu na ostateczny wynik realizowanego przetwarzania. Dlatego też praca [Muel], będąca monografią poświęconą architekturom agentowym nie zajmuje się w ogóle tym zagadnieniem. Innym powodem unikania tej problematyki jej nieatrakcyjność dla autorów skoncentrowanych na kwestiach teoretycznych Co więcej pozornie czysto techniczny charakter zagadnienia wydaje się być mało pociągający z „naukowego” punktu widzenia.
Jak już wspomniano, utarło się przekonanie, że zagadnienie mobilności i ściśle związana z nim sprawa przenaszalności między platformami stanowi wyłączną domenę języka JAVA. Pogląd taki nie wydaje się słuszny. Rozdzielenie stanu obiektu, który jest reprezentowany w postaci pliku zawierającego niezależne systemowo dane oraz implementacji, która jest zależna od systemu sprawia, że kod wykonywalny może być inny za każdym razem gdy zmienia się platforma systemowo sprzętowa. Dostępność protokołu DCOM na UNIX (EntireX firmy Software AG) oraz coraz większa gama przenośnych narzędzi (przenośność na poziomie źródeł) sprawia, że możliwość ta jest realne, chociaż nie wykorzystano jej jeszcze praktyce.
4.10. Rozdzielona implementacja
Protokół DCOM, który zyskuje coraz większe uznanie nie tylko w ramach platformy Win32, może być bazą implementacyjną ogólnych architektur. W ten sposób wyeliminowana zostaje potrzeba istnienia wyspecjalizowanych (np. agentowych) środowisk czy języków. Jedynym wymogiem są bowiem dostępność funkcji obsługujących odpowiednie własności operacyjne architektur.
74

Heterogeniczne źródła danych. Odejście od czysto operacyjnego rozumienia mobilności agentów stwarza możliwość wykorzystania mechanizmu zróżnicowanej implementacji tychże, do celów integracji heterogenicznych źródeł danych. Agent przemieszczający się przy pomocy mechanizmu przekazywania parametru obiektowego przez wartość – korzysta w trakcie swej wędrówki z implementacji udostępnianych w ramach systemów agentowych dostępnych na kolejnych węzłach sieci.
Realizacja określonych przez typ agenta reguł przetwarzania nie zabrania stosowania w tym celu różnych implementacji. Implementacja agenta na konkretnym węźle sieci może być ściśle dostosowana do występujących na nim źródeł danych. Tak więc, agent z jednej strony realizuje ciągle to samo zadanie, z drugiej zaś dostosowuje się do otoczenia, niwelując w ten sposób zróżnicowanie semantyczne i operacyjne. Dzięki reprezentacji stanu oraz kompatybilności tychże reprezentacji na poziomie implementacji może być uważany ciągle za ten sam byt programowy.
Klasycznie rozumiana migracja obiektu służy przede wszystkim do realizacji zadań związanych z interoperacyjnością agenta. Nic nie stoi jednak na przeszkodzie, by poszczególne implementacje zawierały elementy zależne nie tylko od środowiska czasu wykonania ale również od ogólnie rozumianego środowiska informacyjnego. Jeżeli strukturę środowiska informacyjnego i związane z nią kwestie semantycznej i operacyjnej zgodności uznać za element środowiska czasu wykonania, to mobilność agenta może być nadal uważana za cechę operacyjną
Formalnie można metodę przekazywania przez wartość dopuszczającą różne implementacje komponentu (agenta) tego samego typu można przedstawić jako funkcję przypisującą klasie identyfikującej typ pewien plik z implementacją. W konwencjonalnej postaci jest to funkcja z jednym parametrem – klasą komponentu. W rozszerzonej architekturze wielowarstwowej, funkcja ta ma dwa parametry: wspomnianą klasę oraz identyfikator typu systemu agentowego. W bardziej ogólnej postaci ilość argumentów służących do zlokalizowania implementacji może zawierać dowolną ilość parametrów określających środowisko działania agenta. Parametry te mogą być statyczne (dostarczane prze system agentowy) lub dynamiczne pozyskiwane od egzemplarza agenta – dostarczane przez algorytm wyznaczający trasę „wędrówki” (itinerary) agenta.
Transakcje kooperacyjne. Odejście od przetwarzania zorganizowanego w konwencjonalnie rozumiane transakcje, w których synchronizacja wielu użytkowników (agentów) była oparta na izolacji za pomocą blokowania dwufazowego, jest niezaprzeczalnym faktem [Rusin]. Konwencjonalne transakcje są zastępowane przez tzw. transakcje kooperujące, gdzie pojęcie ściśle (strict) rozumianej kompatybilności [Bernstein] zostało zastąpione poprzez kryteria specyfikowane poprzez konkretne reguły przetwarzania.
75

Z tego powodu, zadania synchronizacji oraz odtwarzania nie mogą być realizowane przez standardowo rozumianego menedżera danych. W istocie, odtwarzanie realizowane poprzez operację kompensacji [Rusin] polega na wykonaniu pewnych aplikacyjnych reguł przetwarzania, które nie mogą być osadzone w oprogramowaniu systemowym.
Rozszerzona architektura wielowarstwowa, której składowe są komponentami (software entities) pod względem operacyjnym kompatybilne np. z agentami (mobilność oraz asynchroniczność) stanowi interesującą propozycję techniki implementacji złożonych reguł przetwarzania synchronizacji oraz kompensacji.
Zagadnienie wykorzystania architektur agentowych dla wykonywania transakcji zostało przedstawione w [Zygmunt]. Praca ta zajmuje się jednak wyłącznie problemem specyfikowania różnych metod synchronizacji (blokowanie optymistyczne, dwufazowe i semantyczne – stanowiące pewien wariant synchronizacji kooperacyjnej). Oczywiście dowolny sposób synchronizacji można opisać za pomocą imperatywnego języka programowania czy też odpowiednio bogatego formalizmu.
Dla praktycznych zastosowań istotne jest przede wszystkim istnienie bazy implementacyjnej oraz sprawdzonego środowiska czasu wykonania. Możliwość wyspecyfikowania reguł przetwarzania związanych z synchronizacją i odtwarzaniem w jednym z języków (Pascal,C++, Basic) wraz ze sprawdzonymi protokołami obiektowymi rozszerzonymi o przekazywanie przez wartość oraz przetwarzanie synchroniczne jest podstawą udanej implementacji systemu kooperacyjnego – opartego na paradygmacie transakcji kooperacyjnej.
Synchronizacja i przetwarzanie transakcji rozproszonych, oparte o różne protokoły tejże synchronizacji, może być sprowadzone do zagadnienia dostępu do heterogenicznych źródeł danych. Każde ze źródeł realizuje (przykładowo w ramach określonego typu systemu agentowego) – swoją politykę synchronizacji.
76

5. Dynamiczny polimorfizm
W konwencjonalnej technologii tworzenia aplikacji (związanej z architekturą monolityczną, klient-serwer, czy klasyczną trójwarstwową) istnieje ścisłe rozgraniczenie pomiędzy fazami rozwoju (development time) oraz eksploatacji (run time). W takim podejściu identyfikatory typów i zmiennych potrzebne są tylko w fazie tworzenia i późniejszej konsolidacji. Identyfikatory te, przechowywane w tablicy symboli kompilatora, są w fazie konsolidacji zamieniane na adresy fizyczne.
Nowe eksperymentalne architektury (rozdz. 2.2) z uwagi na postulowaną możliwość dynamicznej konfiguracji wymagają, by poszczególne wymienne składowe zawierały oprócz kodu wykonywalnego również informacje o używanych typach danych, identyfikatorach dostępnych metod itd. Jeżeli przyjąć, że poszczególne składowe są komponentami ( w sensie specjalizacji obiektów) obiektowego protokołu sieciowego to wszystkie typy i metody zorganizowane są w postaci interfejsów . Jak już wspomniano w rozdz. 2.3, protokół DCOM nie rozwiązuje problemu statycznej struktury typów (konieczność zadeklarowania interfejsu). To ograniczenie jest technicznym wyrazem wymogu związanego z dynamiczną konfiguracją. Można zauważyć, że jest to aspekt pewnego ogólniejszego zagadnienia, które polega na udostępnieniu wszystkich mechanizmów obiektowych (dziedziczenie, polimorfizm, kapsułkowanie, specjalizacja) poprzez konfigurację i kompozycję binarnych elementów. W ramach DCOM próbą przezwyciężenia problemów związanych z tablicą symboli są tzw. biblioteki typów (rozdz. 5.1).
Powyższe uwagi dotyczą języków kompilowanych. Duża popularność języków interpretowanych* (TCL, PEARL) czy quasi-interpretowanych (Java) w obszarze aplikacji wielowarstwowych jest również związana ze stałą dostępnością symboli i możliwością manipulowania kodem źródłowym. Operacja na tekście i wykonana następnie interpretacja może w prosty sposób dodać nowe lub zmodyfikować istniejące typy. O ile stosowanie języków interpretowanych jest nieograniczenie dopuszczalne w systemach eksperymentalnych, to aplikacje wymagają ze względów wydajnościowych użycia języków kompilowanych.
Ogólnym sposobem umożliwiającym połączenie wydajności i elastyczności wspomnianych dwóch typów języków jest tzw. refleksja (rozdz. 5.2). Mechanizm ten powstał w ramach badań nad specyfikacją semantyki języków. Miał on umożliwiać rozszerzanie języka programowania o nowe samo-opisujące się konstrukcje. Zgodnie z przyjętą konwencją każdemu nowemu elementowi miał towarzyszyć opis na poziomie meta. Całość specyfikacji miała być w stanie dokonywać analizy dostarczonego opisu i automatycznie rozszerzać język [Maes].
* Oczywiście podstawowym czynnikiem jest przenaszalność na poziomie kodu źródłowego.
77

Co ciekawe, mechanizm zbliżony do refleksji pojawił się (prawdopodobnie w niezamierzony sposób) w środowiskach programowania, zawierających ułatwienia dla ActiveX. Takie środowiska jak Delphi, VisualC++, czy też VisualBasic posiadają możliwość automatycznej „introspekcji” komponentu, zadeklarowania odpowiednich typów danych i w efekcie rozszerzenia języka „środowiska” o nowy element. Odbywa się to poprzez analizę wspomnianego szczególnego typu metadanych jakim jest biblioteka DCOM. Dodatkowo, pojawienie się metadanej opisującej typ, która sama jest obiektem danych rozszerza w oczywisty sposób język o mechanizm typów formalnych i zmiennych*.
W ogólnym przypadku, Metadane [Kash] określa się jako informacje na temat logicznego uporządkowania danych – opisującymi ich strukturę (czyli typy danych) i przeznaczenie. Metadane pojawiają się najczęściej w kontekście baz danych, zawierając opis schematu, np. w postaci skryptu SQL. Metadane zawierają też informacje niezbędne do odczytywania i przetwarzania opisywanych przez nie danych. Istotne jest, żeby metadane były dostępne również w czasie działania systemu, a nie tylko w czasie jego implementowania. Co więcej, zawarte w nich informacje powinny umożliwić wykorzystanie zasobu danych (rozumianego jako komponent) czy innej jednostki programowej dostępnej jedynie w postaci binarnej. Dlatego bibliotekę typów określa się też jako „instrukcję obsługi” czy „podręcznik programisty” [Platt], z którego mogą korzystać zarówno użytkownicy (za pośrednictwem odpowiednich przeglądarek) jak też programy odwołujące się do funkcji komponentu.
Metadane mają następujące przeznaczenie:
- powinny umożliwiać abstrakcję szczegółów reprezentacji takich jak format czy organizacja danych, i rejestrować zawartość zasobu niezależnie od szczegółów implementacyjnych,
- powinny umożliwiać reprezentację wiedzy dziedzinowej, opisując dziedzinę do której dane należą.
Spełnienie pierwszego z wymienionych warunków zapewnia standaryzacja formatów plików zawierających metadane. W przypadku DCOM specyfikacja formatu bibliotek danych nie została opublikowana – podane zostały natomiast funkcje systemowe służące do przetwarzania tej biblioteki. Z kolei, możliwość reprezentacji odpowiednio złożonej semantyki zapewnia odpowiednio duża elastyczności języka IDL służącego do definiowania typów obiektowych.
* W bibliotece MFC makro RUNTIME_CLASS, w Delphi typ zmiennej class of – należy zauważyć, że opis meta może być przechowywany lub przekazany jako parametr i następnie użyty do utworzenia egzemplarza klasy.
78

Biblioteki typów protokołu DCOM nie są jedynym spośród standardów metadanych mających praktyczne zastosowanie. Przykładami standardów, które można zaklasyfikować do tej samej kategorii co biblioteki typów protokoły DCOM mogą być:
- RTTI (Runtime Type Information) z Delphi - DTD (Document Type Definitions ze standardu XML).
Oprócz tego istnieje pewna ilość prototypowych rozwiązań służących wyłącznie celom badawczym. Wspólną ich cechą jest pewne „wyobcowanie” w stosunku do zadań stawianych środowiskom programowania oraz ignorowanie istniejących standardów - zwłaszcza w obrębie protokołów obiektowych.
Wspomniany standard RTTI stanowi rozwiązanie alternatywne oraz komplementarne w stosunku do bibliotek typów DCOM [Lisch]. Służy on do przechowywania informacji o klasach, które to informacje mogą być wykorzystane zarówno w czasie tworzenia aplikacji jak i jej wykonania. Wewnętrznie jest RTTI wykorzystane, między innymi, do odwzorowania logicznych identyfikatorów metod i własności na ich implementację fizyczną służąc w ten sposób do realizacji mechanizmu wywołania poprzez interfejs IDispatch.
W rozdz. 5.3 zostanie przedstawiona propozycja elastycznego wykorzystania interfejsu IDispatch określona jako dynamiczny polimorfizm. Metoda oparta jest na spostrzeżeniu, że interfejs ten nie reprezentuje sam typu danych, daje jednak możliwość opisu szerokiej klasy typów obiektowych. Okaże się, że może on reprezentować rodzaj mini-interpretera osadzonego w języku kompilowanym. Co więcej, klasa (typ) obiektu może w trakcie jego cyklu istnienia podlegać zmianom. Innymi słowy typ może być uznany w tym przypadku jako wartość (value) – wynik pewnego procesu obliczeniowego. Procesem tym może być, w najbardziej oczywistym przypadku, analiza struktury danych przechowująca symbole lub np. interpreter pliku DTD (definicja typu dokumentu XML).
Pomijając kwestie związane z eksperymentalnymi architekturami, dynamiczny polimorfizm może być cennym narzędziem w programowaniu mobilnych agentów, działających w zmieniającym się wraz z wędrówką środowisku lub w zagadnieniach związanych z bazami danych, czy też dostępem do usług katalogowych. W tym miejscu trzeba podkreślić, że bazy danych zawsze stanowiły pewien szczególny przypadek, ponieważ zasób danych zwykle przechowywał i udostępniał informacje o swojej strukturze. Uwaga ta dotyczy baz SQL. Funkcje inżynierii odwrotnej, obecne w wielu narzędziach do modelowania, mogą być również uznane za przypadek refleksji. Nowa jakość uzyskana z zastosowaniem dynamicznego polimorfizmu w tym obszarze wynika z odejścia od klasycznego modelu sterowników (ODBC) na rzecz modelu komponentowego (OLEDB – por. rozdz. 5.2)
ITypeInfo = interface(IUnknown)
79

['{00020401-0000-0000-C000-000000000046}'] function GetTypeAttr(out ptypeattr: PTypeAttr): HResult; stdcall; function GetTypeComp(out tcomp: ITypeComp): HResult; stdcall; function GetFuncDesc(index: Integer; out pfuncdesc: PFuncDesc): Hresult; stdcall; function GetVarDesc(index: Integer; out pvardesc: PVarDesc): Hresult; stdcall; function GetNames(memid: TMemberID; rgbstrNames: PBStrList; cMaxNames: Integer; out cNames: Integer): HResult; stdcall; function GetRefTypeOfImplType(index: Integer; out reftype: HrefType): HResult; stdcall; function GetImplTypeFlags(index: Integer; out impltypeflags: Integer): HResult; stdcall; function GetIDsOfNames(rgpszNames: POleStrList; cNames: Integer; rgmemid: PMemberIDList): HResult; stdcall; function Invoke(pvInstance: Pointer; memid: TMemberID; flags: Word; var dispParams: TDispParams; varResult: PVariant; excepInfo: PExcepInfo; argErr: PInteger): HResult; stdcall; function GetDocumentation(memid: TMemberID; pbstrName: PwideString; pbstrDocString: PWideString; pdwHelpContext: PLongint; pbstrHelpFile: PWideString): HResult; stdcall; function GetDllEntry(memid: TMemberID; invkind: TInvokeKind; out bstrDllName, bstrName: WideString; out wOrdinal: Word): Hresult; stdcall; function GetRefTypeInfo(reftype: HRefType; out tinfo: ITypeInfo): HResult; stdcall; function AddressOfMember(memid: TMemberID; invkind: TinvokeKind; out ppv: Pointer): HResult; stdcall; function CreateInstance(const unkOuter: IUnknown; const iid: TIID; out vObj): HResult; stdcall; function GetMops(memid: TMemberID; out bstrMops: WideString): HResult; stdcall; function GetContainingTypeLib(out tlib: ITypeLib; out pindex: Integer): HResult; stdcall; procedure ReleaseTypeAttr(ptypeattr: PTypeAttr); stdcall; procedure ReleaseFuncDesc(pfuncdesc: PFuncDesc); stdcall; procedure ReleaseVarDesc(pvardesc: PVarDesc); stdcall; end;
4.1 Interfejs informacji o typie
5.1. Biblioteki typów
Jeden z elementów wchodzących w skład protokołu DCOM/COM biblioteka typów (Type library, pliki z rozszerzeniem.tlb,.olb)jest standaryzowanym statycznym plikiem zawierającym opis metod, własności i interfejsów typów obiektowych. Jest ona pewnym szczególnym przypadkiem zasobu informacyjnego, który zawiera metadane. Biblioteka typów może też być postrzegana jako binarny odpowiedniki znanych z języków programowania, deklaracji typów danych, który jest dostępny w czasie wykonania programu. Istotnie, w ramach protokołu DCOM biblioteka typów powstaje jako wynik kompilacji kodu napisanego w języku IDL. Uzyskany w ten sposób plik binarny nie zawiera w sobie kodu wykonywalnego – zamiast tego jest on binarną reprezentacją dostępnych typów.
80

Zadaniem biblioteki typów jest (podobnie jak dwóch innych przykładów metadanych) reprezentowanie informacji o typach w czasie wykonania oraz w czasie tworzenia aplikacji. W ten sposób wyeliminowana zostaje konieczność dostępu do kodów źródłowych czy choćby plików nagłówkowych komponentów. Dostęp do nich jest możliwy poprzez zastosowanie mechanizmów introspekcji – analizy odpowiednich danych binarnych. Komponent lub aplikacja, która ma uzyskać dostęp do innego komponentu może zanalizować jego funkcjonalność poprzez wywołanie standardowych funkcji API obsługujących biblioteki typów.
ITypeLib = interface(IUnknown) ['{00020402-0000-0000-C000-000000000046}'] function GetTypeInfoCount: Integer; stdcall; function GetTypeInfo(index: Integer; out tinfo: ITypeInfo): Hresult; stdcall; function GetTypeInfoType(index: Integer; out tkind: TtypeKind): HResult; stdcall; function GetTypeInfoOfGuid(const guid: TGUID; out tinfo: ItypeInfo): HResult; stdcall; function GetLibAttr(out ptlibattr: PTLibAttr): HResult; stdcall; function GetTypeComp(out tcomp: ITypeComp): HResult; stdcall; function GetDocumentation(index: Integer; pbstrName: PwideString; pbstrDocString: PWideString; pdwHelpContext: PLongint; pbstrHelpFile: PWideString): HResult; stdcall; function IsName(szNameBuf: POleStr; lHashVal: Longint; out fName: BOOL): HResult; stdcall; function FindName(szNameBuf: POleStr; lHashVal: Longint; rgptinfo: PTypeInfoList; rgmemid: PMemberIDList; out pcFound: Word): HResult; stdcall; procedure ReleaseTLibAttr(ptlibattr: PTLibAttr); stdcall; end;
4.2 Biblioteka typów (Type Library)
Obiekt obsługujący automatyzację OLE (czyli implementujący interfejs IDispatch) dostarcza informacje na temat swojej struktury za pomocą pliku zawierającego bibliotekę typów [Platt]. Biblioteka typów jest zestawem statycznych struktur danych udostępnianych przez autorów komponentów, które mogą być przetwarzane za pośrednictwem interfejsu ITypeLib (4.1) (za [Brock])
Dostęp do interfejsu ITypeLib można uzyskać na dwa sposoby: dla bibliotek zarejestrowanych wywołać funkcję LoadRegTypeLib lub w przeciwnym przypadku funkcję LoadTypeLib. Obydwie funkcje udostępniają interfejs ITypeLib. Szczegółowy opis metod analizy biblioteki typów zawiera książka D.Platta [Platt] oraz artykuł [Pietrek]. Kluczową rolę odgrywają tutaj metody GetTypeInfo i GetTypeInfoCount, za pomocą których można iterować po składowych typach obiektowych opisywanych przez bibliotekę. Metoda GetTypeInfo przekazuje opis pojedynczego typu, reprezentowanego przez obiekt implementujący interfejs ITypeInfo.
Podobnie jak w przypadku ITypeLibrary interfejs ITypeInfo zawiera informację o ilości pozycji opisywanych w ramach konkretnego typu i, jeśli jest to konieczne,
81

umożliwia rekurencyjne wywoływanie metody GetTypeInfo. W ten sposób możliwa jest reprezentacja dowolnej drzewiastej struktury typów. Należy zauważyć, że hierarchię typy tworzą raczej przez mechanizm kompozycji – wzajemnego zawierania się a nie dziedziczenia. Dziedziczenie, a raczej jego pewien wariant realizowany jest za pomocą agregacji obiektów – techniki umożliwiającej obiektowi udostępnianie interfejsów zawartych w sobie obiektów jako własnych. Mechanizm ten zostanie jeszcze przywołany w rozdz. 4, zaś szczegółowy jego opis można znaleźć w [Platt].
Drugą funkcją, obok udostępniania metadanych, realizowanych przez biblioteki typów jest obsługa mechanizmu automatyzacji OLE (OA) i wsparcie dla implementacji interfejsu IDispatch. Biblioteka typów może zostać utworzona dla dowolnego interfejsu (dualnego, vtlb lub OA). W przypadku interfejsu opartego na tablicy metod wirtualnych potrzebne jest, jeżeli ma on obsługiwać automatyzację OLE, odwzorowanie logicznych parametrów użytych w wywołaniu metody Invoke na fizyczne adresy odpowiadających im metod interfejsu. Funkcja ta może być realizowana przez kod programu lub poprzez wywołanie Invoke oraz GetIDsOfNames. Implementacja ogranicza się wtedy do opakowania odpowiednich wywołań. W bibliotece VCL zastosowano podejście innego typu. Odwzorowanie zostało oparte o własną reprezentację metadanych - wspomniane już RTTI. Prywatna funkcja biblioteczna GetAutoEntry przeszukuje liniowo przechowywane w tablicy metod wirtualnych informacje o typach. Niezależnie od RTTI Delphi generuje dla implementowanych w tym środowisku komponentów ActiveX biblioteki typów zgodne z DCOM.
Informacje o typach mogą być używane zarówno wewnątrz obiektu czy komponentu jak i na zewnątrz. Użycie wewnętrzne służy do obsługi interfejsów OA (w przypadku ogólnym) oraz do całościowej obsługi interfejsów COM – jak to ma miejsce w przypadku RTTI w Delphi. Znacznie istotniejsze jest wykorzystanie struktur opisujących typ na zewnątrz implementacji. Opis ten umożliwia dostęp do komponentu innym składowym systemu rozproszonego (kooperacyjnego) – publikując jego własności i metody.
Oprogramowaniem, które jako pierwsze dysponowało możliwościami analizy danych tego typu były narzędzia programistyczne. Wszystkie bez wyjątku środowiska tworzenia aplikacji typu RAD w środowisku Windows są w stanie obsługiwać komponenty i generować automatycznie odpowiednie pliki źródłowe będące reprezentacją obiektu w danym języku. Chociaż biblioteki typów były przeznaczone głównie do tego typu zastosowań – integracji w środowiskach programistycznych - nic nie stoi na przeszkodzie aby wykorzystać je również w oprogramowaniu aplikacyjnym, realizując w ten sposób jeden z postulatów CIS (Architektury Kooperacyjne) – mechanizm refleksji.
82

5.2. Refleksja w systemach kooperacyjnych
Refleksja [Edmo] w systemie informatycznym oznacza umiejętność dynamicznego dostosowania się aplikacji do interfejsu autonomicznego komponentu. Jej realizacja wymaga by dostępny był opis takiego interfejsu. Ważne jest również by ten opis był czytelny dla aplikacji. W ten sposób możliwe jest modyfikowanie aplikacji w trakcie jej działania i dostosowywanie jej do zmieniających się warunków. Istotą refleksji jest więc zacieranie wyraźnej granicy pomiędzy czasem tworzenia aplikacji a czasem jej wykonywania. Wysokie wymagania stawiane przez użytkownika aplikacjom w zakresie możliwości ich modyfikowania i dostosowywania do dynamicznych zmian sprawiają, że niezbędne stają się mechanizmy dostępne dotychczas wyłącznie podczas tworzenia.
Cele, które stawiali sobie twórcy standardu CORBA opisywane bywają [Manola] przez analogię z magistralą ISA znaną z komputerów klasy PC. Protokół obiektowy pełni rolę magistrali, podczas gdy komunikujące się za jego pośrednictwem komponenty są odpowiednikami kart rozszerzających. W takim ujęciu mechanizm refleksji można przyrównać do standardu plug and play. Kooperacyjny system informatyczny jest bowiem w stanie dokonać analizy opisu komponentu (dzięki bibliotece typów lub interfejs IDispatch).
Z punktu widzenia architektur oprogramowania, postulatami, które zadecydowały o rozwoju mechanizmu refleksji były:
- Zadanie integracji wielu zasobów danych w konceptualnie spójny sposób. Szczególnie trudną było zagadnienie obsługi dynamicznie zmieniającego się środowiska informacyjnego, w którym źródła danych mogą dynamicznie pojawiać się i znikać, inne zaś mogą zmieniać swoją strukturę. Jako jeden ze szczegółowych problemów zidentyfikowano obsługę środowiska przyrostowego [Edmo], w którym rośnie ilość dostępnych zasobów danych, przy czym wzrost ten ma charakter również jakościowy. Reprezentacja modelu danych powinna więc zakładać zmienność w czasie i elastyczność jak również obsługę istniejących systemów (legacy systems)
- Realizacja aktywnej kooperacji pomiędzy wchodzącymi w skład rozproszonego systemu zasobami danych. W pracy [Edmo] zagadnienie do sprowadzono do wyodrębnienia czynników decydujących o sterowaniu interakcjami pomiędzy składowymi – dążąc do określenia istoty tej interakcji, którą jest dążenie rozproszonych komponentów do osiągnięcia wspólnego celu. Należy zauważyć, że jest to podejście bliskie architekturom agentowym.
Mechanizmy refleksji pojawiły się na początku w językach programowania. Były one pomocniczym elementem mającym na celu umożliwienie przyrostowej modyfikacji semantyki i implementacji. Dotyczyło to zarówno języków kompilowanych jak i interpretowanych. Głównym zaś celem było otwarcie specyfikacji języków na zmiany
83

poprzez zastosowanie meta opisów (meta-object protocol), dzięki czemu sam język przyjmował strukturę obiektowo-zorientowaną.
Meta opis (metadane) ma strukturę obiektową. Oznacza, że w samym opisie poziomu meta występują składowe będące obiektami. Opis ten, w języku programowania, zapewniał lepsze odwzorowanie konstrukcji językowych w semantykę. Ponieważ był on dostępny w postaci źródłowej, programista mógł go dostosowywać do swoich potrzeb.
Wcześnie zauważono, że mechanizmy te mogą być wykorzystane w architekturach kooperacyjnych [Stroud], [Edmo]. Pewne standardowe zadania związane z implementacją reguł przetwarzania, takie jak obsługa transakcji, przechowywanie danych, reprezentacją strumieniową mogą być specyfikowane za pomocą języka interpretowanego w czasie wykonania. Jako główny kandydat, realizujący te wymagania został uznany obiektowy meta opis. Stało się to podstawą wielu implementacji [Stroud], [Kari], [Kiczales]. Należy zauważyć, że wszystkie one miały charakter wyłącznie naukowo- badawczy i nie doczekały się zastosowań w praktycznie implementowanych projektach.
Opisane we wstępie do bieżącego rozdz. biblioteki typów realizują, przynajmniej częściowo, opisywany tutaj mechanizm. Chociaż składają się z danych statycznych, to zawierają w sobie pełny opis interfejsów realizowany przez dany komponent. W tym znaczeniu są danymi dynamicznymi, związanymi z komponentem.
Dzięki dostępnym w systemie operacyjnym (w ramach protokołu DCOM) funkcjom służącym do analizy biblioteki, składowe systemu kooperacyjnego są w stanie pozyskać informacje o własnościach komponentu. Odbywa się to bez dostępu do kodu źródłowego. Komponent, wraz z towarzyszącą mu biblioteką może w dowolnym momencie zostać dołączony do systemu. Ewentualnie może też zastąpić komponent funkcjonujący już w systemie. W niektórych przypadkach jest to możliwe również bez zatrzymywania i ponownego uruchamiania systemu [Blair,Coulson].
Należy zauważyć, że przytoczone na początku rozdziału jako przykład, zasoby baz danych mogą też być postrzegane jako komponenty. Nic nie stoi na przeszkodzie by biblioteka typów zawierała w sobie opis obiektów bazy danych. Byłoby to jednak, w ramach stosowanej obecnie praktyki rozwiązanie ekscentryczne. Biblioteki typów zawierają za to opisy definicji komponentów realizujących dostęp do baz danych. Przykładem może być OLEDB. Obecne w tej bibliotece komponenty są na tyle elastyczne, że umożliwiają dostęp do danych organizacji bardziej złożonej niż relacyjna [Beauch]. Co więcej możliwa jest też, w ramach tej biblioteki, analiza schematu relacyjnego i identyfikacja wchodzących w jego skład tabel i widoków.
84

Podawane jako jedna z przyczyn uzasadniających znaczenie mechanizmu refleksji, dążenie do zapewnienia zunifikowanego dostępu do zasobów danych – rozumianych przede wszystkim jako bazy danych, doczekało się również rozwiązania w ramach protokołu DCOM. Obecnie wystarczy by dany język czy środowisko programistyczne obsługiwało ten protokół. Biblioteka OLEDB wchodzi w skład standardowej wersji Windows i obsługuje połączenia ze wszystkimi bazami danych dla których istnieją sterowniki ODBC. W ten sposób, dotyczy to na razie jedynie Windows, zanikła konieczność tworzenia specjalnych środowisk programistycznych zorientowanych na tworzenie aplikacji baz danych. Wiodące narzędzia takie jak Delphi, VC++ czy VB są językami ogólnego przeznaczenia. Jedną z przyczyn takiego stanu rzeczy jest realizacja dostępu do bazy za pomocą komponentu. W przypadku Delphi odbywa się to obecnie przy wykorzystaniu własnych rozwiązań, którymi są BDE (odpowiednik ODBC), VCL + MIDAS (odpowiadający w zakresie komunikacji z bazami danych bibliotece OLEDB).
Komunikacja z bazą danych za pomocą komponentów, oprócz obsługi mechanizmu refleksji, oferuje również możliwość implementacji przetwarzania wielowarstwowego (rozumianego tutaj w kontekście baz danych). Oznacza to, że źródłem danych nie musi być koniecznie klasycznie rozumiana baza danych. Bezpośrednie korzystanie z zasobu bazy danych ma miejsce tylko w najbardziej elementarnym przypadku, gdzie np. OLE DB pobiera dane bezpośrednio z ODBC. W celu zachowania kompatybilności, scenariusz ten jest realizowany przy użyciu standardowego dostawcy danych (provider) w ramach OLEDB. W praktyce dostawcą danych może być dowolny komponent, implementujący odpowiedni zestaw interfejsów. Komponentem takim może być również komponent aplikacyjny realizujący specyficzne reguły przetwarzania.
Możliwość udostępniania usług w ramach protokołu obiektowego jest wymieniana jako główna cecha modelu opartego na komponentach świadcząca o jego przewadze nad dostępem poprzez sterowniki np. ODBC. W literaturze technicznej zestawienie tych dwóch metod jest określane jako konfrontacja modelu COM oraz WOSA (Window Open System Architecture oraz SPI). W modelu WOSA, opartym na sterownikach, system kooperacyjny nie ma dostępu do warstwy znajdującej się poniżej odwołań do interfejsu programisty. Inaczej jest w COM - komponenty mogą realizować zarówno funkcje części systemowej jak i aplikacyjnej. Dlatego też możliwe jest implementowanie reguł przetwarzania już na poziomie interfejsu dostępu do danych.
Powiązanie pomiędzy komponentem, który jest źródłem danych a komponentem z nich korzystającym traci dzięki architekturze obiektowej swój wyjątkowy status. Oznacza to, że projektowanie i implementacja połączeń staje się zadaniem programowania aplikacyjnego i może być elementem realizacji reguł przetwarzania lub operacyjnych własności systemu informatycznego.
85

Większość środowisk programistycznych obsługuje skalowalność rozwiązań, dostarczając w typowych sytuacjach mechanizmów standardowych. Komponent aplikacyjny implementujący proste reguły przetwarzania może być wygenerowany automatycznie przez środowisko. Odpowiednio zaprojektowane interfejsy i architektura tegoż środowiska umożliwia jednak programiście realizację niestandardowych mechanizmów funkcjonowania i adaptację dostępnych bibliotecznych komponentów stosownie do swoich potrzeb.
Zbliżoną do OLE DB funkcjonalność oraz ogólną ideę zawiera w sobie architektura MIDAS (Multitier Distributed Application Server). Jest ona oparta na modelu komponentowym. Komponenty wchodzące w skład systemu implementują standardowe interfejsy (przede wszystkim IProvider) – stanowiące podstawę warstwy komunikacyjnej. Godny uwagi jest fakt, że MIDAS jest niezależny od protokołu obiektowego. Będąc sam protokołem wyższego poziomu może korzystać zarówno z COM, CORBA jak i dwóch firmowych (niestandardowych) rozwiązań EnterpriseOLE oraz SocketSrv. To co wyróżnia MIDAS, to duża prostota posługiwania się tą architekturą i jej elastyczność pozwalające skupić się na implementacji reguł przetwarzania.
5.3. Dynamiczny interfejs IDispatch - RAW
Zarówno biblioteki typów jak i standaryzacja usług dostarczanych przez komponenty, ze szczególnym uwzględnieniem usługi dostępu do baz danych stanowi krok w kierunku realizacji mechanizmu refleksji w ramach protokołów obiektowych. Pewnym ograniczeniem funkcji dostępnych za pośrednictwem bibliotek typów może być ich statyczny charakter. Biblioteka raz utworzona nie zmienia w trakcie istnienia swojej struktury. Nic nie stoi jednak na przeszkodzie by „funkcje opisujące” interfejsu IDispatch modyfikowały swoją semantykę w trakcie działania.
Chociaż nie jest możliwe dynamiczne aktualizowanie zawartości biblioteki typów, to dzięki dynamicznemu interfejsowi IDispatch może być osiągnięte dalsze uelastycznienie działania OA. Komponent może dzięki temu dynamicznie zmieniać swój interfejs, umożliwiając jednocześnie „światu zewnętrznemu” rejestrowanie i analizę tych zmian. Jednym z zastosowań dynamicznego modelu interfejsu może być dalsze rozszerzenie architektury wielowarstwowej w kierunku lepszej obsługi mechanizmu refleksji. W kategoriach formalnych można strukturę obiektu uznać dzięki temu za jego stan, który jest opisywany przez pewne funkcje – funkcje poziomu meta realizujące również pewne reguły przetwarzania. Z uwagi na czysto techniczny aspekt tego zagadnienia opis formalny nie ma prawdopodobnie sensu. Niemniej należy zwrócić uwagę na fakt, że interfejs IDispatch jest zarazem meta interfejsem posiadającym możliwość udostępnienia systemowi swojego opisu. Właściwość ta stała się podstawą zaproponowanego rozwiązania – dynamicznego polimorfizmu.
86

Proponowane rozszerzenie polimorfizmu mieści się w drugim nurcie wspomnianych na początku rozdz. (5.3) tendencji rozwoju informatyki w zakresie przetwarzania dokumentów elektronicznych. Podstawową rolę gra tutaj niestandardowe użycie opisanego interfejsu IDispatch.
function TEDISegment.GetIDsOfNames(const IID: TGUID; Names: Pointer; NameCount, LocaleID: Integer; DispIDs: Pointer): Integer;Type POleNames=^TOleNames; TOleNames=array[0..0] of PWideChar;
PIDs=^TIDs; TIDs=array[0..0] of integer;Var NamesArr:POleNames absolute Names; DispArr:PIDs absolute DispIDs; MemberName:string;Begin MemberName:=UpperCase(WideCharToString(NamesArr^[0])); Result:=s_OK; if MemberName='ALPHA' then DispArr^[0]:=1 else if MemberName='BETA' then DispArr^[0]:=2 else begin DispArr^[0]:=-1; Result:=DISP_E_UNKNOWNNAME; end;end;
4.3 Implementacja odwzorowania identyfikatorów
Podobnie jak mechanizm funkcji wirtualnych w programowaniu obiektowym, IDispatch dostarcza pewnego jeszcze bardziej elastycznego mechanizmu opisu typu obiektu. Klasyczny polimorfizm, czyli metody wirtualne typu obiektowego oparty jest na zasadzie „późnego rozstrzygania” (late binding). Inaczej niż w przypadku metod statycznych (rozumianych jako przeciwieństwo metod wirtualnych), których identyfikatory zamieniane są na adresy w momencie kompilacji, adresy metod wirtualnych wyznaczone są na podstawie konkretnej instancji obiektu w czasie wykonania.
Formalnie można przyjąć, że adres metody wyznaczany jest za pomocą funkcji dwuargumentowej. W przypadku metody statycznej argumentami są klasa oraz identyfikator, natomiast w przypadku metody wirtualnej adres wyznaczany jest na podstawie obiektu i identyfikatora.
Metoda statyczna:
Metoda wirtualna:
87

Szczegóły techniczne realizacji tego mechanizmu można znaleźć w pracach poświęconych programowaniu obiektowemu.
Proponowane rozszerzenie polimorfizmu dla przetwarzania dokumentów polega na dopuszczeniu zmienności w czasie pierwszego argumentu funkcji f. Wynika stąd, że typ zmiennej obiektowej, który wyznaczany jest przez funkcję składową interfejsu IDispatch może być realizacją pewnych reguł przetwarzania. W szczególnym przypadku, opis typu może być oparty na wskaźnikowej strukturze danych, będącej reprezentacją formalnej definicji dokumentu.
Najprostszy przypadek funkcji odwzorowującej identyfikator składowej obiektu zawiera krótki fragment kodu w Delphi (4.3).
function TEDISegment.Invoke(DispID: Integer; const IID: TGUID; LocaleID: Integer; Flags: Word; var Params; VarResult, ExcepInfo, ArgErr: Pointer): Integer;Var ParamsArr: PvariantArgList absolute Params; ResVar:PVariantArg absolute VarResult;Begin Result:=S_OK; case DispID of 1:case Flags of DISPATCH_PROPERTYPUT:alpha:=ParamsArr^[0].lVal; DISPATCH_PROPERTYGET or DISPATCH_METHOD:with ResVar^ do begin vt:=VT_I4;lVal:=alpha; end; end; 2:case Flags of DISPATCH_PROPERTYPUT:beta:=ParamsArr^[0].dblVal; DISPATCH_PROPERTYGET or DISPATCH_METHOD:with ResVar^ do begin vt:=VT_R8;dblVal:=beta; end; end; else endend;
4.4 Implementacja wywołania OA
W przykładzie (4.3) obiekt ma dwa pola o identyfikatorach alpha i beta. Zadaniem metody GetIDsOfNames jest: po pierwsze sprawdzenie czy danemu identyfikatorowi programowemu odpowiada składowa obiektu, po drugie zaś, podanie identyfikatora logicznego związanego z daną składową. W praktyce nie ma żadnych ograniczeń co do algorytmów realizowanych przez tą metodę – możliwa jest też dynamiczna analiza pliku DTD mająca na celu zweryfikowanie naw i znalezienie elementów danych występujących w dokumencie.
Z tak zaprogramowaną metodą GetIDsOfNames musi współpracować odpowiednia metoda Invoke interfejsu IDispatch (rys. 4.4) odpowiedzialna za część operacyjną (inaczej niż GetIDS, która stanowi rodzaj deklaracji). Metoda Invoke powinna
88
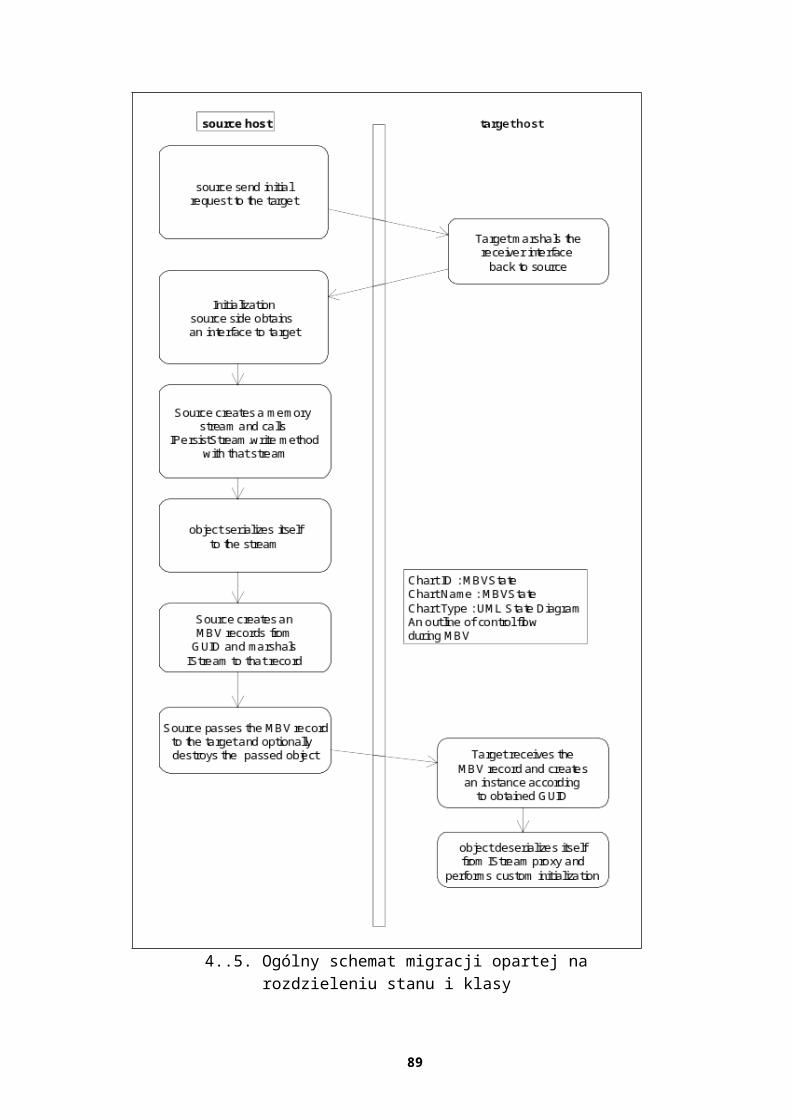
właściwie rozpoznawać identyfikatory logiczne i udostępniać kolejne składowe obiektu. Poniższy przykład ilustruje ten mechanizm.
Identyfikatory logiczne 1,2 odpowiadają składowym alpha i beta obiektu. Metoda Invoke obsługuje zarówno ustawianie jak i dostęp do wartości tych składowych. W ten sposób aplikacja ma dostęp do obiektu o dwóch składowych całkowitych bez konieczności deklarowania odpowiadającego im typu rekordowego. Co więcej bez konieczności rejestrowania w systemie operacyjnym komponentu.
Pełna swoboda w implementacji zarówno części deklaratywnej jak i operacyjnej komponentu opartego o dynamiczny polimorfizm umożliwia również redukcję pamięci zużytej na obiektową reprezentację dokumentu. Jak już wspomniano plik DTD może być w dynamiczny sposób analizowany podczas gdy aplikacja zgłasza kolejne zapytania dotyczące elementów wchodzących w skład dokumentu. Podobnie rzecz się ma w przypadku samego dokumentu. Jego analiza leksykalna i składniowa może być dokonywana dynamicznie, niejako na żądanie ze strony jednostki wywołującej.
Tak więc dzięki dynamicznemu polimorfizmowi, uzyskuje się wydajną i co najważniejsze elastyczną reprezentację obiektową, która łączy w sobie zalety modelu zdarzeniowego oraz obiektowego. Chociaż przedstawiona metoda może być stosowana w dowolnym środowisku programistycznym mającym interfejs do protokołu DCOM, to należy zauważyć, że najbardziej wydajnie może być ona wykorzystana w Delphi (uwaga dotyczy implementacji strony „konsumenta” informacji – sam dostawca może być implementowany w dowolnym środowisku, w którym można tworzyć komponenty). Związane jest z eleganckim sposobem obsługi typu variant, łączącym w sobie zalety języków interpretowanego i kompilowanego.
5.4. Dokumenty elektroniczne w architekturach wielowarstwowych
W obszarze przetwarzania dokumentów elektronicznych można zaobserwować dwie przeciwstawne tendencje. Z jednej strony widoczne są wysiłki różnych gremiów mających na celu wypracowanie standardowych formatów i postaci tychże dokumentów. Do tego nurtu można zaliczyć prace BOTF czy grupy ONZ odpowiedzialnej za standard EDI. Drugi nurt jest wynikiem intensywnego rozwoju możliwości samej informatyki, którego wynikiem jest dążenie do coraz większej elastyczności i otwartości systemów. Wynikiem tego jest rozwój mechanizmów refleksji (cytowany już wielokroć [Edmo]), umożliwiających automatyczne dostosowywanie się systemu informatycznego i aktywną analizę zmieniającego się otoczenia. Refleksja uznawana jest za podstawową własność kooperacyjnego systemu informatycznego.
89

Dokument niezależnie od tego czy rozumiany jest klasycznie (dokument papierowy) czy ogólnie (również dokument elektroniczny) w każdym przypadku jest zbiorem danych spełniającym pewne formalne wymogi. W dokumencie papierowym mogą być to pewne pola, rubryki czy też składowe związane z potwierdzeniem jego autentyczności. Autentyczność dokumentu klasycznego ustala się na podstawie pewnym zastrzeżonych elementów graficznych użytych przy jego sporządzaniu (pieczęcie, podpisy, symbole). Podobnie dokument elektroniczny jest plikiem sformatowanym w zgodzie z pewnym standardem (EDI, XML, SGML, HTML), którym może zostać elektronicznie podpisany poprzez zaszyfrowanie kluczem prywatnym.
Dokument można zdefiniować więc jako połączenie dwóch składowych: formatu oraz reprezentacji stanu. Format dokumentu klasycznego zawarty jest w formularzu, podczas gdy stanem dokumentu (jego instancją), jest zawartość poszczególnych rubryk. Format dokumentu elektronicznego może być również reprezentowany zarówno implicite jak i explicite. W pierwszym przypadku format określony jest przez reguły przetwarzania aplikacji obsługującej dany format, w drugim zaś istnieją pliki czy inne zasoby danych zawierające specyfikację tegoż formatu. Reprezentacja implicite jest typowa dla standardów określanych przez firmy (proprietary – np. MSOffice) nie wyklucza ona podania szczegółowego opisu formatu w celu umożliwienia odczytu i przetwarzanie plików przez oprogramowanie pochodzące od innych firm. Standardy mają postać jawnych plików, które same są dokumentami - jeżeli pochodzą od niezależnych gremiów. Tutaj jako przykład mogą posłużyć dokumenty EDI, czy XML – w pierwszym przypadku opis formatów zawarty jest w komunikacie DIRDEF (też w EDI), w drugim zaś występują tzw. pliki Definicji Typu Dokumentu (DTD). Przewagą drugiego podejścia jest otwarcie standardu na zmiany. Użytkownicy i twórcy oprogramowania mogą definiować własne rozszerzenia wewnątrz obszaru swojej jurysdykcji i ewentualnie zabiegać o uznanie ich na szerszym forum. Standard EDIFACT (EDI for Commerce Administration and Transportation) określa w jaki sposób propozycje rozszerzeń istniejących oraz zgłoszenia nowych dokumentów mogą być przedkładane do akceptacji.
Dokument będąc bytem pojęciowym odpowiednio wysokiego poziomu jest konstrukcją adekwatną do zastosowań zarówno w obrębie informatyki jak i opisu rzeczywistości przedmiotowej. Pojęcie dokumentu zmienia się w ramach systemu informatycznego stając się bardziej ogólnym. O tym czy jakaś struktura danych jest dokumentem decyduje fakt, czy jest ona zgodna z określeniem jakiegoś standardu. Może to być zarówno standard międzynarodowy, krajowy lub obowiązujący w ramach jednej firmy czy organizacji. Ta sama struktura danych czy plik może być w jednym kontekście dokumentem w innym zaś bezpostaciowym zasobem binarnym. Poszerzając w ten sposób znaczenie słowa dokument, można za takowy uznać nawet pewne obiekty nie mające swojej wizualnej postaci, takie jak np. obiekty protokołu DCOM.
90

W istocie, obiekt protokołu DCOM, którego trwały zapis ma postać pliku binarnego ujawnia w ramach protokołu swoją semantykę. Sam protokół określa jedynie dostęp do metod oraz własności obiektu. Interpretacja i semantyka danych udostępnionych poprzez interfejs obiektowy może być przedmiotem ustaleń standardów lub konwencji wyższego poziomu. Przykładem mogą być omawiane dalej zabiegi grupy BOTF w ramach protokołu CORBA mające na celu opracowanie standardowych dokumentów biznesowych. W obrębie protokołu DCOM funkcjonuje jako nieformalny standard tzw. DOM (Document Object Model), zapewniający programowy dostęp do dokumentów utworzonych przez aplikacje z rodziny MSOffice. Mechanizm ten jest również stosowany przez innych wytwórców oprogramowania (Micrografx).
Cechą charakterystyczną konwencjonalnych architektur aplikacji jest sprowadzenie roli dokumentów wyłącznie do zadań komunikacji z użytkownikiem. Dane przechowywane są w relacyjnych bazach danych, w oparciu o które generowane są różnego rodzaju czy zestawienia raporty. Baza relacyjna jest w stanie odwzorowywać hierarchiczne powiązania pomiędzy poszczególnymi składowymi dokumentu, niemniej na poziomie samego systemu dane zorganizowane są w postaci tabel, pól oraz zdefiniowane na nich klucze główne i obce oraz indeksy pomocnicze.
Relacyjne bazy danych mogą przechowywać dokumenty elektroniczne w postaci obiektów binarnych (pola BLOB). Dokument przechowywany w takiej postaci stanowi tzw. amorficzny (pozbawiony struktury zasób danych – dokładniej zaś pozbawiony struktury czytelnej dla samej aplikacji). W praktyce często spotyka się pliki utworzone poprzez inne aplikacje przechowywane w polach binarnych - np. metapliki graficzne, dokumenty WinWord, czy Excel. Dokumenty te nie zawierają żadnych danych, które mogłyby być przetwarzane przez samą aplikację. Ich zawartość staje się danymi dopiero w kontekście odpowiednich aplikacji, które je utworzyły.
Przetwarzanie tego typu jest nierozłącznie związane z architekturami monolitycznymi oraz architekturami klient-serwer. Poszczególne składowe wchodzące w skład takich aplikacji charakteryzują się bowiem dużym stopniem autonomiczności i brakiem zorientowania na przetwarzanie kooperacyjne – mogą bowiem funkcjonować wyłącznie w ramach jednego systemu. Prowadzi to do powstawania tzw. wysp automatyzacji [Brodie], [Bernd]. Organizacje tworzą systemy przetwarzania danych zorientowane na realizację ściśle określonych zadań. Jest jednak rzeczą oczywistą, że podobnie jak istnieje konieczność porozumiewania się między ludźmi, poszczególne autonomiczne systemy też muszą kooperować i wymieniać dane.
Wzrost znaczenia dokumentów elektronicznych jako mechanizmu komunikacji jest ściśle związany z pojawieniem się architektur wielowarstwowych oraz kooperacyjnych systemów informatycznych. Dzięki zastosowaniu obiektowych protokołów komunikacyjnych możliwe jest przetwarzanie binarnych plików utworzonych przez
91

inne aplikacje. Przykładowo wspominany protokół DCOM razem z obiektowym modelem dokumentu (DOM) zastosowanym w aplikacjach z grupy MSOffice oraz osadzonym w tych aplikacjach skryptowym językiem Visual Basic (VBA) są mechanizmem pozwalającym na manipulowanie zawartością tychże plików i na wyszukiwanie w nich informacji.
Kolejnym czynnikiem, który okazał się decydujący dla wzrostu rangi dokumentów elektronicznych było zagadnienie komunikacji B2B (Business To Business). O ile architektury wielowarstwowe były wynikiem pewnego ewolucyjnego procesu w ramach kształtowania się architektur oprogramowania, to przetwarzanie B2B pojawiło się jako wynik postulatów stawianych przez użytkowników systemów informatycznych. Konwencjonalne systemy, tworzące wspomniane już wyspy automatyzacji, nie były w stanie podołać zadaniom realizacji obiegu dokumentów w organizacjach i obsłudze ich wzajemnych powiązań. Bardzo często dochodziło do sytuacji, gdzie dokument wygenerowany przez jeden system informatyczny musiał być ponownie wprowadzany z konsoli do innego systemu. Drastycznym przykładem anomalii tego typu może być funkcjonowanie polskich urzędów celnych, gdzie niemal 100% dokumentów SAD dostarczanych jest w postaci wydruków, które następnie muszą być ręcznie wprowadzone do ewidencji.
Jedną z pierwszych prób rozwiązania problemu komunikacji pomiędzy autonomicznymi systemami informatycznymi była wzmiankowana już propozycja standardu EDIFact przez ONZ. Standard EDIFact jest zestawem formatów dokumentów, typów i segmentów danych oraz konwencji zapisu – służącym do generowania dokumentów elektronicznych, które mogą być tworzone, przetwarzane i rejestrowane niezależnie przez różne aplikacje. EDIfact oprócz definicji samych standardów dla dokumentów określa również metodykę prac na rozszerzeniami tego standardu.
EDIfact przyjął się wyłącznie w dużych firmach i organizacjach. Było to związane z dużymi kosztami wprowadzenia systemu oraz stanem informatyzacji mniejszych firm i organizacji w owym czasie. Obecnie popularniejsze od EDIFact są standardy SGML oraz stanowiący jego podzbiór XML. Sukces tych dwóch związany jest bez wątpienia z popularnością języka HTML stanowiącego podstawę publikowania danych w sieci Internet.
XML Język XML podstawę standardowego formatu dokumentu w Internecie. Inaczej niż HTML służący do tworzenia dokumentów przeznaczonych dla ludzi – XML może być użyty zarówno do formatowania tekstów jak i do prezentacji ich w postaci umożliwiającej automatyczną analizę. Dzięki temu dokument staje się „czytelny” zarówno dla użytkownika jak i dla samego systemu.
92

Podstawową zaletą XML jest jego elastyczność. Dwa typu dokumentów tworzone przy użyciu tego języka to:
- DTD (Document Type Definition) –definicja typu dokumentu,- XML konkretne dokumenty w samym języku, zgodne z pewną definicją typu.
W ten sposób liczba dostępnych typów dokumentów nie jest ograniczone przez standard. Pliki DTD stanowią swego rodzaju meta-dokumenty stanowiące opis struktury poszczególnych instancji dokumentów konkretnego typu. W standardzie EDIFact rolę meta-dokumentu stanowił specjalny komunikat DIRDEF, w którym zawarta była definicja całego standardu. Tak więc, język meta (metadane) oraz język przedmiotowy są w tym przypadku te same. Inaczej jest w XML – plik DTD nie jest zapisany w języku XML, ma on własny format oraz język zapisu.
Dokument w XML składa się z trzech elementów [Flynn]:
- definicji typu dokumentu ( DTD), - deklaracji typu dokumentu – odwołania do pewnej definicji typu,- zawartości dokumentu.
Zadaniem oprogramowania obsługującego XML jest m.in. badanie zgodności zawartości dokumentu z deklarowanym typem. Sam standard XML nie definiuje (w przeciwieństwie do EDIFact), określonych typów dokumentów. Dostarcza jedynie pewnego ogólnego mechanizmu oraz konwencji służących do ich tworzenia. Dlatego na bazie XML powstały liczne typy dokumentów – niektóre z nich doczekały się międzynarodowego uznania jako standard wymiany informacji.
Typy dokumentów XML można za [Flynn] podzielić na następujące grupy:
- dokumenty biurowe- korespondencję służbową- oficjalne noty- dokumenty standardowe dla poszczególnych branż
Co więcej istniejące standardy dokumentów elektronicznych takie jak rozpowszechniony EDIFact czy HL 7( health level 7) zostały włączone do XML jako zbiory standardowych typów.
5.5. Obiektowy model dokumentu
Sposobem udostępnienia dokumentu użytkownikowi jest jego wizualna reprezentacja. Może ona przyjąć postać wydruku lub może być dokonana przez odpowiednią przeglądarkę. Jeżeli dokument ma być również dostępny dla systemu informatycznego to musi istnieć interfejs programowy.
93

Podstawową kategorią oprogramowania służącego do obsługi dokumentów elektronicznych (oprócz przeglądarek) są parsery analizujące ich zgodność z formatem oraz przetwarzające je do postaci zrozumiałej dla aplikacji. Interfejs programowy parsera powinien umożliwić aplikacji odczytanie danych z dokumentu, ich ewentualną modyfikację czy też wygenerowanie nowego dokumentu.
W obszarze komunikacji warstwy oprogramowania aplikacyjnego z parserem języka XML wykrystalizowały się dwa konkurencyjne rozwiązania. Pierwsze on nazwie SAX (Simple API for XML) oparte jest na obsłudze zdarzeń generowanych przez wystąpienie określonych symboli syntaktycznych. Metoda ta przypomina sposób pracy parserów generowanych przez standardowe użytki UNIXA typu YACC, w których programista mógł kojarzyć akcje ze zmianą stanu parsera. Podobnie jest w SAX zmiana stanu powoduje wygenerowanie zdarzenia w efekcie czego wywołana jest akcja na poziomie aplikacji.
Mechanizm zdarzeniowy może być również z powodzeniem wykorzystany do generowania dokumentów. W tym przypadku aplikacja jest odpowiedzialna za sterowanie zmianami stanu interfejsu. Należy zauważyć, że żadna z obecnych implementacji SAX nie umożliwia jej wykorzystania w ten sposób. Niemniej autor dysponuje doświadczeniami zebranymi podczas implementacji parsera i generatora EDIfact przeznaczonego dla środowiska Delphi, na podstawie których stwierdzona została adekwatność modelu zdarzeniowego do generowania dokumentów.
Drugie rozwiązanie korzysta z obiektowej reprezentacji całego dokumentu. Podstawą reprezentacji obiektowej jest utworzenie na podstawie analizowanego dokumentu zbioru wzajemnie powiązanych obiektów – odzwierciedlających jego zawartość.
Najbardziej rozpowszechnionymi przykładami reprezentacji obiektowej mogą być modele MSOffice oraz dokumentów HTML – związane z językami Visual Basic oraz JavaScript. Umożliwiają one odczyt oraz manipulowanie zawartością dokumentów programom napisanym w językach obiektowych, mającym dostęp do np. protokołu DCOM. Obydwa modele definiują szereg typów obiektów odpowiedzialnych za reprezentowanie składowych dokumentów. Mogą to być odpowiednio dla np. arkusza: komórki, zakresy, atrybuty, wartości. Dla dokumentu HTML obiekty są związane z występującymi w tym języku znacznikami.
Reprezentacja obiektowa dokumentu, mimo że bardzo rozpowszechniona ma dwie zasadnicze wady. Po pierwsze ilość pamięci potrzebnej do przetwarzania dokumentu jest zależna od jego rozmiaru. Należy pamiętać, że dokumenty elektroniczne, które będą przetwarzane wyłącznie przez programy mogą nie podlegać ograniczeniom objętościowym, które obowiązywały w sytuacji gdy rozmiar dokumentu musiał być możliwy do „ogarnięcia” przez użytkownika. Drugim ograniczeniem jest statyczny
94

charakter deklaracji typów. Reprezentacja obiektowa zakłada pewien znany z góry zestaw składowych występujących w dokumencie. Temu statycznemu zestawowi odpowiada pewna ilość zadeklarowanych typów obiektowych – np. klas obiektów protokołu DCOM.
Pierwszy mankament dostępu obiektowego ma charakter wyłącznie ilościowy. Druga z tych wad wydaje się być poważniejsza, zwłaszcza w kontekście języków SGML oraz XML, które zakładają elastyczność jeśli chodzi o typy dokumentów i występujących w nich składowych. O tym że jest to pewne wyzwanie dla programistów można się przekonać analizując dostępne obecnie rozwiązania. Zagadnienie reprezentacji typów nastręcza trudności również w przypadku „statycznych” zbiorów formatów takich jak EDIFact – proces instalacji jednego z parserów obejmuje rejestrację kilkudziesięciu klas obiektów DCOM. Oryginalna propozycja rozwiązania tego problemu zostanie przedstawiona w rozdz. (5.3). Co więcej, okaże się, że możliwe jest rozwiązanie problemu dużego zapotrzebowania na pamięć dla obiektowej reprezentacji obszernych dokumentów.
Biblioteki typów DCOM, automatyzacja OLE Ponieważ zarówno definicja typu dokumentu (DTD) jak i biblioteka typu w protokole DCOM są statycznymi plikami, nic nie stoi na przeszkodzie by jedną postać metadanych tłumaczyć na drugą. W ten sposób, standardowym typom dokumentów określonych w skali międzynarodowej czy też w ramach pewnej organizacji mogą odpowiadać biblioteki typów – stanowiąc podstawę obiektowego interfejsu dostępu. Istotnie, z uwagi na czysto mechaniczny charakter procesu tego typu, tłumaczenie DTD na Type Library może być wykonywane przez program. Autor brał udział w pracach implementacyjnych nad oprogramowaniem tworzącym biblioteki typów DCOM na podstawie plików DTD.
95

6. Identyfikacja komponentów
Monolityczna infrastruktura warstwy pośredniczącej, narzucając gotowy schemat aplikacji i dostarczając standardowych usług, uwalnia (przynajmniej częściowo) od zadań związanych z ustaleniem postaci składowych (komponentów). W infrastrukturze takiej są określone funkcje ułatwiające uzyskanie pożądanych własności operacyjnych. Z kolei, większa swoboda i elastyczność architektury zorientowanej na konkretną aplikację, jest związana z koniecznością poniesienia pewnego nakładu, związanego z:
- dokonaniem samodzielnej dekompozycji (lub syntezy) komponentów,- przypisaniem poszczególnym komponentom własności operacyjnych,- określeniem ogólnych usług w postaci komponentów systemowych.
Należy zauważyć, że w pewnych przypadkach powyższa analiza (zwłaszcza ostatni jej punkt) może doprowadzić do wniosku, że celowe jest jednak zastosowanie infrastruktury gotowej. W przypadku, gdy zestaw zidentyfikowanych funkcji systemowych pokrywa się z własnościami pewnej infrastruktury prefabrykowanej a zakładane pozostałe funkcje nie są z nią sprzeczne – poniesiony na analizę nakład zwróci się w postaci optymalnie dokonanego wyboru.
W proponowanym w pracy odejściu od prefabrykowanych architektur potrzebna jest metoda ułatwiająca przejście od specyfikacji na poziomie funkcji aplikacyjnych oraz wymaganych własności operacyjnych do poziomu technicznego, na którym zostaną określone komponenty, serwery aplikacji oraz ich funkcje operacyjne wraz z podaniem ich fizycznej lokalizacji. Fizyczna lokalizacja dotyczy komponentów, które nie są mobilne. Niemniej należy podjąć decyzję, które składowe mają być mobilne a które statyczne. W tym miejscu należy zauważyć, że specyfikacja logiki przetwarzania (np. graf DFD) abstrahuje od kwestii implementacyjnych. Diagram przepływu danych jest jedynie specyfikacją na poziomie reguł przetwarzania i jest neutralny co do zagadnień architektonicznych. Co więcej nie zawiera w sobie specyfikacji własności operacyjnych aplikacji.
Zaproponowana w tym rozdziale kombinatoryczna metoda wyznacza klasy równoważności wierzchołków w grafie zależności (np. w diagramie DFD). Nieformalnie można wprowadzone klasy określić następująco: wierzchołki są równoważne, jeżeli wszystkie ścieżki przetwarzania (np. drogi w DFD) przez nie przechodzące są też równoważne (w sensie wchodzących w ich skład wierzchołków). Przynależność wierzchołków diagramu do jednej klasy jest wskazaniem za umieszczeniem odpowiadających im funkcji aplikacyjnych w jednym komponencie lub serwerze aplikacji.
Można wymienić następujące korzystne własności tak określonej relacji:
96

- możliwość korzystania ze stanu przechowywanego lokalnie przez funkcje należące do jednej klasy (zgrupowane w jednym komponencie) – czyli optymalizacja pozyskiwania danych otoczenia;
- zmniejszenie stopnia skomplikowania struktury (mniejsza liczba składowych);- minimalizacja liczby połączeń (istotne jeśli aplikacja ma obsługiwać refleksję, w
postaci, która zakłada utrzymywanie struktury danych modelującej aktualny stan aplikacji por. OpenDCOM [Coulson]);
- ułatwienie znajdowania optymalnej lokalizacji, gdyż równoważne funkcje aplikacyjne mają ją tą samą, gdyż jest ona uwarunkowana udostępnianymi przez nie usługami i wykorzystywanymi zasobami;
- wykrywanie funkcji nadmiarowych (duplikatów lub rozszerzeń).
Używane dotychczas metody automatycznej analizy diagramów zależności (np. [Pintado, Jones97, Jones97a]) opierają się raczej na wyznaczaniu arbitralnych metryk. Metryki te mają na celu określenie jakości danego schematu i przyjmują najczęściej postać funkcji wymiernej (ilorazu dwóch wielomianów). Licznik takiej funkcji jest wówczas proporcjonalny do „pożądanych” własności schematu (np. jego spójności), natomiast mianownik reprezentuje własności „negatywne”. Istotną wadą metod tego typu jest brak możliwości automatycznej transformacji diagramu w postać optymalną (zgodnie z przyjętą metryką). Metody te służą jedynie do oceny i porównywania równoważnych schematów.
Będący punktem wyjścia dla zaproponowanej metody kombinatorycznej diagram przepływu danych może być postrzegany jako abstrakcyjne przedstawienie reguł przetwarzania (logiki systemu). Abstrakcyjny – czyli również neutralny wobec wspomnianych już zagadnień implementacyjnych. Podstawowym zadaniem modelu abstrakcyjnego jest identyfikacja pewnych istotnych cech przy jednoczesnym pominięciu szczegółów mniej lub bardziej oczywistych – milcząco zakładanych. Przedstawienie rzeczywistości w postaci pojęć abstrakcyjnych umożliwia znaczne skrócenie opisu tejże, jego uprecyzyjnienie. (rzeczywistość – elementy wspólne dla postrzegających – np. dla programisty, użytkownika, menedżera). Istotne jest, że opis rzeczywistości w kategoriach pojęć abstrakcyjnych poddaje się formalnej analizie w obrębie odpowiedniej teorii. Przykładem takiego opisu mogą być formuły matematyczne, wzory czy twierdzenia.
Wychodząc od pewnej relacji równoważności określonej na wierzchołkach składowych grafu modelu można, korzystając z odpowiednich algorytmów wyznaczyć relację nasyconą, będącą największą partycją [Watson, Hopcroft], opartą na wyjściowym modelu. W ten sposób wyznaczone zostaną wierzchołki wzajemnie równoważne. Funkcje modelowanego systemu zawarte w jednej klasie abstrakcji mogą zostać połączone w komponent. Komponent ten wchodzi z kolei w skład pewnego serwera aplikacji.
97

6.1 Diagram zasobów, stacji roboczych oraz powiązań między funkcjami aplikacyjnymi
f5f1
f7f6f2 f8
f3
f4
C1
C4
C3
C2
Wks1
Wks2
Wks3
R2
R1
6.2 Funkcje z rys 6.1 dekomponowane na warstwy
Prezentowana metoda identyfikacji komponentów jest na tyle ogólna, że może znaleźć zastosowanie również do celów analizy schematów organizacyjnych czy przepływu danych. W szczególności może ona posłużyć do eliminowania jednostek organizacyjnych dublujących swoje kompetencje. Uzyskana z ten sposób „racjonalizacja” wykorzystania zasobów może prowadzić do zmniejszenia (przykładowo) zatrudnienia i ponoszonych nakładów, zwiększając efektywność wykorzystania dostępnych zasobów.
Pierwotnym zamysłem, podczas prac na metodą identyfikacji był wykorzystanie jej do celów badanie izomorfizmów grafów. Istotnie, metoda znajduje pewne przybliżenie relacji równoważności generowanej przez grupę automorfizmów grafu (ew. też innego obiektu kombinatorycznego). Wiele metod badania izomorfizmów grafu korzysta z wyników teorii grup. Co więcej najbardziej znany obecnie pakiet Nauty oparty jest na
98

przeszukiwaniu tzw. orbit, czyli klas abstrakcji wspomnianej relacji równoważności opartej na automorfizmie [Fortin].
Przedstawiony w pracy algorytm znajduje tylko pewne przybliżenie , w którym zawarty jest właściwy zbiór orbit. Określone zostały własności tego przybliżenia dla szczególnych typów grafów (Rn,Kn,Kr,s itp). Co więcej, z uwagi na wspomniany już ogólny charakter prezentowanego algorytmu (względem relacji wyjściowej) sformułowana została hipoteza co do możliwości zastosowania liczby i rozmiaru ścian grafu (cykli) jako uogólnienia stopnia wierzchołka jako relacji wyjściowej.
6.1. Specyfikacja reguł przetwarzania DFD, UML
Opis abstrakcyjny nazywany bywa modelem rzeczywistości, natomiast proces tworzenia tego opisu modelowaniem. Modelowanie zakłada istnienie pewnego systemu pojęć abstrakcyjnych. Każdy byt rzeczywisty powinien dać się odwzorować w odpowiadającą mu abstrakcję. Należy też pamiętać, że abstrakcja jest pojęciem względnym. Jedno pojęcie może być bardziej ogólne od drugiego. Relacja konkret-abstrakcja może być rozumiana jako pewnego rodzaju relacja porządkująca (zwrotna, przechodnia i anty-symetryczna) Ta ważna własność jest podstawą hierarchii w tworzonych opisach abstrakcyjnych.
W obrębie informatyki znaczenie abstrakcji zaczęto doceniać wraz ze wzrostem stopnia skomplikowania realizowanych projektów. Pierwszym krokiem było powstanie symbolicznych języków programowania. W tym przypadku język maszynowy można uważać za konkret, zaś kod symboliczny za opis w kategoriach abstrakcyjnych. Ważne było pojawienie się języków obiektowych, które dzięki mechanizmowi dziedziczenia oraz wzorców obsługiwały wspomnianą relację abstrakcja-konkret.
Dalszym krokiem na drodze wykorzystywania abstrakcji było pojawienia się języków, formalizmów oraz konwencji służących do modelowania systemów informatycznych. Przykładami tychże są OMT (Object Modelling Technique)[Rumb], OOSE (Object Oriented Software Engineering)[Jacob], E-R (Entity –Relationship), OOA/OOD. Wszystkie wymienione metody definiowały pewien formalny język. Na ten język składały się pojęcia czyli słownik oraz reguły tworzenia modeli przy użyciu dostępnych elementów. Każda z wymienionych metod była zorientowana na określone środowisko implementacyjne (obiektowy język programowania lub relacyjną bazę danych). Wynikiem połączenia wysiłków twórców metod modelowania było powstanie uniwersalnego języka modelowania UML.
99

Model procesu, systemu informatycznego czy też innego bytu poddawanego modelowaniu powinien spełniać określone wymagania. Cechy charakteryzujące model można przedstawić w następujących punktach [Erik]:
- dokładność i jednoznaczność – model powinien precyzyjnie opisywać projektowany system
- spójność – poszczególne składowe modelu powinny być wzajemnie niesprzeczne- przejrzystość – model powinien być zrozumiały dla wszystkich uczestników
projektu, powinien umożliwiać wymianę informacji między nimi oraz zgłaszanie uwag do poszczególnych jego fragmentów
- modyfikowalność – model może przechodzić prze wiele faz rozwojowych w trakcie których jego składowe podlegają zmianom; zmiany pojedynczych składowych nie mogą naruszać spójności całego modelu
- zrozumiałość - model powinien być łatwy do ogarnięcia oraz zrozumienia; dzięki swojej zhierarchizowanej strukturze powinien dawać możliwość szybkiego zaznajomienia się z ogólnymi własnościami systemu bez konieczności wnikania w jego szczegóły.
Model stworzony w obrębie pewnej konwencji, przy użyciu określonego w jej ramach zestawu pojęć powinien umożliwiać implementację projektowanego systemu. W najlepszym przypadku implementacja powinna odbywać się w sposób zautomatyzowany, wymagający jak najmniejszej ingerencji ze strony czynnika ludzkiego. Implementacja może też być rozumiana bardziej ogólnie - jako proces odwrotny do abstrakcji. Jest ona ukonkretnianiem modelu. Jej wynikiem nie musi być od razu system docelowy. W zhierarchizowanym układzie modeli implementacją modelu bardziej abstrakcyjnego może być model konkretny. Przykładem hierarchii abstrakcja-konkret są modele konceptualny, fizyczny oraz konkretna baza danych – obecne w narzędziach opartych na modelu obiektowo-związkowym.
Model w ramach pewnego systemu formalnego może być przeznaczony nie tylko dla uczestniczących w projekcie ludzi. Jeżeli dany model może być interpretowany automatycznie, to istnieje również możliwość jego przetwarzania. Przedstawienie modelu w kategoriach pewnego systemu formalnego ma w związku z tym następujące zalety:
- model jest jednoznaczny, ponieważ system formalny opisuje jednoznacznie semantykę poszczególnych pojęć abstrakcyjnych,
- możliwa jest formalna analiza własności modelu, gdyż formalizm umożliwia dodawanie nowych ograniczeń aksjomatów i automatyczną kontrolę poprawności modelu i jego zgodności z przyjętymi założeniami,
- co najważniejsze, możliwe jest automatyczne przetwarzanie modelu, jego optymalizacja w oparciu o założone kryteria.
100

Ostatnia z wymienionych własności jest podstawą prezentowanej w tym rozdziale metody identyfikacji komponentów.
Tworzone ad–hoc infrastruktury dla aplikacji wielowarstwowych stawiają szczególne wymagania, jeśli chodzi o specyfikację i modelowanie systemu. Każdy komponent w architekturze musi realizować aplikacyjne reguły przetwarzania oraz spełniać odpowiednie wymogi operacyjne – reprezentujące własności i wymogi środowiska implementacji. Niemniej punktem wyjścia w tworzeniu modelu systemu jest określenie realizowanych funkcji.
Komponent jest bytem programowym zgodnym z pewnym środowiskiem czasu wykonania (np. protokołem obiektowym czy serwerem transakcyjnym). Tak więc określenie czy dany obiekt jest komponentem ma sens tylko w obrębie pewnego środowiska operacyjnego. Komponent pod względem operacyjnym może wykazywać pewne szczególne własności, na podstawie których może być jeszcze dokładniej sklasyfikowany. Przykładowo, jeżeli może zmieniać węzeł sieci, na którym jest wykonywany jest on agentem mobilnym - a więc określenie poprzez własności operacyjne.
Istotne jest rozróżnienie pojęcia obiektu, które występuje zarówno w definicji komponentu oraz rozumianego jako pewna abstrakcja modelowanej rzeczywistości. Obiekt jest w tym przypadku używany w różnych kontekstach. W jednym i drugim przypadku modeluje on pewną rzeczywistość. W pierwszym przypadku dotyczy to rzeczywistości systemu wykonawczego w drugim zaś przedmiotowego.
Model systemu przedstawiony w kategoriach realizowanych zadań nie określa składowych komponentów systemu wielowarstwowego. Model ten zawiera jedynie odwzorowania pewnych obiektów świata rzeczywistego. Opisuje on zależności pomiędzy nimi. Ma on strukturę zaetykietowanego grafu. W modelu występują obiekty realizujące funkcje przetwarzania, zasoby danych oraz dostawcy usług. Elementy te stanowią wierzchołki grafu, natomiast zależności między nimi są modelowane krawędziami. Obydwu składowym grafu (krawędzie i wierzchołki) mogą być przypisane etykiety.
Również zdobywający sobie coraz większą popularność UML jest językiem graficznym. Większość typów diagramów wchodzących w jego skład ma postać zaetykietowanego grafu. Dzięki mechanizmowi tzw. stereotypów możliwe jest rozszerzanie semantyki UML. Stereotypy stanowią pewien zbiór dodatkowych identyfikatorów i reprezentują własności operacyjne nie wchodzące w skład podstawowego UML. Na zbiorze etykiet (np. stereotypów) można określić relację równoważności. W skrajnym przypadku stereotypy mogą tworzyć przeliczalną kratę.
101

Podobnie jak w przypadku diagramów DFD, również grafy pochodzące z UML mogą być przedmiotem algorytmicznej analizy.
6.2. Funkcje charakterystyczne, multizbiory
Relacja określająca czy dany element należy do zbioru może być określona za pomocą funkcji charakterystycznej. Funkcja charakterystyczna przynależności elementu do zbioru ma przeciwdziedzinę będącą zbiorem {0,1}. Z tak określonego zbioru wartości funkcji wynika natychmiast, że zbiór potęgowy zadanej dziedziny X ma rozmiar 2|X| Formalnie funkcja definiowana jest w następujący sposób. [Rasi], [Kurat]
(6.3)
Dla elementów należących do zbioru funkcja przyjmuje wartość 1, w przeciwnym przypadku 0.
Często używane pojęcie multizbioru jest uogólnieniem zbioru, w którym dopuszcza się występowanie elementów identycznych. Ściśle rzecz biorąc multizbiór jest zbiorem ciągów skończonych, tzn. odwzorowań z N do zbioru.
(6.4)
Przeciwdziedziną funkcji może być cały zbiór liczb naturalnych lub jego podzbiór – w tym również podzbiór skończony. Moc multizbioru potęgowego: w przypadku funkcji mającej jako przeciwdziedzinę cały zbiór liczb naturalnych nie można mówić o liczbie elementów, natomiast moc określa się symbolem N|X|. Dla przeciwdziedziny będącej zbiorem skończonym jest oczywiście n|X|.
Relacja równoważności, klasy abstrakcji
Pojęcie relacji równoważności będzie w dalszym ciągu prezentowanych rozważań będzie odgrywało fundamentalne rolę. Dlatego pojęcie to zostanie szerzej omówione w kontekście prezentowanych wyników.
Definicja (6.5)
Dla zbioru M i relacji , nazywamy relacją równoważności jeżeli spełnione są następujące warunki dla każdych a,b,c należących do M [Lidl].
(1) a a
(2) a b b a
(3) a b b c a c
102

Powyższe warunki oznaczają, że relacja jest zwrotna, symetryczna i przechodnia. Na podstawie relacji równoważności można zdefiniować klasy abstrakcji, będące zbiorami elementów równoważnych. Zbiory te są parami rozłączne, a ich suma tworzy dziedzinę relacji równoważności. Dowolny element należący do klasy abstrakcji określany jest jako jej reprezentant.
Definicja (6.6)
Relacja równoważności dzieli zbiór M na klasy równoważności, które są niepuste parami rozłączne a ich suma mnogościowa jest równa M. [Lidl].
Relacja równoważności i klasy równoważności są z sobą powiązane. Każdej relacji równoważności odpowiada podział zbioru na klasy i odwrotnie, klasie równoważności odpowiada relacja równoważności. Z klasami abstrakcji powiązane jest jeszcze jedno pojęcie – mianowicie układ reprezentantów
Definicja [Lidl] (6.7)
Układem reprezentantów jest podzbiór zbioru M zawierający dokładnie po jednym elemencie z każdej klasy równoważności. Wzajemna odpowiedniość między klasami abstrakcji a relacją równoważności jest przedmiotem prostego twierdzenia [Lidl]. Klasę równoważności elementu b oznacza się jako [b].
Twierdzenie [Lidl] (6.8)
Twierdzenie o klasach równoważności:
(1) a[b] a b
(2) [a]=[b] a b
(3) każdy element zbioru M należy co najmniej do jednej klasy abstrakcji
(4) każdy element zbioru M należy do co najwyżej jednej klasy abstrakcji
Dowód tego prostego twierdzenia można znaleźć w [Lidl]. Wnioskiem z (3) i (4) w jest, że element zbioru M należy do dokładnie jednej klasy abstrakcji. Przykładem klasy abstrakcji jest równoważność cykliczna ciągów na zadanym alfabetem. Rozważanie nad własnościami relacji równoważności mogą prowadzić do interesujących wyników z dziedziny np. teorii liczb. Zobaczmy jak analiza złożoności obliczeniowej algorytmu generowania reprezentowania klas abstrakcji nad ciągami nad zadanym alfabetem prowadzi do twierdzeń Gegenbauera, MacMahona, Redey’i i uogólnionego twierdzenia Fermata.
Wyznaczanie reprezentantów klas abstrakcji
103

Przykładowy zbiór reprezentantów klas abstrakcji relacji równoważności określonej przez (6.9) może stanowić zbiór najmniejszych (leksykograficznie) elementów tej klasy [Knuth].
( )A a a A A a a a an i i n i1 1 2 2 1 1 (6.9)
Dla symboli S={0,1} otrzymujemy zbiór reprezentantów (6.10), który jest wynikiem działania algorytmu (6.11).
000000000001000011000101000111001001001011001101001111010101010111011011011111111111
(6.10)
Oryginalny algorytm (6.11) jest oparty na znajdowaniu następników nieredukowalnych prefiksów ciągu nad zadanym alfabetem. Danymi wejściowymi są liczba symboli alfabetu (zmienna nBase) oraz długość ciągu (zmienna nActLength) Analiza ilościowa ciągu reprezentantów klas prowadzi do formuły (6.12). Formuła ta jest jedną z postaci uogólnionego twierdzenia Fermata. Dokładniej, poszukiwane są ciągi mające dokładnie n równoważnych postaci cyklicznych. while true do begin repeati:=nActLength; while a[i]=nBase do begin Dec(i); if i=0 then goto 9999; end; Inc(a[i]);
NPrefix:=i; for i:=nPrefix+1 to nActLength do a[i]:=a[(i-nPrefix-1) mod nPrefix+1];
until (nActLength mod nPrefix)=0;
end; 9999:
6.11 Algorytm wyznaczający reprezentantów klas równoważności względem postaci cyklicznej
Symbol występujący w formule (6.12) to funkcja Möbiusa. Pozostałe symbole: a,n to dowolne liczby naturalne Sumowanie odbywa się po wszystkich dzielnikach d liczby n. Należy zauważyć, że jeśli n jest liczbą pierwszą, to są tylko dwa dzielniki (n oraz 1) i wzór (6.12) przybiera postać małego twierdzenia Fermata. Dowód twierdzenia można znaleźć też u Knutha [Knuth]. Wyprowadzony tam jest metodą kombinatoryczną wzór MacMahona. We wzorze MacMahona na miejscu funkcji Möbiusa występuje funkcja
104

Eulera. Najbardziej ogólną postać tego twierdzenia podał Gegenbauer . Jego dowód oparty jest na własnościach funkcji multiplikatywnych.
(6.12)
6.3. Multizbiór klas abstrakcji wierzchołków grafu
W oparciu o przedstawione definicje wprowadzone zostanie pojęcie multizbioru na klasach abstrakcji. Można założyć, że na zbiorze wierzchołków grafu nieskierowanego G={V,E} określona została relacja równoważności, i co za tym idzie podział zbioru wierzchołków na klasy abstrakcji. Multizbiór, którego elementami są klasy abstrakcji można określić podając funkcję charakterystyczną tego multizbioru. W tym przypadku ma ona postać (6.13)
(6.13)
Przykładowy graf z 5 wierzchołkami i 3 klasami równoważności (6.14):
V1
V2
V3
V4
V5K1
K3
K2 (6.14)
Wartości funkcji dla multizbioru M(v4) i klas K1, K2, K3 grafu (6.14):
105

W przedstawionym przykładzie multizbiór dla wierzchołka v4 ma postać . Jest tak ponieważ, multizbiór przyporządkowany wierzchołkowi v
zawiera klasę K krotności n, jeżeli n wierzchołków tej klasy jest połączonych krawędziami z tym wierzchołkiem.
Tak więc K oznacza klasę abstrakcji wierzchołków grafu G, natomiast v oznacza wierzchołek tego grafu. Każdemu wierzchołkowi zostanie przypisany multizbiór klas abstrakcji określony funkcją charakterystyczną. Funkcję tę można też uznać za definicję pewnej innej funkcji przypisujące każdemu wierzchołkowi grafu wspomniany multizbiór klas równoważności.
(6.15)
Dziedzinę, przeciwdziedzinę tej funkcji opisuje formalnie (6.15). Istotne jest też, że symbol funkcyjny f opatrzony jest indeksem symbolu relacyjnego, gdyż relacja ta daje asumpt do zdefiniowania f. Oznacza to, że funkcja jest definiowana w kontekście pewnej (dowolnej) relacji równoważności określonej na wierzchołkach grafu.
W oparciu o tak zdefiniowaną funkcję można wprowadzić ciąg relacji równoważności na wierzchołkach grafu. Ma on postać rekurencyjną:
(6.16)
Słownie relację tę można określić w następujący sposób: dwa wierzchołki są n
równoważne, jeżeli są n-1 równoważne oraz multizbiory odpowiadające tym wierzchołkom są sobie równe. Relacją wyjściową 0 – może być jakaś dowolnie przyjęta relacja - np. wzgl. stopnia wierzchołka.
Definicja rekurencyjna pozwala zdefiniować następnik relacji:
(6.17)
Spostrzeżenie (6.18)
Następnik relacji równoważności, jest relacją równoważności.
Dowód
Wystarczy w oparciu o definicję (6.16) sprawdzić, że spełnione są warunki (6.5).
Dalej zostanie wprowadzony punkt stały (a takowy istnieje (6.21)), określony jak następuje:
(6.19)
106

Ostatnią definicją wprowadzoną w tej grupy będzie operator punktu stałego, w oparciu o który zostanie sformułowane twierdzenie o zbieżności.
(6.20)
Operator ten dla dowolnego grafu G i dowolnej relacji równoważności określonej na wierzchołkach tego grafu wyznacza punkt stały.
Nie jest sprawą oczywistą, że dla każdej relacji wyjściowej i każdego grafu można znaleźć relację nasyconą spełniającą warunek (6.20). Istnienie tej relacji jest treścią twierdzenia:
Twierdzenie (6.21)
Dla każdej relacji wyjściowej 0 istnieje punkt stały s spełniająca następujący warunek:
(6.22)Dowód
Z definicji rekurencyjnej wynika że:
(6.23)
Ponadto relacja identyczności pełni dla operatora następnika rolę stabilizatora:
(6.24)
Dziedzina relacji jest skończona, dlatego w każdym przypadku można uzyskać w skończonej liczbie kroków taki następnik, że jest spełnione:
(6.25)
6.4. Grupy automorfizmów grafu
Podana zostanie teraz definicja relacji równoważności w grafie względem stopnia wierzchołka [Niever]:
(6.26)
Z kolei równoważność indukowaną przez grupę automorfizmów grafu określa się mianem orbity [Sacz]. Dwa wierzchołki są równoważne jeżeli w grupie istnieje automorfizm odwzorowujący te wierzchołki.
(6.27)
Orbita dla automorfizmów grafu G będzie oznaczona jako .
Relacja (6.26) jest nadzbiorem orbity, co można zapisać jako:
107

(6.28)
Z tego powodu, relacja (6.26) jest szeroko wykorzystywana w algorytmach badania izomorfizmu grafów, względnie grupy automorfizmu. Praca [Niever] zawiera przykład takiego algorytmu (dla izomorfizmu). Ponieważ relacja 0 występuje w charakterze górnego ograniczenia zbioru poszukiwań, korzystne jest znalezienie najmniejszej relacji spełniającej warunek (6.28).
Istnieje związek pomiędzy punktem stałym (6.20), a relacją równoważności indukowaną przez grupę automorfizmów grafu. Operacja następnika zachowuje własność następnik jest nadal nadzbiorem orbity. Związek wyraża:
Twierdzenie (6.29)
Dowód
Wystarczy zauważyć, że operacja następnika (6.19) zachowuje automorfizm (gdyż funkcja f jest oparta na przyległości wierzchołków). Można to wyrazić formalnie w następujący sposób:
Ponieważ punkt stały s powstaje na skutek wykonania skończonej ilości wzmiankowanej operacji, zachowuje ona automorfizm.
Twierdzenie (6.29) nie czyni żadnych założeń odnośnie grafu G. Okazuje się, że dla pewnych grafów o szczególnych własnościach można w prosty sposób dokładniej określić zależność pomiędzy punktem stałym a orbitami. Dalej można określić tę zależność dla następujących typów grafów:
graf pełny Kn,
cykl Cn,
graf regularny Rn,
pełny graf dwudzielny Kr,s,
drzewo Tn.
Własności te jako oczywiste zostaną podane bez dowodów. Przedstawione dalej określenie tej zależności dla drzew ma charakter twierdzenia (6.34). Użyty w formułach (6.30)-(6.33) symbol relacyjny 0 odnosi się w dalszym ciągu do definicji (6.26)
108

(6.30)
(6.31)
(6.32)
(6.33)
Przy czym jest:
Własność (6.31) określa najbardziej niekorzystną cechę punktu stałego opartej na (6.26). Dla grafów regularnych jest ona całkowicie nieprzydatna. Dlatego dalej podjęto próbę zbadania innych wyjściowych relacji równoważności (rozdz. 6.5).
Twierdzenie (6.34)
Twierdzenie o relacji punktu stałego
Definicja równoważności ścieżek (ab oznacza ścieżkę między wierzchołkami a i b):
(6.35)
W dalszych rozważaniach ważną rolę odegra lemat o równoważności ścieżek długości n w grafie G. Głosi on, że jeżeli wierzchołki są połączone
ścieżką długości n do dla każdej pary wierzchołków s równoważnych z końcami tej ścieżki istnieje ścieżka długości n równoważna ze ścieżką
względem relacji s, gdzie n jest s=n.
Lemat (6.36)
Dowód
(indukcyjny)
(1) Dla n=0 lemat jest spełniony w sposób oczywisty , przy czym jako droga długości 0 rozumiana jest tutaj droga złożoną z jednego wierzchołka.
109

(2) Teraz należy rozpatrzyć przypadek:
dla ścieżki długości n-1 lemat jest spełniony na mocy założenia indukcyjnego. Dla wierzchołków b,d G , spełniających bsd, na mocy definicji (6.16) jest:
Niech {b,u}a,b, w takim razie istnieją wierzchołki, że (tzn. u należy
do klasy równoważności, która z kolei należy do multizbioru przyporządkowanemu wierzchołkowi b) oraz, , takie że - rys.(6.37). Z założenia
indukcyjnego wynika, że muszą istnieć ścieżki długości n-1 między wierzchołkami a, u oraz b, v. Wynika stąd, że istnieje ścieżka c, d długości n, równoważna ścieżce ab, składająca się z mającej długość n-1 ścieżki cv oraz krawędzi {v,d}.
a
cd
b
...
...
u
v
b s d
(6.37)
Na podstawie lematu można sformułować twierdzenie o własności relacji punktu stałego s.
Twierdzenie (6.38)
Dowód
Powyższe twierdzenie wynika natychmiast z lematu (6.21), oraz definicji punktu stałego (6.17). Ponieważ następnik punktu stałego jest równy poprzednikowi równoważność dotyczy ścieżek dowolnej długości.
110

Należy zauważyć, że do wyznaczania relacji punktu stałego można wykorzystać ogólny schemat algorytm minimalizacji automatu skończonego. Zadanie minimalizacji bywa też sprowadzane do kwestii znajdowania największej partycji zgodnej z odwzorowaniami wewnętrznymi oraz partycją wyjściową. W przypadku relacji będącej punktem stałym odpowiednikiem partycji wyjściowej są klasy abstrakcji relacji podstawowej (rozważane w rozprawie relacje oparte na liczbie fasetowej oraz stopniu wierzchołka), natomiast odwzorowaniu odpowiadają multizbiory, czyli funkcja (6.15), na klasach równoważności, zgodne z krawędziami grafu.
W ogólnym przypadku nic nie stoi na przeszkodzie by wyjściowa partycja była arbitralnie rozszerzona. Dla celów modelowania architektury wielowarstwowej można przyjąć równoważność opartą na równości stereotypów przypisanych wierzchołkom grafów w diagramie UML. Jak wspomniano we wstępie do rozdziału, stereotypy mogą też tworzyć pewną algebrę (konkretnie kratę), która określi wspomnianą relację równoważności.
6.5. Liczba fasetowa
Z uwagi na niekorzystną własność (6.31) punktu stałego wyprowadzonego z relacji równoważności opartej o stopień wierzchołka, należy poszukać innych kandydatów do roli relacji podstawowej. Relacja podstawowa musi czynić zadość dwóm warunkom:
oraz (6.39)
gdzie 0 oznacza relację równości stopni wierzchołków.
Cechą, która będzie podstawą nowej relacji równoważności będzie liczba fasetowa. Nieformalnie można określić ją jako zbiór liczb określających długości cykli właściwych, do których należy dany wierzchołek. Jak łatwo sprawdzić relacja równoważności określona na liczbie fasetowej spełnia warunki określone w (6.39).
Jako przykład zostanie pokazany graf typu R3. Dla którego zachodzi 0 =I i w konsekwencja idzie s=I.
111

6.40 Liczba fasetowa
Dla wierzchołków V1 i V2 liczba fasetowa przyjmuje wartości odpowiednio:
V1={02,41}
V2={32,41}
Jak można sprawdzić, relacja nasycona wyznacza w tym przypadku relację równoważności grupy automorfizmu.
Wyznaczanie liczb fasetowych dla wierzchołków grafu może być wykonane w czasie O(mn+n), gdzie m oznacza ilość krawędzi a n ilość wierzchołków. W tym celu można zaadoptować algorytm podanym w monografii [Lipski]. Znajdujący się tam algorytm należy rozszerzyć w ten sposób, by dokonywał „triangulacji” grafu, tzn. identyfikował cykle właściwe (takie w którym wszystkie krawędzie grafu należą do danego cyklu. Innymi słowy jest - gdzie G oznacza graf a C cykl) [Ban76]. Dodatkowo, oprócz zbioru cykli właściwych algorytm musi wyznaczać również macierz przynależności wierzchołków do tychże. Otrzymana macierz razem z tablicą długości cykli pozwoli w łatwy sposób wyznaczyć liczbę fasetową.
Jak widać na rysunku (6.41), przyjęta została konwencja oznaczania długości cykli „otwartych” przez zero. Innym rozwiązaniem jest pominięcie cykli tego typu i uznanie za liczbę fasetową uporządkowanej pary składającej się ze stopnia wierzchołka oraz liczby fasetowej uwzględniającej tylko zamknięte cykle. Jak łatwo się przekonać obydwa określenia są sobie równoważne.
V1
6.41 Wiszące wierzchołki
V1={02,31,51} (cykle “zerowe”)
112

lub
V1=(4,{31,51}) (uporządkowana para)
113

7. Eksperymenty implementacyjne
Cechą charakterystyczną procesu rozwoju architektur oprogramowania jest przenikanie się praktyki programistycznej (dotyczącej tworzenia aplikacji), prac badawczych oraz działalności firm dostarczających oprogramowania narzędziowego. Charakterystyka ta dotyczy również Rozszerzonej Architektury Wielowarstwowej. W tym rozdziale konfrontuje się uzyskane wyniki w zakresie specyfikacji wymagań i ich praktycznej realizacji.
W celu wykazania przydatności zaproponowanego podejścia do zadań syntezy aplikacji wielowarstwowych przeprowadzono eksperymenty implementacyjne obejmujące realizację niekonwencjonalnych zadań. Jako przedmiot eksperymentu wybrano aplikacje, które oprócz realizacji reguł przetwarzania miały spełniać złożone wymagania operacyjne. W istocie wymagania dotyczące rekonfigurowalności, elastyczności, wydajności czy też administrowania systemem informatycznym miały wykazać sens postulatów stawianych w obszarach architektur komponentowych, agentowych czy też kooperacyjnych. Przede wszystkim zaś, pomyślnie przeprowadzone implementacje miały udowodnić, że zaproponowane w rozprawie techniki pozwalają na uzyskanie systemu informatycznego spełniającego w pełni założenia projektowe.
Zastosowania elementów RAW obejmują dwa studia przypadków (case study):
- System dystrybucji danych analitycznych, - Analiza parametrów operacyjnych holdingu MIS + mobilny ewidencja czasu
pracy,
oraz jedno studium wykonalności (feasibility study):
- System monitorowania procesów przemysłowych - (studium wykonalności).
Wątek tematyczny dotyczący zastosowań nowych rozwiązań architektonicznych jest obecny w licznych pozycjach literatury technicznej, których ciągle przybywa. Ten rozdział znajduje szczególną pozycję w pracy ze względu na osobliwe i bliskie powiązania między zagadnieniami architektur oprogramowania a praktyką tworzenia aplikacji dla konkretnych dziedzin przedmiotowych.
W każdym z trzech prezentowanych studiów podano specyfikację wymagań (requirements specification) oraz porównano alternatywne rozwiązania korzystające z konwencjonalnych technologii. Starano się wykazać istotną przewagę własności operacyjnych RAW nad tymi technologiami. Specyfikacja wymagań obejmuje funkcje aplikacyjne, reguły przetwarzania oraz wymogi operacyjne. Te ostatnie określane są też w literaturze jako nie-funkcjonalne.
114

Specjalizowane środowiska narzędziowe oraz środowiska czasu wykonania narzucają częstokroć realizowanemu w oparciu o nie systemowi określoną charakterystykę operacyjną. Inaczej jest w przypadku użycia elementów RAW. Zastosowanie elastycznej architektury oprogramowania pozwala na bezkompromisowe dostosowanie implementacji do wymagań. Co więcej stosowanie „firmowych” środowisk czasu wykonania związane byłoby (dla komercyjnych aplikacji) z koniecznością zakupu licencji na każdy węzeł wchodzący w skład systemu. Możliwość pomyślnej implementacji opartej jedynie na standardowych elementach systemu operacyjnego jest więc cechą ze wszech miar pożądaną.
7.1. System dystrybucji danych analitycznych
Zastosowana technologia: protokół DCOM, dynamiczny polimorfizm, refleksja, obiektowe strumienie danych (szczególny przypadek przekazywania obiektu przez wartość)
Założenia. Systemy informacyjne działające w organizacjach o złożonej strukturze, mające nieraz zasięg globalny muszą w łatwy sposób poddawać się integracji z oprogramowaniem pochodzącym od zewnętrznych dostawców, realizującym pewne wycinkowe funkcje. Sytuacja ta jest związana ze współpracą na zasadzie określanej jako outsourcing – gdzie pewne, nierzadko newralgiczne zadania, zlecane są niezależnym podmiotom. Działanie to jest ukierunkowane obniżenie kosztów, zwiększenie wydajności – pozwala bowiem na wykorzystanie wiedzy i doświadczenia firm wyspecjalizowanych w świadczeniu określonych typów usług. Przykładem takiej usługi mogą być analizy finansowe czy wydajnościowe wykonywane przez firmy doradcze zajmujące się oceną kadr, optymalizacją procesów, audytem, controllingiem.
Wspomniane usługi realizowane są w oparciu narzędzia programowe, które obejmują:
- narzędzia (ogólnego przeznaczenia np. pakiet SPSS, pakiet CAPI),- aplikacyjnych (realizowanych z myślą o konkretnym przedsięwzięciu.
W ramach przeprowadzonego eksperymentu zostało sformułowane zadanie realizacji systemu dystrybucji danych zawierających wskaźniki analityczne dotyczące poufnych danych. Dane będące przedmiotem planowanego systemu dystrybucji pochodzić miały z programów narzędziowych (graficznych analitycznych) i miały postać dokumentów (np. MSOffice), grafik, tabel wykresów. Założono, że oprogramowanie źródłowe, przy użyciu którego powstały te zasoby, obsługuje OLE2. Całość zasobu informacyjnego miała być następnie rozprowadzona zgodnie z arbitralnie przyjętą strukturą modelowanej organizacji. Założono, że dystrybuowane dane mają duża objętość oraz że struktura daje się przedstawić w postaci drzewa. Istotnym wymogiem w trakcie realizacji projektu była kwestia poufności danych.
115
Sikorski, 01/03/-1,
Sikorski, 01/03/-1,

Zbieranie danych
Analiza danych Walidacja Dystrybucja
6.1 Cykl powstawania zasobu informacyjnego
Proces realizacji projektu jest przedstawiony na rysunku (6.1). O ile sam proces wyznaczania wskaźników analitycznych w oparciu o zebrane dane był, zgodnie z przyjętymi założeniami realizowany w oparciu o standardowe narzędzia analityczne, to szczególnie wysokie wymagania miały dotyczyć systemowi dystrybucji danych. Określone wymagania obejmowały przede wszystkim kwestie bezpieczeństwa, integracji z programami z pakietu MSOffice oraz ograniczenia do minimum zadań związanych z instalacją i konserwacją realizowanego systemu. Charakterystykę operacyjną systemu dystrybucji można przedstawić w następujących punktach:
- Oprogramowanie ma działać w środowisku operacyjnym: stacje robocze Windows z zainstalowanym MSOffice.
- Oprogramowanie ma być możliwie niezależne od istniejącego systemu informatycznego. Każda organizacja dysponuje takim systemem. W szczególności należy ograniczać do minimum instalowanie środowiska czasu wykonania czy też ingerencję w konfigurację stacji roboczych oraz serwerów. Intencją było spełnienie wymogów związanych z przyjętymi standardami bezpieczeństwa oraz umożliwienie przesyłania raportów przy wykorzystaniu poczty – przez użytkowników mających minimalne doświadczenie w korzystaniu z systemu Windows
- Dystrybucja danych odbywać się ma w sposób zhierarchizowany. Uprawniony użytkownik może generować dalsze raporty (w dalszym ciągu w postaci pliku wykonywalnego) zawierający pewien podzbiór danych.
Uznano, że optymalnym rozwiązaniem byłby program zrealizowany w postaci pliku wykonywalnego, mający sam zdolność generowania plików wykonywalnych. Zasób informacyjny podlegający dystrybucji miał charakter semi-strukturalny.[semi] Składały się nań: dokumenty statyczne MSOffice (Word, Powerpoint), struktura danych opisująca schemat organizacyjny, grafiki w standardowych formatach. Oprócz możliwości generowania kolejnych „wcieleń” raportu, program miał dysponować możliwością generowania dynamicznych dokumentów MSOffice w oparciu o zawarte w aplikacji dane oraz decyzje użytkownika. Wszystko to miało się odbywać przy założeniu minimalnych umiejętności potencjalnego użytkownika w zakresie obsługi aplikacji. Architektura aplikacji miała dodatkowo ułatwiać przyszłe modyfikacje projektu, dodatkowe wymagania. Należy zwrócić uwagę, że o ile w przypadku reguł przetwarzania brak jednoznacznej ich specyfikacji nie jest niczym nadzwyczajnym, to kwestia podstawowych własności operacyjnych (architektonicznych) jest znacznie
116

mniej elastyczna i niechętnie poddaje się modyfikacjom. Niemniej przeprowadzony eksperyment miał wykazać, na ile takie modyfikacje są możliwe i jaki pociągają za sobą nakład pracy.
Zastosowana technologia (skrócone studium wykonalności):
W ramach przeprowadzonego studium wykonalność rozpatrzono następujące możliwe rozwiązania:
- klient serwer oparty na bazie danych,- intranet, przeglądarkę WWW + JAVA,- aplikacja w stylu rozszerzonej architektury wielowarstwowej (COM, dynamiczny
polimorfizm, MBV) RAW.
Klient serwer(baza danych) Podstawowym narzędziem realizacji aplikacji służących do przetwarzania dużych ilości danych są systemy zarządzania bazami danych, w szczególności systemy baz relacyjnych (SZRBD). Ponieważ wszystkie SZRBD oparte są na złożonych systemach czasu wykonania (run-time environment). Co więcej, z uprzednich doświadczeń wynika, że często oprogramowanie wykonane w architekturze klient serwer wymaga również dedykowanych stacji roboczych. O ile rozwiązanie takie jest dopuszczalne w przypadku oprogramowania aplikacyjnego realizujące statutowe firmy czy organizacji, to zewnętrzny dostawca usług musi w najwyższym stopniu dostosować swoje oprogramowanie do istniejącej bazy informatycznej, ingerując w nią w minimalnym stopniu.
Dodatkowym mankamentem architektury klient serwer opartej na serwerze baz danych jest, w rozpatrywanym przypadku, konieczność zapewnienia dostępu do centralnego serwera z danymi lub zaimplementowanie (w sensie konfiguracji) usług powielania (replikacji) danych. Z uwagi na przyjętą złożoną strukturę oraz jej znaczne rozproszenie terytorialne, jak i wymóg minimalnej ingerencji w istniejący system – konieczność odpowiedniego konfigurowania łącz jest niewątpliwym naruszeniem przyjętych założeń.
Ostatnim wreszcie argumentem przeciw klasycznej architekturze klient serwer jest postać przetwarzanych danych zawartych w systemie, mianowicie ich semi-strukturalna natura. Należy zauważyć, że to ograniczenie nie dotyczyło operacyjnych własności baz danych lecz ich logicznych podstaw - modelu relacyjnego. Należy zauważyć, że nie rozpatrywane tutaj bazy obiektowe nie mają tych ograniczeń.
Intranet Zastosowanie serwera WWW jako mechanizmu dostępu do bazy danych mogło wyeliminować szereg ograniczeń związanych z klasycznie rozumianą technologią klient serwer. W szczególności przeglądarka WWW (MSIE) jest
117

standardowym elementem systemu Windows dzięki czemu spełniony jest wymóg braku dodatkowego środowiska czasu wykonania.
Intranet rozumiany jako udostępnienie usług internetowych zawartych w protokole TCP/IP w obrębie wewnętrznej sieci firmy jest nową agresywnie rozwijającą się technologią w której obecne są elementy architektur wielowarstwowych. Serwer WWW może być w tym przypadku uważany za realizację warstwy pośredniczącej. Zaawansowana obsługa protokołów obiektowych (zarówno DCOM i CORBA) w serwerach WWW oraz uważane za przestarzałe (niesłusznie) protokoły z grupy CGI (pro dialog) stwarzają możliwość realizacji złożonych reguł przetwarzania w oparciu o dowolne języki programowania (wynika to z prostoty mechanizmu komunikowania się serwera WWW z kodem wykonywalnym w ramach CGI). Co ciekawe, choć CGI bywa częstokroć krytykowany warianty CGI jakim są jsp czy asp uważane są za nowoczesne techniki tworzenia zastosowań w intra- i internecie.
Rozwiązanie intranetowe było rozpatrywane jako poważny kandydat na architekturę implementacji realizowanego systemu. Wyborowi tego wariantu na przeszkodzie stanęły konieczność skonfigurowania serwerów WWW oraz konieczność zapewnienia bezpieczeństwa przesyłanych danych. Analiza kosztów wdrożenia systemu oraz konieczność jego integracji z funkcjonującym już w ramach intranetem okazały się decydujące. Również mechanizm zhierarchizowanej dystrybucji (dokonywanej indywidualnie na poszczególnych szczeblach) oraz konieczność obsługi semistrukturalnych danych czy wreszcie kwestie związane z generowaniem dynamicznych dokumentów MSOffice, aczkolwiek możliwe do rozwiązania w ramach intranetu (CGI), okazały się czynnikami, które zadecydowały o rezygnacji z tego rozwiązania na korzyść RAW.
RAW Jako ostatni kandydat pozostała architektura wielowarstwowa. Paradoksalnie postanowiono wykorzystać elementy architektury rozszerzonej w aplikacji, której zewnętrzna postać w największym stopniu przypomina aplikację monolityczną w jej najbardziej skrajnej (brak nawet plików z danymi). W trakcie precyzowania projektu stwierdzono, że pojedynczy plik EXE w największym stopniu odpowiada założeniom. Wykluczono nawet obecność statycznych plików z dokumentami.
Implementacja Jako język implementacji wybrano Delphi, przede wszystkim ze względu na doskonałą obsługę funkcji DCOM i elegancki sposób obsługi automatyzacji OLE, będącej istotnym elementem składowym dynamicznego polimorfizmu. Elementami architektury wielowarstwowej, które znalazły zastosowanie w implementowanym systemie były:
- dynamiczny polimorfizm, wykorzystany jako mechanizm dostępu do danych zawartych w raportach, w semistrukturalnych typach danych
118

- MBV rozumiany jako reprezentacja strumieniowa obiektu, w tym konkretnym przypadku jako reprezentacja dokumentu,
- przetwarzanie asynchroniczne (użyte jedynie w celu poprawienia walorów użytkowych systemu).
Zarówno proces specyfikacji wymagań jak i sformułowanie zadań w kategoriach problemów technicznych zawierało w sobie kilka iteracji z uwagi na eksperymentalny charakter przedsięwzięcia i brak oprogramowania, które mogłoby stanowić wzorzec.
GU
ID Serialized
data (IStream)
Executable Module
GU
ID Serialized
data (IStream)
6.2 Struktura pliku wykonywalnego MBR
Jednostki danych zawarte w systemie potraktowane zostały jak dokumenty, których struktura jest funkcją bieżącego stanu całego systemu (konkretnie poziomem danej jednostki organizacyjnej w strukturze hierarchii). Dzięki zastosowaniu dynamicznego mechanizmu uzyskano ujednolicony dostęp typu DOM (Document Object Model) do dokumentów statycznych, implementujących model obiektowy dokumentu MSOffice oraz do dokumentów „aplikacyjnych” zwierających dane wygenerowane w postaci własnych obiektów. W ten sposób rozwiązany został problem braku struktury danych przetwarzanych przez system.
Możliwość przetwarzania danych zawartych za pomocą interfejsu obiektowego w dokumentach określone jako aplikacyjne, tzn. tych które powstały przy użyciu specjalizowanych narzędzi aplikacyjnych, jest uwarunkowana dostępnością implementacji odpowiednich klas komponentów. Innymi słowy globalny identyfikator GUID powinien być na danym węźle skojarzony ze ścieżką do pliku wykonywalnego lub modułu dynamicznego. Wymóg ten jest oczywiście sprzeczny z przyjętymi założeniami, w których jednoznacznie wskazano na konieczność unikania jakichkolwiek środowisk czasu wykonania.
Problem ten jest bardziej ogólny i jest związany z dostępnością typów agentowych w systemie rozproszonym oraz z zarządzaniem tą dostępnością. Rozwiązaniem zaproponowanym w rozdz. 5 jest usługa katalogowa, która w połączeniu z sieciowym systemem plików lub np. protokołem FTP, dostarczałaby implementację na dany węzeł. W omawianym przypadku, wybrano rozwiązanie prostsze: dokument był zapisywany w dwóch postaciach. Jedna z nich odpowiadała stanowi komponentu implementującego dany dokument, druga zaś była po prostu metaplikiem. Metaplik umożliwia wyświetlenie dokumentu, jego wydruk czy też eksport (tylko w postaci wizualnej) do aplikacji MSOffice. Pomysł ten oparto na metodzie zastosowanej jeszcze w pierwszej wersji OLE – gdzie dokumenty osadzone były widoczne w dokumencie głównym niezależnie od tego czy aplikacja źródłowa była zainstalowana.
119

6.3 System dystrybucji danych (struktura + pojedyncza grafika)
Strumieniowa reprezentacja dokumentu (egzemplarza komponentu) rozwiązała zagadnienie generowania raportów częściowych. Generowany raport został potraktowany jako strumień w którym najpierw zapisywany jest kod (bez modyfikacji), następnie zapisywane są obiekty danych. Zgodnie z techniką użytą w MBV zapis składa się z identyfikatora typu oraz stanu obiektu. Metoda MBV nie czyni żadnych założeń co do postaci strumienia, z wyjątkiem tego, że musi udostępniać interfejs IStream.
Dokumenty, w opisanej wyżej postaci, strumieniowa postać drzewa oraz indeks zawierający fizyczne adresy komponentów i nazwy ich typów stanowią prostą bazę danych. Można zauważyć, że swoją strukturą przypomina ona hierarchiczny system plików. Okazuje się, że technika komponentowa pozwala w łatwy sposób symulować pewną „wirtualną” hierarchię plików, która z kolei może stanowić odpowiednik środowiska czasu wykonania dla danej aplikacji.
Proces generowania plików wykonywalnych jest w tym przypadku odpowiednikiem operacji kopiowania dokumentów w ramach drzewiastej struktury katalogów. W tym konkretnym systemie założono, że możliwe jest jedynie kopiowanie poddrzew dostępnej struktury. Ograniczenie to nie wynika jednak w żadnym przypadku z przyczyn technicznych.
120

6.4 Definiowanie i eksport raportów
Symulację asynchroniczności wykorzystano jedynie do generowania dynamicznych dokumentów MSOfffice w celu podniesienia walorów użytkowych (uogólniona modalność). Uczyniono tak ze względu na powolne działanie funkcji VBA dla dokumentów MSOffice. Przetwarzanie asynchroniczne może mieć duże znaczenie dla zadań integracji realizowanego systemu z istniejącymi ( legacy) aplikacjami lub oprogramowaniem narzędziowym. Składowe te, mogą nie spełniać postulowanych wymagań wydajnościowych. W związku z tym, możliwość wykorzystania elementów przetwarzania asynchronicznego i związanych z nim mechanizmów synchronizacji procesów jest cennym wsparciem wszędzie tam gdzie reguły przetwarzania na to pozwalają.
7.2. Relacyjne bazy danych w aplikacjach RAW
Wielowarstwowa baza danych oparta na komponentach o cechach agentów mobilnych. Zastosowana technologia: przekazywanie obiektów przez wartość, CGI intranet
Założenia Jako wynik łączenia się firm, organizacji oraz procesów integracyjnych powstają jednostki ekonomiczne, konglomeraty oraz tzw. holdingami. Wspomniane procesy integracyjne odbywają się zarówno w wyniku współpracy jak i wrogiego przejęcia. Na obecnym etapie rozwoju technologii informatycznych należy liczyć się z
121

tym, że w każdej z jednostek wchodzącej w skład holdingu mogą funkcjonować własne, sprawdzone systemy informatyczne.
W takim przypadku istnieją dwie możliwe metody postępowania. Można narzucić firmie jeden zunifikowany system. Można też zintegrować istniejące systemy w stopniu umożliwiającym efektywne zarządzanie holdingiem. Podejście integrujące, ma tę zaletę, że uwzględnia specyfikę poszczególnych organizacji wchodzących w skład większej całości. Istotą holdingu jest bowiem zachowanie poprzez jego składowe pewnej odrębności. W takiej sytuacji wdrażanie zunifikowanego systemu może być kosztowne i nieuzasadnione.
W sytuacji holdingu mamy do czynienia z wieloma rozproszonymi zasobami informacyjnymi. Zasoby w autonomicznych systemach mogą mieć różną strukturę. Najczęściej są też zrealizowane w oparciu o różne SZRBD. Zadaniem oprogramowania MIS jest dostarczenie w oparciu o te dane syntetycznych wskaźników dotyczących stanu holdingu.
Składowe firmy mogą znajdować się w różnych miejscach w obrębie jednego kraju lub nawet być rozproszone po świecie. Poszczególne systemy informatyczne rejestrują dane dotyczące działalności tych składowych niezależnie od siebie. W opisywanym projekcie założono, że modelowany holding powstał w wyniku przejęcia kilku niezależnych podmiotów rozrzuconych na większym obszarze. W wyniku fuzji oraz akwizycji holding przekształcił się w sfederowany organizm, w którym poszczególne składowe mają swoje zasoby danych i obsługujące je aplikacje.
Centralną jednostkę holdingu modelował serwer baz danych SQL Anywhere. Zadanie obejmowało integrację baz danych jednostek zależnych przy zachowaniu ich autonomii. Jednocześnie miał powstać rozproszony mechanizm ewidencji danych, umożliwiający ich wprowadzanie i pozyskiwanie z węzłów mobilnych (komputery przenośne, tel. komórkowe, urządzenia PDA )
Wymagania postawione planowanemu systemowi MIS można ująć w następujących punktach:
- System powinien likwidować różnice semantyczne w procesie zbieranie danych od różnych jednostek wchodzących w skład holdingu. Dane syntetyczne powinny przyjąć postać obecną w działającym już systemie jednostki centralnej.
- Powinien być możliwy dostęp do wyników za pomocą przeglądarki. Związane jest to z możliwością wystąpienia różnych platform sprzętowych (zwłaszcza Apple Macintosh). Żaden z systemów tworzenia aplikacji dla Mac’a nie wydaje się być adekwatny do zadań stawianych przed systemem informacyjnym. Dlatego interfejs realizowanego systemu ma być oparty na WWW.
122

- System powinien być w stanie działać w oparciu o łącza komutowane, modemy, wykluczony jest wymóg dostępności stałych łącz. Usługi komunikacyjne, umożliwiające dostęp do rozproszonych zasobów nie mogą zakładać istnienia homogenicznej sieci komunikacyjnej. Co więcej należy liczyć się z występowa-niem wolnych i zawodnych połączeń.
- Dostęp do danych 24h na dobę – chyba że brak będzie fizycznego połączenia. W dowolnym momencie centralny system powinien mieć możliwość dostępu do danych.
- Ingerencja w istniejące systemy powinna być zminimalizowana. Mają one zachować dotychczasową autonomię.
Zastosowana technologia (skrócone studium wykonalności):
Rozważana była implementacja w oparciu o następujące architektury:
- implementacja modułów generujących standardowe raporty w składowych systemach informatycznych,
- klasyczna architektura wielowarstwowa oparta na osłonach i mediatorach, [Ullman]
- rozszerzona architektura wielowarstwowa umożliwiająca wykorzystanie obiektów o cechach operacyjnych równoważnych agentom mobilnym.
Najprostsze rozwiązanie polegające na rozszerzeniu wycinkowych elementów globalnego systemu informatycznego jest prawdopodobnie najczęściej wykorzystywane. Jest to rozwiązanie off-line, gdzie nie występuje bezpośrednie połączenie pomiędzy systemem macierzystym i systemami składowymi. Jego wygoda polega przede wszystkim na przerzuceniu odpowiedzialności za dostarczanie danych na stronę poszczególnych jednostek wchodzących w skład holdingu. Niemniej taka „dystrybucja odpowiedzialności” może mieć niekorzystne skutki dla systemu zarówno w kategoriach jego jakości jak i czasu wdrożenia. Co więcej nakłady poniesione na jego rozwój mogą się okazać zupełnie stracone jeżeli w pewnym momencie któryś ze składowych elementów będzie musiał być ściślej zintegrowany z systemem macierzystym. Rozwiązanie takie nie jest bowiem z oczywistych powodów skalowalne. Co więcej pełna automatyzacja procesu przekazywania danych w oparciu o generowane lokalnie dokumenty może okazać się trudne. Zwłaszcza wymóg 24 godzinnej dostępności danych stawiałby takie rozwiązanie pod znakiem zapytania. Firmy działające w skali globalnej globalne mogą prowadzić operacje w różnych strefach czasowych – w związku z tym poszczególne składowe systemu muszą być cały czas gotowe do podjęcia stosownych działań. Niedopuszczalny jest w związku z tym wymóg jakiegokolwiek udziału czy ingerencji pracowników w proces przygotowywania danych.
123

Zagadnienie integracji systemów informatycznych jest uważane za jeden z głównych tematów badań z zakresu baz danych [Ullman]. Jako główne zadania stawiane w tym obszarze określa się: integrację istniejących (legacy) zasobów danych, przezwyciężanie różnic semantycznych , stworzenie metod dostępu do pół- strukturalnych zasobów danych – takich jak WWW. Jednym z najpopularniejszych zaproponowanych rozwiązań są opisane dalej – konwencjonalne architektury wielowarstwowe baz danych.
6.5 Konwencjonalna architektura wielowarstwowa aplikacji bazodanowej [Pank][Ullman]
Architektura wielowarstwowa, druga z rozpatrywanych możliwości, eliminuje większość wad rozwiązania typu off-line. Ogólny schemat aplikacji może być uproszczony ze względu na konieczność występowania tylko jednego mediatora – reprezentującego semantykę centralnej aplikacji MIS z centrali holdingu. Mediator ten może być zaimplementowany w postaci komponentu realizującego funkcję CGI współpracy z serwerem WWW. Poszczególne osłony zapewniają w tej sytuacji ujednolicony dostęp do baz danych. W konkretnie rozpatrywanym systemie mediator mógłby być aplikacją lub komponentem który jest klientem bazy danych działającym niezależnie od reszty systemu.
124

Nakład poniesiony na rozwój mediatorów dla poszczególnych systemów składowych mógłby być wykorzystany w przypadku dalszego rozwoju firmy o kolejne składowe. Mediator zrealizowany w postaci implementacji szkieletowej mógłby dzięki technikom programowania obiektowego zawierać w sobie metody wirtualne czy też klasy abstrakcyjne – ukonkretniane dla poszczególnych przypadków.
Rozszerzona architektura wielowarstwowa może być dalszym udoskonaleniem opisywanego rozwiązania. Możliwe jest to dzięki odejściu od operacyjnego rozumienia mobilności agenta. Przejście agenta pomiędzy węzłami może nie tylko dostosowywać go to zmiennych warunków operacyjnych np. platformy systemowe lecz również zawierać w sobie funkcjonalność niwelującą różnice semantyczne. Zaletą systemu jest jego większa elastyczność. Wdrożenie systemu agentowego przy okazji realizacji zadań związanych z MIS stanowi inwestycję zorientowaną na przyszłość. Agent będący obiektem pewnej klasy może modyfikować swoje własności operacyjne. Dotyczy to zwłaszcza sposobu wykonywania transakcji.
Dane 1
Serwer WWW
Systemagentowy 1
Systemagentowy 2
Systemagentowy 3
Dane 2 Dane 3
Agentmobilny
Systemagentowy 0
Stan + GUID
SysAgen X GUID ->Implementacja
6.6 Rozszerzona architektura wielowarstwowa aplikacji bazodanowej
Istotnym czynnikiem, który miał wpływ na wybór użytej technologii, była częściowa implementacja asynchronicznego systemu zbierania informacji. Implementacja ta, została wykonana jeszcze przed przekształceniem się firmy w holding. Jej zadaniem było zbieranie syntetycznych danych w oddziałach organizacji.
Implementacja. Podstawowym założeniem systemu agentowego było wykorzystanie istniejących publicznych sieci komunikacyjnych, łącz komuntowanych i
125

sieci lokalnych. Dzięki niezależności protokołu TCP/IP od konkretnych usług warstw niższych, system agentowy mógł działać w dowolnym środowisku komunikacyjnym. Podstawowym protokołem użytym w implementacji był oparty o TCP/IP protokół obiektowy DCOM. Wybór protokołu DCOM podyktowany był doświadczeniem zebranym podczas realizacji innych projektów. Z uwagi na naturalne dążenie do ujednolicenia narzędzi i technologii stosowanych przez zespół realizujący projekt nie zdecydowano się na użycie protokołu CORBA. Co więcej środowisko Delphi 3 i architektura aplikacyjna MIDAS nie obsługiwały w tamtym czasie tego protokołu.
Oprócz protokołu komunikacyjnego, na środowisko implementacji składały się: wspomniana już Delphi, PowerBuilder, Sybase SQL ASA, Apache Web Server, MSOffice, Windows NT. Zasoby (bazy) danych w poszczególnych systemach składowych mogły działać na różnych platformach sprzętowych i systemowych. W istocie, już w początkowym okresie były to: Suse Linux, Solaris ( na platformie Netra). W takim przypadku zakładano albo obecność jednego serwera Windows w danej sieci lokalnej lub rezygnowano z mobilności – agent nawiązywał połączenie z bazą danych z najbardziej dogodnego węzła systemu agentowego.
Podstawą technologii implementacji było:
- wykorzystanie zagregowanego wątku jako symulacji wywołania asynchronicznego,
- przekazywanie przez wartość MBV w celu realizowania mobilności oraz niwelacji różnic semantycznych.
Implementacja agenta składała się z dwóch warstw logicznych. Pierwsza odpowiadała za zbieranie danych, realizując zadania mediatora z konwencjonalnej architektury wielowarstwowej. Druga z nich była odpowiednikiem osłony. Istotną cechą agenta było opisane w rozdz. 4 odejście od operacyjnego rozumienia mobilności agenta. W każdym systemie agentowym dany GUID odpowiadał lokalnej implementacji, zgodnej jedynie pod względem logicznym z innymi o tym samym GUID. Takie rozwiązanie można uważać też za częściowe odstępstwo od zasady, wedle której GUID w sposób jednoznaczny identyfikuje dany typ obiektowy w kontekście protokołu DCOM. Odejście to można traktować jako rozszerzenie pojęcia wspomnianego kontekstu. Jako taki będzie rozumiany konkretny węzeł systemu agentowego.
System agentowy składał się z komponentu samego agenta oraz z statycznych komponentów komunikacyjnych – po jednym na każdy węzeł. Zadaniem komponentu komunikacyjnego była obsługa MBV. Wśród węzłów systemu agentowego, jeden był odpowiedzialny za udostępnianie uzyskanych wyników w postaci dynamicznego dokumentu HTML. Obecnie zarówno reguły przetwarzania dla osłony jak i schemat komunikacyjny połączeń agentów jest podany statycznie.
126

Ocena wykonania Opisywany system jest ciągle w fazie eksperymentu. Planowane jest sparametryzowanie osłon w taki sposób, by zadanie dopasowywania nowych źródeł danych stało się zadaniem administracyjnym, a nie programistycznym. Dalszym etapem rozwoju ma być dynamiczny wybór tras dla mobilnych agentów. Oprócz stron HTML, dane powinny być dostępne również w postaci dokumentów MSOffice (tabele Excel oraz wykresy czy nawet prezentacje PowerPoint). Dokumenty MSOffice mogą być zrealizowane jako:
- dokumenty dynamiczne, aktualizujące swój stan na żądanie użytkownika (poprzez techniki CGI )
- dokumenty asynchroniczne, automatycznie aktualizujące swoją zawartość automatycznie (obiekty łączone OLE)
7.3. Elastyczna reprezentacja obiektów sterujących dla systemów automatyki przemysłowej - (studium wykonalności)
Integracja systemów sterowania i monitorowania systemów przemysłowych z aplikacjami o rozszerzonej architekturze wielowarstwowej. Refleksja jako aplikacyjny odpowiednik PnP.
Zadanie. Z uwagi na swoiste wymagania systemów czasu rzeczywistego, w tym zadań sterowania procesami przemysłowym i ich monitorowania, były one implementowane w specjalizowanych środowiskach operacyjnych. [Show], [Cellary], [Brinch]. Systemy operacyjne czasu rzeczywistego były przede wszystkim ukierunkowane na obsługę dostępu do zasobów sprzętowych danej platformy, przy spełnieniu dużych wymagań wydajnościowych oraz dużej niezawodności. Istotnymi cechami systemów tego typu były:
- wielozadaniowość,- jednolite traktowanie zadań aplikacyjnych i systemowych,- możliwość wywłaszczania procesów i sterowania priorytetem ich wykonania.
Wraz ze wzrostem wydajności platform sprzętowych możliwe stało się odejście od niskopoziomowej obsługi sprzętu na rzecz zwiększonego wsparcia dla programowania aplikacyjnego [Konsta]. Jednym z istotnych aspektów tego procesu jest wzrastające znaczenie protokołów obiektowych w obrębie aplikacji czasu rzeczywistego [Sikor00a].
Pojawienie się protokołu obiektowego, jako środowiska komunikacyjnego dla systemów czasu rzeczywistego jest szansą na wykorzystanie technologii wyższego rzędu w tym obszarze. Przykładem takowej mogą być systemy mobilnych komponentów, w tym agenci mobilni czy też integracja technik intranetowych [ Ivan].
Należy zauważyć, że aplikacje systemów czasu rzeczywistego stanowią niejako system operacyjny dla kontrolowanych przez siebie obiektów przemysłowych. W
127

związku z tym uprawniona jest analogia do magistrali PCI z komputerów PC obsługujących technikę plug’n’play. Jak już wspomniano w rozdz. 4 refleksja może być uważana za jej aplikacyjny odpowiednik Oparta o protokół DCOM magistrala programowa, obsługująca mechanizm refleksji pozwala na dekompozycję całego systemu na dwie warstwy.
Konkretny przypadek przedstawiony w pracy [Ivan] pokazuje rysunek (6.5). System oparty jest na wspomnianej już dwupoziomowej hierarchicznej strukturze. Jeden poziom tworzony jest poprzez część operacyjną opartą o przemysłową magistralę Profibus i standardowe karty Smart. Drugi poziom reprezentuje sieć TCP/IP połączona z internetem oraz siecią LAN. Sieć LAN zawiera w sobie część aplikacyjną na którą składają się bazy danych oraz oprogramowanie stacji roboczych czy też serwery aplikacji. Elementem łączącym obydwa poziomy jest węzeł VME pracujący pod kontrolą systemu czasu rzeczywistego OS/9 zaopatrzony w interfejs Profibus jak i implementację TCP/IP.
Studium wykonalności. Oparty na UDP protokół BOOTP [Comer] oraz jego bardziej zaawansowana mutacja DHCP umożliwiają implementację bezdyskowych węzłów sieci. Podczas startu urządzenie (na przykład sterownik procesu przemysłowego) wysyła żądanie w ramach danej sieci lokalnej. W odpowiedzi serwer sieci lokalnej zaopatruje dany węzeł w adres IP, adres routera oraz inne dane niezbędne do funkcjonowania protokołu IP. Co więcej możliwe jest zdalne załadowanie pliku startowego – tym razem za pomocą protokołu TFTP.
PROFIBUS
VME
LANInternet TCP/IP
6.7 Monitoring w technologii intranet [Ivan]
Proces startu bezdyskowego węzła jest dwuetapowy (dalej za [Comer]). Sam komunikat nie zawiera obrazu pliku startowego. Inaczej, węzeł otrzymuje jedynie dane niezbędne do pobrania danych z serwera obsługującego sieć. Dzięki odpowiednim możliwościom konfigurowania system oparty na protokole BOOTP może obsługiwać wiele typów urządzeń.
128

Nic nie stoi również na przeszkodzie by procedura zdalnego startu urządzenia obejmowała przekazanie pewnej (chociażby szczątkowej) implementacji protokołu DCOM. Szczątkowa implementacja powinna jedynie umożliwić odbieranie komunikatów transmisyjnych ORPC [ORPC] oraz utworzenie obiektu implementującego jeden interfejs reprezentujący dany obiekt automatyki przemysłowej. Z uwagi na wsparcie dla mechanizmu refleksji korzystne byłoby udostępnienie takiego interfejsu w postaci dualnej (razem z obsługą interfejsu IDispatch). Należy jednak rozważyć czy w przypadku urządzeń przemysłowych refleksja zawsze jest uzasadniona. Na pewno nie w przypadku gdy najczęściej mam się do czynienia ze statycznymi układami urządzeń i procesów. Wtedy jedynym uzasadnieniem mogłoby być umożliwienie współpracy z aplikacjami z pakietu MSOffice. Jednakże konieczność szybkiej zmiany profilu produkcji czy też przydziału środków do poszczególnych zadań sprawiają, że refleksja jest wydajnym mechanizmem zwiększającym elastyczność i rekonfigurowalność systemu sterującego produkcją. Podobnie jak komputer PC dzięki technice pnp, tak system sterujący urządzeniami, może za pomocą refleksji programowej wykrywać zmiany i dostosowywać się do nich.
DCOM (TCP/IP)
BootPDCOMTFTP
Węzły kompatybilne zBootP
6.8 Obiektowa reprezentacja węzłów
Węzeł sieci zaimplementowany w postaci bezdyskowego procesora protokołu DCOM jest z punktu widzenia architektury wielowarstwowej niczym innym jak serwerem aplikacji. Serwer ten jest dostępny dla innych składowych aplikacji rozproszonej. Może on zarówno odbierać jak i przekazywać dane. Może współpracować z aplikacjami odpowiedzialnym za komunikację z użytkownikami systemu. Z uwagi na pełną integrację z systemem wielowarstwowym możliwe jest wykorzystanie w charakterze komponentu odpowiedzialnego za tę komunikację przeglądarki WWW lub arkusza kalkulacyjnego.
W przypadku wykorzystania przeglądarki, pewnym wyzwaniem może okazać się implementacja interfejsu graficznego użytkownika. Możliwe są tu dwa rozwiązania:
- applet w języku JAVA,
129

- graficzny CGI.
Druga z wymienionych możliwości wykorzystuje fakt, że odpowiedź w protokole CGI nie musi mieć typu tex/htmlt. Równie dobrze aplikacja realizująca skrypt CGI może w odpowiedzi na żądanie wygenerować plik graficzny, zawierający np. wykres. Plik ten może wchodzić w skład innej strony, również wygenerowanej przez CGI. W skrajnym przypadku rolę serwerów CGI mogą pełnić węzły reprezentujące poszczególne urządzenia.
6.9 Definicja biblioteki typów dla przykładowego węzła automatyki
Rozwiązanie to nie ma rangi standardu. Niemniej z doświadczeń autora wynika, że jest wydajne i relatywnie łatwe w implementacji. Kolejnym wyzwaniem jeśli chodzi o implementację interfejsu WWW dla aplikacji czasu rzeczywistego może być kwestia symulowania sesji. Zagadnienie to doczekało się szczegółowego opracowania w literaturze technicznej. m.in. [Sikor99]
130
8. Zakończenie
8.1. Wnioski ogólne
Cechą charakterystyczną konwencjonalnych architektur oprogramowania jest występowanie ścisłego rozgraniczenia pomiędzy warstwą aplikacyjną oraz systemową. Aplikacja, która jest odpowiedzialna za implementację reguł przetwarzania korzysta z funkcji udostępnianych przez system operacyjny. Dotyczy to zarówno aplikacji o architekturze monolitycznej jak i klient – serwer. W przypadku tej drugiej serwer może być postrzegany jako rozszerzenie środowiska systemowego aplikacji. W istocie jeden z modeli architektonicznych systemów operacyjnych ma strukturę klient (aplikacja) – serwer (system).
Architektura wielowarstwowa, w tym jej rozszerzona postać wprowadza nowe rozumienie programowania aplikacyjnego. Dla komponentu składowego systemu rozproszonego zarówno konwencjonalnie rozumiany „system operacyjny” jak i inne komponenty tworzą środowisko operacyjne. Komponent korzysta z funkcji zarówno systemowych jak i tych udostępnianych przez inne komponenty.
W kontekście rozszerzonej architektury wielowarstwowej w miejscu funkcji aplikacyjnych i systemowych pojawiają się własności odpowiednio: funkcjonalne oraz nie-funcjonalne [Nierstrasz]. Z uwagi na fundamentalne znaczenie własności systemu operacyjnego dla architektur oprogramowania prawdopodobne jest odejście z czasem od klasycznych systemów operacyjnych. Innymi słowy hasłu „sieć to komputer” będzie w obszarze architektur aplikacji odpowiadać hasło „system to protokół obiektowy”. Protokoły sieciowe (np. TCP/IP) operowały bytami odległymi od warstwy aplikacyjnej. Protokół obiektowy, z kolei oparty jest o pojęcie obiektu występujące na wszystkich poziomach modelowania aplikacyjnego. Już dzisiaj wiodący (pod względem udziału na rynku) producent systemów operacyjnych – MS uznaje protokół DCOM za najważniejszy komponent systemu.
Zmiany w architekturze oprogramowania już wywierają wpływ na kształt narzędzi programistycznych. Charakterystyczne jest odchodzenie od języków czy środowisk dedykowanych pewnej określonej klasie zastosowań. Środowiskami tego typu były w obszarze baz danych CA-Clipper, dBase, Paradox. Obecnie pokutują jeszcze PowerBuilder, Oracle czy Access. Charakterystyczna jest malejąca rola tych narzędzi. Dzięki pojawieniu się protokołu obiektowego coraz większą role odgrywają środowiska zorientowane na tworzenie komponentów i korzystanie z nich. W istocie, wystarczy by kod generowany przez dany język obsługiwał protokół COM, by można było w nim tworzyć aplikacje baz danych opartą np. na ADO.
131

Należy oczekiwać, że podobny proces będzie można zaobserwować w obszarze architektur agentowych. Jak pokazano w pracy, podstawowa charakterystyka operacyjna agenta (asynchronicznosć i mobilność) może być zapewniona przez użycie odpowiednich technik na poziomie protokołu. Co ciekawe, pomimo postulowania pewnych operacyjnych własności komponentów [Nierstrasz] (agregowanie i refleksja), nie powstały środowiska ukierunkowane na ten model programowania. Należy zauważyć raz jeszcze, że w rozszerzonej architekturze wielowarstwowej posługiwano się innym rozumieniem komponentu. Był nim mianowicie obiekt protokołu sieciowego implementujący interfejsy określone przez standard.
8.2. Omówienie wyników
Protokół obiektowy może znaleźć zastosowanie jako mechanizm komunikacji pomiędzy komponentami realizującymi funkcje krytyczne pod względem czasowym oraz komponentami odpowiedzialnymi za prezentację stanu oraz interakcję z użytkownikiem. Dodanie mechanizmu wywołania asynchronicznego w istotny sposób zwiększa walory protokołu DCOM w kontekście systemów sterujących urządzeniami czy monitorujących złożone procesy technologiczne.
Przedstawiona technika symulacji wywołania asynchronicznego, chociaż zaprezentowana w ramach protokołu DCOM, może być zastosowana również w innym protokole obiektowym. Zastosowanie architektury wielowarstwowej i dekompozycja oprogramowania na komponenty pozwala wyodrębnić jednostki realizujące zadania krytyczne pod względem czasu wykonania i niezawodności oraz te, w przypadku których najistotniejszym czynnikiem może być elastyczność dialogu z użytkownikiem. Wszystko to może przyczynić się zarówno do wzrostu niezawodności oprogramowania oraz efektywności procesu jego rozwoju. Tak więc, protokół obiektowy może integrować w jeden system składowe o różnych charakterystykach wydajnościowych czy różnej stabilności.
Przedstawione w pracy metody symulacji przekazywania parametrów przez wartość są próbą pełnego przedstawienia dostępnych w protokołach obiektowych mechanizmów rozszerzania funkcjonalności komponentów. Takie rozszerzenie okazuje się być pewnym wyzwaniem, jeżeli komponent dostępny jest jedynie w postaci kodu binarnego. Klasyczne metody osadzania obiektów czy wykorzystania gotowych bibliotek nie mogą być w tym przypadku w prosty sposób wykorzystane.
Utarło się niesłuszne przekonanie jakoby rozproszone programowanie aplikacyjne było domeną języka JAVA. W istocie, język ten dzięki przenaszalności na poziomie kodu wykonywalnego maszyny abstrakcyjnej jest atrakcyjną propozycją, zwłaszcza w obszarze programowania opartego o architektury agentowe. Niemniej, jak pokazano w
132

pracy, najważniejszym czynnikiem integrującym rozproszone komponenty jest protokół obiektowy. W oparciu o przedstawioną technikę rozdzielonej implementacji agenta, można zaimplementować jego mobilność oraz kompatybilność z wieloma platformami. Odejście od czysto operacyjnego (czyli jak jest to rozumiane w pracy semantycznie neutralnego) traktowania mobilności agentów pozwala w nowy sposób rozwiązać kwestie heterogeniczności zasobów informacyjnych oraz bezpieczeństwa.
Szczególnie drugie z wymienionych zagadnień jest istotne w aspekcie rozwoju aplikacji rozproszonych. W obrębie wspomnianej już Javy zdefiniowane zostały mechanizmy uwierzytelniania. Co szczególnie istotne, specyfikacja mechanizmów bezpieczeństwa została zawarta w obrębie samego języka. Z jednej strony jest to zaletą, gdyż zapewnia kompatybilność pomiędzy różnymi implementacjami. Z drugiej jednak strony programiści tworzący aplikacja są ograniczeni poprzez rozwiązania zawarte w standardzie. Ponieważ trudno wyobrazić sobie rozproszony system informacyjny, zawierający uwierzytelnione komponenty pochodzące od różnych producentów działający w skali internetu, dlatego bardziej słuszne byłoby opracowanie standardu nie na poziomie języka lecz językowo neutralnej specyfikacji. Jak pokazano w pracy właściwe wyodrębnienie cech operacyjnych komponentu (w tym przypadku mobilności) umożliwia zastąpienie utajniania (szyfrowania) przez uwierzytelnienie.
Rozszerzanie funkcjonalności komponentów w postaci binarnej powinno być raczej oparte na szczegółowej analizie mechanizmów oferowanych przez protokoły obiektowe. Polegają one przede wszystkim na tworzeniu własnych implementacji standardowych interfejsów. Ich wykorzystanie jest wyzwaniem natury bardziej technicznej niż technologicznej. Wynika to ze stopnia złożoności samego protokołu, skomplikowania realizowanych funkcji oraz ewolucyjnego sposobu dochodzenia do standardu protokołu. Z tego właśnie powodu, przedstawienie metody symulacji przekazania parametru przez wartość osadzone zostało w szerszym kontekście technik modyfikujących własności obiektów binarnych. Do takich należą m.in. architektury agentowe oraz komponentowe.
W ramach prezentacji technik rozszerzania funkcjonalności komponentów, dokonanej w kontekście architektur oprogramowania, pokazano zarówno oryginalne propozycje oraz pochodzące od innych autorów starając się usystematyzować całość problematyk ujmując w możliwe systematyczny sposób wielość rozwiązań cząstkowych. Jedną ze słabości protokołu obiektowego DCOM jest brak syntetycznego, metodycznego ujęcia bardziej zaawansowanych technik programowania. Wynika to niewątpliwie z ewolucyjnej drogi, jaką ten protokół ma za sobą. Kreatywne, oryginalne rozwiązania w ramach DCOM są na ogół proste pod względem koncepcyjnym. Stwarzają jednak pewne trudności techniczne – co jest wynikiem braku wspomnianego całościowego ujęcia. Dlatego też, jednym z celów pracy było zaprezentowanie metod
133

dochodzenia do optymalnych rozwiązań poprzez próbę systematycznego zaprezentowania dostępnych technik oraz własności protokołu DCOM.
8.3. Obecny stan techniki (nowe standardy)
Ponieważ obszar zagadnień związanych z architekturami aplikacji i protokołami komunikacyjnymi należy do szczególnie intensywnie badanych i szybko rozwijających się, zostaną teraz zaprezentowane nowe rozwiązania, które pojawiły się trakcie prac nad niniejszą rozprawą. Omówione zostaną krótko standardy w pewien sposób komplementarne lub alternatywne do zaproponowanych tutaj, a mianowicie
- JDOM (Java Document Model) interfejs obiektowy dokumentów w języku JAVA,
- MAF (Mobile Agent Facility) obsługa mobilnych agentów w CORBA, - SOAP – „dokumentowy” interfejs dostępu do obiektów,- JR –refleksja w języku JAVA.
JDOM powstał jako programistyczny interfejs służący do przetwarzania dokumentów XML w języku JAVA. Struktura interfejsu została pomyślana ze szczególnym uwzględnieniem możliwości tego języka.
JDOM współpracuje z istniejącymi standardami takimi jak SAX oraz DOM. Zadaniem JDOM jest zintegrowanie obydwu standardów i optymalne wykorzystanie zalet każdego z nich. Różnice między modelem zdarzeniowym (SAX) a obiektowym DOM zostały przedstawione w rozdziale 4.
Dokument w JDOM jest reprezentowany przez obiekt klasy org.jdom.Document. Niemniej, specyfikacja nie wymaga by dokument był w całości dostępny w pamięci operacyjnej. Można zauważyć, że jest to efekt zbliżony to tego, który został osiągnięty dzięki zastosowaniu dynamicznego polimorfizmu w protokole DCOM. Sam sposób dostępu do składowych dokumentu przypomina nieco DOM znany z pakietu Office.
MAF Propozycja MAF (Mobile Agent Facility) jest próbą zdefiniowania rozszerzenia protokołu obiektowego CORBA w kierunku obsługi mobilności agentów. Twórcy MAF, OMG określa tą propozycję jako zestaw definicji oraz interfejsów niezbędnych do zapewniania komponentom mobilności (zdolności do migracji) oraz interoperacyjności. Dzięki tej ostatniej agent ma być zdolny do działania na różnych platformach systemowych wchodzących w skład systemu agentowego.
Inaczej niż w przypadku protokołu DCOM, gdzie jedna firma jest zarówno twórcą jego definicji jak i implementacji, OMG odpowiedzialne jest jedynie za specyfikację protokołu. Standardowa specyfikacja autorstwa OMG ma zapewnić zgodność
134

(kompatybilność) implementacji pochodzących od firm i organizacji wchodzących w skład OMG.
Podstawowymi składnikami specyfikacji MAF są interfejsy MAFAgentSystem oraz MAFFinder. Zadaniem tego pierwszego jest sterowanie cyklem życia agenta, na który składają się: jego utworzenie, uruchomienie, odbiór ze zdalnego węzła, wstrzymanie wykonania oraz zakończenie działania. Drugi z interfejsów odpowiedzialny jest za rejestrowanie typu agenta w systemie i usuwanie tego typu oraz za wyszukiwanie w systemie: agentów, systemów agentowych oraz węzłów składowych tego systemu.
JR Java reflection – jest to związany z językiem Java zbiór standardowych interfejsów obiektów, który ma zapewnić możliwość dynamicznego pozyskiwania wiedzy o ich strukturze. Zadaniami jakie ma realizować obiekt implementujący mechanizmy refleksji są:
- konstruowanie obiektów klas oraz tablic z nich złożonych,- umożliwienie dostępu do pól składowych,- umożliwienie dostępu do metod składowych,- dostęp do i możliwość modyfikowania elementów tablic.
Co szczególnie istotne, a na co dokument źródłowy specyfikacji nie zwraca explicite uwagi, wszystkie wymienione funkcje realizowane mają być bez konieczności deklarowania nowych typów obiektowych (klas). Jak wiadomo zadeklarowanie typu może odbyć się jedynie w trakcie tworzenie systemu, na poziomie kodu źródłowego. Refleksja natomiast jest mechanizmem „czasu wykonania” (run-time). Istotnym ograniczeniem refleksji jest ograniczenie jej jedynie do języka JAVA.
SOAP Simple Object Access Protocol – jest protokołem obsługującym wymianę informacji w rozproszonych i zdecentralizowanych środowiskach. Oparty jest on na języku XML i składa się z trzech części :
- koperty, która zawiera w sobie opis zawartości komunikatu,- zbioru reguł kodowania egzemplarzy obiektów klas oraz danych aplikacyjnych,- konwencji kodowania zdalnych wywołań procedur oraz zwracanych wartości.
Intencją twórców było stworzenie standardu możliwie ogólnego, który mógłby być później wykorzystany z całym szeregiem innych protokołów takich jak HTTP, DCOM, CORBA. Możliwość zakodowania wywołania protokołu obiektowego w postaci tekstu jest atrakcyjna z uwagi na pewien stopień komplikacji związanych z niskopoziomową obsługą tego protokołu. Komponent aplikacji musi mieć tylko możliwość utworzenia pliku tekstowego by korzystać z obiektów w ramach protokołu.
Ponieważ protokół umożliwia identyfikowanie obiektów, w kontekście których odbywa się wywołanie metody, rozwiązany zostaje tym samym problem utrzymywania
135

sesji w protokole HTTP. Identyfikator obiektu może być uważany za jej deskryptor. Podobnie jest w programowaniu obiektowym, egzemplarz klasy określa pewien „stan”, którego dotyczy wywołanie metody obiektu. Z uwagi na ogólny charakter specyfikacji SOAP, nie czyni ona żadnych ustaleń w stosunku do sposobu identyfikowania obiektów. Przykładowo, odpowiednia funkcja aplikacyjna może implementować odwzorowanie logicznej nazwy na fizyczny obiekt.
POST /StockQuote HTTP/1.1Host: www.stockquoteserver.comContent-Type: text/xml; charset="utf-8"Content-Length: nnnnSOAPAction: "Some-URI"
<SOAP-ENV:Envelopexmlns:SOAP-ENV="http://schemas.xmlsoap.org/soap/envelope/"SOAP-ENV:encodingStyle="http://schemas.xmlsoap.org/soap/encoding/"><SOAP-ENV:Body><m:GetLastTradePrice xmlns:m="Some-URI"><symbol>DIS</symbol></m:GetLastTradePrice></SOAP-ENV:Body></SOAP-ENV:Envelope>
8.1. Przykład kodowania SOAP
8.4. Planowane badania i implementacje
Plany związane z dalszymi badaniami dotyczą przede wszystkim kwestii związanych z izomorfizmem grafów. W pracach nad tym zagadnieniem coraz większe znaczenie zyskują metody algebraiczne [Fortin]. Dotyczy to zwłaszcza teorii grup. Fakt, że automorfizmy grafu tworzą grupę jest obiecującą możliwością tworzenia efektywnych algorytmów badania izomorfizmu grafów. Zbadania wymagają przede wszystkim własności nasyconej relacji równoważności opartej na liczbie fasetowej. W oczywisty sposób zachodzą oraz . Pytaniem jest czy prawdą jest również ? Pozytywne potwierdzenie miałoby istotne znaczenie dla algorytmu wyznaczania orbit grupy automorfizmów oraz klasy problemów GI-complete [Fortin].
Algorytm przedstawiony w rozdziale piątym może posłużyć również do analizy złożonych schematów organizacyjnych z licznymi relacjami wzajemnych powiązań. Analiza schematu może służyć do identyfikacji jednostek dublujących się. Może wykryć nadmiarowości, umożliwiając w ten sposób bardziej racjonalne wykorzystanie środków –np. redukcję zatrudnienia bez wpływu na realizację zadań.
136

Usprawnianie oraz optymalizowanie struktur, procesów produkcyjnych i biznesowych czy też racjonalizacja zatrudnienia jest obecnie jednym z najbardziej intensywnie rozwijających się działów teorii zarządzania. Metody reinżynierii procesów mogą znaleźć cenne wsparcie w postaci narzędzi do automatycznej analizy grafów pod kątem występowania w nim równoważnych wierzchołków. Z uwagi na ściśle techniczny charakter rozprawy, kwestie te były w niej jedynie wzmiankowane.
Wyniki o charakterze technicznym zostaną w dalszym ciągu wykorzystane w pracach implementacyjnych nad nowymi aplikacjami. W szczególności obejmować będą one:
- przenośną i refleksyjną implementację uproszczonego protokołu obiektowego Lightweight DCOM – ograniczonego tylko do interfejsu IDispatch,
- oparty na refleksji mechanizm dostępu do dokumentów XML (w szczególności projekt realizacji pełnego kompilatora DTD do TypeLib oraz stosownego interpretera realizujących opisane w rozdz. 4 tryby pracy obiektowego API),
- komponent EDI – pracujący w modelu zdarzeniowym komponent VCL/CLX służący do analizy oraz generowania dokumentów zgodnych z EDI.
137

Spis ilustracji1.1 Ewolucja architektur aplikacji.................................................................................................................61.2 Rozszerzona architektura wielowarstwowa – metody i techniki...........................................................121.3 Klasyfikacja metod komunikacji asynchronicznej................................................................................131.4 April (por. [Clark]) – przykład rozwiązania w Modelu Komunikatowym............................................141.5 DCOM (por. [Prosi2])– Rozwiązanie na poziomie systemowym.........................................................151.6 Przetwarzanie asynchroniczne na poziomie aplikacji – RAW..............................................................161.7 Migracja obiektu – architektura MAF...................................................................................................171.8 Migracja obiektu – architektura FIPA...................................................................................................181.9 Klasyfikacja trybów wywołania metody...............................................................................................211.10 Wyznaczanie relacji równoważności –identyfikacja komponentów...................................................242.1. Mechanizmy komunikacji sieciowej i rozwój architektur [Singer]......................................................262.2 Komunikacja w protokole DCOM [Gopalan].......................................................................................282.3 Obiekt DCOM (perspektywa interfejsu programisty)..........................................................................292.4 Składowe architektury OpenDCOM [Coulson].....................................................................................312.5. Implementacja FIPA i protokół DCOM por.[Sheremetov].................................................................362.6. Uzyskanie dostępu do obiektu DCOM identyfikowanego przez klucz z bazy SQL............................383.1. Implementacja obiektu synchronizującego...........................................................................................44(ICallback –interfejs dualny).......................................................................................................................443.2 Deklaracje serwera (tylko IDispatch)....................................................................................................443.3. Implementacja metody asynchronicznej...............................................................................................453.4. Wywołanie przekazujące obiekt synchronizujący................................................................................453.5. Deklaracja asynchronicznej klasy (IDL).............................................................................................483.6. Synchroniczne wywołanie metody obiektu klasy Provider.................................................................513.7. Asynchroniczne wywołanie metody obiektu klasy Provider...............................................................533.8. Dynamiczne uaktualnianie interfejsu użytkownika podczas przetwarzania zapytania skierowanego do
bazy danych.........................................................................................................................................534.1. Deklaracja interfejsu IMarshal [Platt].................................................................................................604.2. Metody wywoływane przez Posłuszny Przekaźnik por.[Box]..............................................................634.3. Posłuszny Przekaźnik..........................................................................................................................644.4. VCL –implementacja QueryInterface [Lisch].....................................................................................654.5. Ogólny schemat migracji opartej na rozdzieleniu stanu i klasy...........................................................674.6. Klasy realizujące MBV........................................................................................................................684.9. Poufność w systemie agentowym........................................................................................................734.10. Rozdzielona implementacja...............................................................................................................744.1 Interfejs informacji o typie....................................................................................................................804.2 Biblioteka typów (Type Library)...........................................................................................................814.3 Implementacja odwzorowania identyfikatorów....................................................................................874.4 Implementacja wywołania OA..............................................................................................................886.11 Algorytm wyznaczający reprezentantów klas równoważności względem postaci cyklicznej..........1046.40 Liczba fasetowa.................................................................................................................................1126.41 Wiszące wierzchołki..........................................................................................................................1137.1 Cykl powstawania zasobu informacyjnego.........................................................................................1167.2 Struktura pliku wykonywalnego MBR................................................................................................1197.5 Konwencjonalna architektura wielowarstwowa aplikacji bazodanowej [Pank][Ullman]...................1247.6 Rozszerzona architektura wielowarstwowa aplikacji bazodanowej....................................................1257.7 Monitoring w technologii intranet [Ivan]............................................................................................1287.8 Obiektowa reprezentacja węzłów........................................................................................................1297.9 Definicja biblioteki typów dla przykładowego węzła automatyki......................................................1308.1. Przykład kodowania SOAP................................................................................................................136
138

Literatura
[Ametas] AMETAS AMETAS, System mobiler, autonomer Softwareagenten Universität Frankfurt, 2000. "http://www.vsb.cs.uni-frankfurt.de/ametas/", last visited March, 2001
[Ban76] Banachowski L.,Kreczmar A. Elementy analizy algorytmów WNT Warszawa 1976
[Ban76a] Banachowski L.,Kreczmar A., Rytter W. Analiza algorytmów i struktur danych WNT Warszawa 1976
[Beauch] Beauchemin B. Nichtlineare daten mit OLE DB und ADO 2.5 System Journal 1(00) , Unterschleißheim 2000, 32-46
[Bernd] Berndtsson M. Active capability support for cooperation in cooperative information systems Ph.D. thesis University of Exeter 1998
[Bernstein] Bernstein P.A., Hadzilacos V., Goodman N. Concurrency Control and Recovery in Database Systems Addison-Wesley 1987
[Blair99] Blair G.S. et al. The Design of Resource Aware Reflective Middleware Architecture In: Proceedings of the 2nd International Conference on Meta-Level Architectures and Reflection St-Malo France , LNCS, Vol. 1616, Springer-Verlag, Berlin Heidelberg 1999, 115-134
[Blair00] Blair G.S. et al. Supporting dynamic QoS Management Functions in Reflective Middleware Platform In: IEEE Proceedings on Software Eingineering Vol. 147 No.1, 13-21
[Boo] Booch G.Object-Oriented Analysis and Design with Applications Redwood 1994
[Box] Box D. Marshalling By Value System Journal 4(99), Unterschleißheim 1999, 76-82
[Box1] Box D., Brown K. Ewald T.J., Sells C. Sieben Tips für bessere COM Programmierung System Journal 1(99), Unterschleißheim 1999, 64-75
[Brinch] Brinch-Hansen P. Podstawy Systemów Operacyjnych WNT, Warszawa 1979
[Brock] Brockschmidt K. Inside OLE Microsoft Press, Redmond 1995
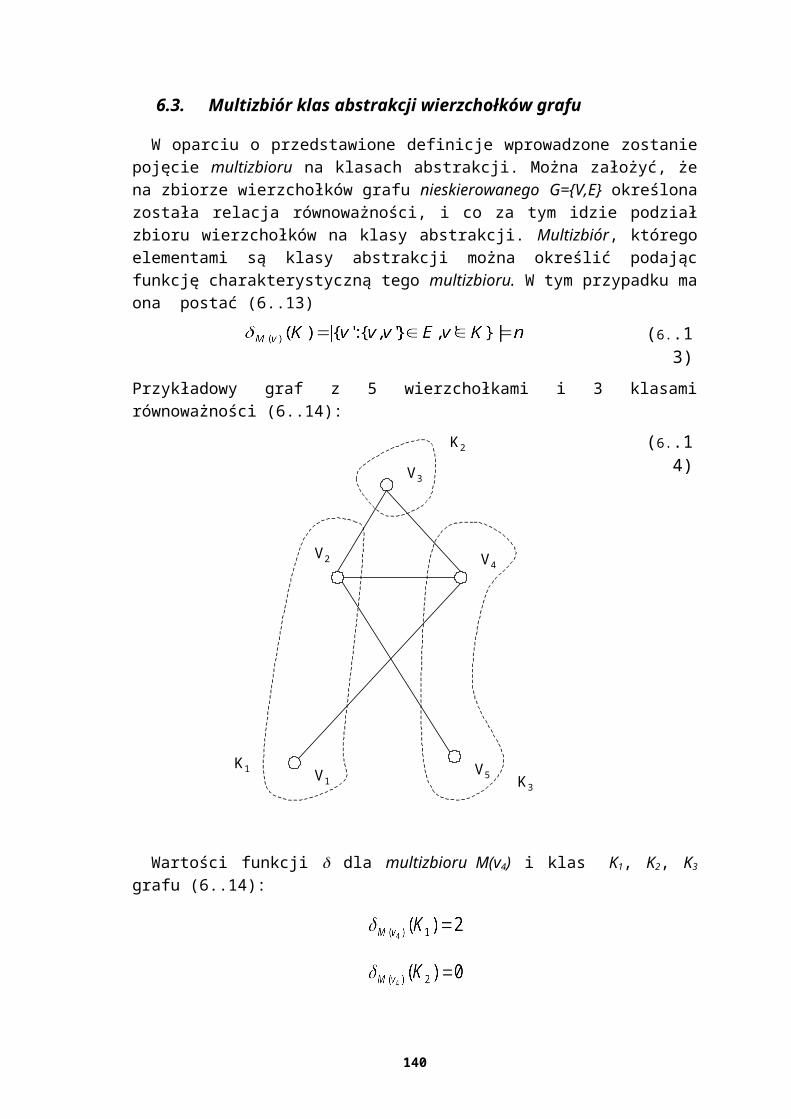
[Brodie] Brodie M.L.,Ceri S.On Intelligent and Cooperative Information Systems International Journal of Intelligent and Cooperative Information Systems 1(2) 1992
[Brown] Brown K. Der Universal Delegator System Journal 3(99), Unterschleißheim 1999, 104-110
[Cellary] Cellary W., Wieczerzycki W. Wielozadaniowy System Operacyjny Czasu Rzeczywistego iRMX 88 WNT, Warszawa 1988
[Clark] Clark K.L., Skarmeas N. A Harness Language for Cooperative Information Systems In: Cooperative Information Systems, Academic Press, San Diego 1998, 111-136
[Comer] Comer D.E. Sieci Komputerowe TCP/IP (tom 1) WNT, Warszawa 1997
[Coulson] Coulson G. et al. The Design of Configurable and Re-configurable Middleware Platform Distrib. Comput. (2002) 15: Springer-Verlag, Berlin Heidelberg 2002, 109-126
[Coulson99] Coulson G, A Configurable Multimedia Middleware Platform IEEE Multimedia, Vol. 6, No. 1 January-March 1999, 62-76
[CTR1] Web Commerce CTR 1999
[Dierks] Dierks T. , Allen C. The TLS Protocol : Certicom, 1999. "ftp://ftp.isi.edu/in-notes/rfc2246.txt", last visited June, 2001
[Edmo] Edmond D., Papazoglou M.P. Reflection is the essence of cooperation In: Cooperative Information Systems, Academic Press, San Diego 1998, 233-260
[Erik] Eriksson H.-E., Penker M. UML toolkit John Wiley & Sons 1998
[Face] Facey S. Virtuelle Unternehmen transparent steuern itFokus 4/01 itVerlag, Höhenkirchen 2001, 24-30
[Fey] Fey J.,Lobeck A. Weg von der Insel iFokus 4/01 itVerlag, Höhenkirchen 2001, 32-38
[FIPA] FIPA7412 Draft 1.0 Document of the Foundation for Intelligent Physical Agents 1998
[Flynn] Flynn X. Understanding SGML/XML Tools Kluwer Academic Press 1998
[Fortin] Fortin S. The Graph Isomorphism Problem Report 96-20, University of Alberta, Edmonton, Alberta, Canada.1996
140

[Galler] Galler B.A., Fischer M.J. An improved equivalence algorithm Comm. ACM, 1964/7, 301-303
[Gopalan] Gopalan S.R A Detailed Comparison of CORBA DCOM and Java/RMI (with specific code examples), http://www.execp.com/~gopalan/misc/compare.html
[Hall] Hall M . A Survey of Difference Sets Proc Amer Math Society 7/1956
[Hohl] Hohl F. A Protocol to Detect Malicious Hosts Attacks by Using Reference States Institut für Parallele und Verteilte Höchstleistungsrechner (IPVR), Fakultät Informatik, Universität Stuttgart, Stuttgart Bericht Nr. 1999/09, 1999
[Hopcroft] Hopcroft J.E. An nlogn Algorithm for Minimizing States in a Finite Automaton Theory of Machines and Computations, Academic Press 1971, 189-196
[Hubert] Hubert R. Kracke G. Implementierung verteilter Anwendungen: CORBA-Softwarebus macht Objekte mobil Datenbank Fokus (Objekt Fokus) 8/96 itVerlag, Höhenkirchen 1996, 13-20
[IBM] System Application Architecture, Common User Access, Advanced Interface Design Guide IBM June 1989
[Ivan] Ivanescu N., Brotac S. Supervising and Control of Industrial Processes Using Internet Technologies The 6th Workshop on Intelligent Manufacturing Systems IMS 2001 April 24-26, Poznań 2001 88-92
[Jacob] Jacobson I. et al.Object-Oriented Software Engineering Addison-Wesley 1992
[Jones97] Jones C. The Economics of Object Oriented Software April 14, 1997
http://dec.bournemouth.ac.uk/ESRG/downloads/Capers-strength.rtf
[Jones97a] Jones C. Strengths and weaknesses of software metrics July 29, 1997 http://dec.bournemouth.ac.uk/ESRG/downloads/Capers-strength.rtf
[Kash] Kashyap V.,Sheth A. Semantic Heterogenity in Global Information Systems: the Role of Metadata, Context and Ontologies In: Cooperative Information Systems, Academic Press, San Diego 1998, 139-178
[Kempe] Kempe M. DocAda the Hypertext Ada Reference Works KSCE 2000
141

[Kiczales] Kiczales G. Beyond the Black Box: Open Implementation IEEE Software, 13 ,1996, 8-11
[Knuth68] Knuth D.E. Art of Computer Programming 1/3 Addison Wesley 1968 (przekład rosyjski)
[Knuth99] Graham R., Knuth D.E., Patashnik O. Matematyka konkretna PWN, Warszawa 1998
[Konsta] Konstantas D. et al A Framework for Building Distributed Agent-Based Industrial Application The 6th Workshop on Intelligent Manufacturing Systems IMS 2001 April 24-26, Poznań 2001 106-111
[Kurat] Kuratowski K., Mostowski A. Teoria mnogości PWN, Warszawa 1966
[Lidl] Lidl R. Algebra dla przyrodników i inżynierów PWN, Warszawa 1983
[Lipski] Lipski W. Kombinatoryka dla programistów WNT, Warszawa 1989
[Lisch] Lischner R. Hidden Paths of Delphi3: Experts, Wizards and Open Tools API Informant Press, Elk Grove 1997
[Maes] Maes P. Computional Reflection The Knowledge Engineering Review , 3(1), 1-19
[MAF] Open Management Group (OMG) Mobile Agent System Interoperability Facilities (MASIF), OMG TC Document ORBOS/97-1-05, 1997
[Mann] Mann H.B Analysis and Design of Experiment New York 1949
[Manola] Manola F. et al. Supporting Cooperation in Enterprise Scale Distributed Object Systems In: Cooperative Information Systems, Academic Press, San Diego 1998, 81-110
[Mole] Mole Mole: Universität Stuttgart, 2000. http://mole.informatik.uni-stuttgart.de/, last visited March, 2001
[Muel] Müller J.P. The Design of Intelligent Agents LNAI Vol. 1177 Springer-Verlag, Berlin Heidelberg 1996
[Nierstrasz] Meiler T.D, Nierstrasz O. Beyond objects: Components In: Cooperative Information Systems, Academic Press, San Diego1998, 49-78
142

[Nierstrasz95] Nierstrasz O., Dami L. Object Oriented Software Composition Object Oriented Software Composition, O.Nierstrasz and D.Tsichritzis (Eds.) Prentice Hall 1995, 3-28
[Ovum] Ovum Evaluates: Object Request Brokers August 1997
[Papaz] Papazoglou M.P., Schlageter G. Themes in Cooperative Information Systems Research In: Cooperative Information Systems, Academic Press, San Diego 1998, 3-11
[Pattison] Pattison T. Integrate MSMQ into Your Distributed Applications
Microsoft System Journal 5(98), Microsoft Press, 1998
[Pietrek] Pietrek M. Generieren Sie Symbole aus COM-Typbibliotheken System Journal 4(99), Unterschleißheim 1997, 20-31
[Pintado] Pintado X. The Affinity Browser Object Oriented Software Composition O.Nierstrasz and D.Tsichritzis (Eds.) Prentice Hall 1995, 245-272
[Platt] Platt D.The Essence of OLE with ActiveX Prentice Hall 1997
[Platt97] Platt D. Das Free-Threading Modell System Journal 6(97), Unterschleißheim 1997, 56-67
[Prosise1] Prosise J. So implementieren Sie asynchrone COM-Ausrufe System Journal 1(00), Unterschleißheim 2000, 66-73
[Prosise2] Prosise J. So setzen Sie asynchroneMethodenausrufe ein System Journal 4(00), Unterschleißheim 2000, 78-85
[Rasi] Rasiowa H. Wstęp do matematyki współczesnej PWN, Warszawa 1984
[Reed] Reed D.,Trewin T.,Tomsen M.-J. Der Microsoft Transaction Server System Journal 6(97), Unterschleißheim 1997, 24-40
[Rogerson] Rogerson D. Inside COM Microsoft Press, Redmond 1997
[Rohs] Rohse F. Web Content Management ausgelagert itFokus 4/01 itVerlag, Höhenkirchen 2001, 66-69
[RougeWave] Thomas Keffer Tools.h++ , Foundation Class Library for C++ Programming, Introduction and Reference Manual, Rouge Wave, Cornvallis 1994
[Rumb] Rumbaugh J. et. al. Object-Oriented Modeling and Design Prentice Hall 1991
143

[Rusin] Rusinkewicz M. et al. Towards a Cooperative Transaction Model – The Cooperative Activity Model Proceedings of the 21th VLDB Conf. Zurich 1995
[Sacz] Saczkow W.N. Kombinatoryczne metody matematyki dyskretnej. Wyd. “Nauka” Moskwa 1977 (rosyjski)
[Scheb] Scheb A.Software Agenten für verteilte Systeme- Eine neue Ära beginnt itFokus 6/00 itVerlag, Höhenkirchen 2000, 42-59
[Schmidt] Schmidt D.C.,Cleeland C. Applying Patterns to Develop Extensible ORB Middleware IEEE Communication Magazine Special Issue on Design Patterns, April 1999
[Sheremetov] Sheremetov L.B, Contreras M. Component Agent Platform Proceedings of CEEMAS’01 , Poland, Kraków 26-29 September 2001, 395-402
[Show] Show A.C. Projektowanie Logiczne Systemów Operacyjnych WNT Warszawa 1980
[Sikor00] Sikorski A. Kombinatoryczne Dowody Uogólnionych Twierdzeń z Grupy MacMahona PP Studium Doktoranckie Poznań 2000
[Sikor00a] Sikorski A. Symulacja Wywołania Asynchronicznego w Protokołach Obiektowych Systemy Czasu Rzeczywistego, Kraków 2000
[Sikor02] Sikorski A. Agenci mobilni w protokole DCOM Systemy Czasu Rzeczywistego, Ustroń 2002
[Sikor02a] Sikorski A. Techniki implementacji agentów mobilnych CODATA Poznań 2002 ( w druku)
[Sikor97] Sikorski A. Optymalna struktura danych dla operacji member Systemy Czasu Rzeczywistego Szklarska Poręba 1997
[Sikor99] Begier B. Sikorski A. Modelowanie obiektów aplikacji w środowisku projektowym Sybase ProDialog 9/99 NAKOM Poznań 1999
[Sikor99a] Cybulka J. Sikorski A. Przetwarzanie transakcji w bezpołączeniowych protokołach komunikacyjnych ProDialog 9/99 NAKOM Poznań 1999
[Singer] Singer C. Middleware in verteilten Systemen ItFokus 12/01 itVerlag, Höhenkirchen 2001, 14-23
[Stal] Stal M. World Wide CORBA – verteilte Objekte im Netz ObjektSpektrum 11-12(97), München 1997, 28-34
[Stev] Stevens W.R. Unix Network Programming Prentice Hall 1990
144

[Stroud] Stroud R., Wu Z. Using Metaobject Protocols to Implement Atomic Data Types ECOOP’95, 9th European Conference on Object-Oriented Programming, LNCS Vol. 952, Springer-Verlag, Berlin Heidelberg 1995
[Stroustr] Stroustrup B. The C++ Programming Language Addison-Wesley 1997
[Subieta1] Subieta K. Słownik często spotykanych terminów dotyczących obiektowości, IPI PAN, Raport 839, Warszawa 1997
[Subieta2] Subieta K. Rozproszone obiektowe bazy danych, IPI PAN, Raport 857, Warszawa 1998
[Szyperski] Szyperski C. Component Software: Beyond Object-Oriented Programming Addison-Wesley 1998
[Tari] Edmond D., Papazoglou M.P., Tari Z.(1995) ROK: a Reflective Model for Distributed Object Management In RIDE-DOM (Research Issues in Data Engineering – Distributed Object Management), M. Tamer Özsu, O. Bukres, M-C. Shan (eds.). Taiwan, IEE-CS Press, 31-41
[Tom] Tomiczek T. Entwicklung mit Advanced Data Objects (ADO) System Journal 2(99), Unterschleißheim 1999, 94-96
[Tanen] Tanenbaum A.S. Computer Networks Prentice Hall 1990
[Ullman] Ullman J.D. Information Integration Using Logical Views ICDT 97
[Warren] Warren D.H.D An Abstract Prolog Instruction Set Technical Note 309, SRI International Menlo Park, CA October 1983
[Wats] Watson B. Taxonomy of Finite Automata Minimization Algorithms Duke University Press 1997
[Weng] Wengorz J., Säuberlich F. Erfolgskontrolle von E-Commerce-Auftritten ItFokus 4/01 itVerlag, Höhenkirchen 2001, 60-65
[Will99] Willers M. Marshaling auf der Basis von Typbibliotheken System Journal 6(99), Unterschleißheim 1999, 85-87
[Wood] Wood A. "Towards a Medium for Agent-Based Interaction", In School of Computer Science. Birmingham: University of Birmingham, 1994, 29-35
[Zimm] Zimmer J.A. Abstraction for Programmers McGraw-Hill 1985
[ZimmS] Zimmermann S. Das Konzept der Snaps-Ins System Journal 6(97), Unterschleißheim 1997, 76-90
145

[Zygmunt] Zygmunt M. Formalna specyfikacja agentów powielania danych Rozprawa doktorska, AGH, Kraków 1999
146
![Paweł Kurzawa, Delfina Kongo - math.uni.lodz.plmath.uni.lodz.pl/~kowalcr/Bazy/Temat5.pdf · pojęciem dla obiektowości. W pracy [Subieta 1999a] obiekt jest definiowany jako abstrakcyjny](https://static.fdocuments.pl/doc/165x107/5c79633209d3f2990f8c3a1d/pawel-kurzawa-delfina-kongo-mathunilodz-kowalcrbazytemat5pdf-pojeciem.jpg)


![2. Zastosowanie technik GIS w geotechnice 2.pdf · – wg [Subieta, 1998, 1999], [Ga ździcki, 2001] W geomatyce obiekt jest wyst ąpieniem klasy i jest oparty na paradygmacie obiektowo](https://static.fdocuments.pl/doc/165x107/5c79633209d3f2990f8c3a08/2-zastosowanie-technik-gis-w-2pdf-wg-subieta-1998-1999-ga-zdzicki.jpg)